From Tarzan to Tolkien: Controlling the Language Proficiency Level of LLMs for Content Generation
2406.03030
0
0

Abstract
We study the problem of controlling the difficulty level of text generated by Large Language Models (LLMs) for contexts where end-users are not fully proficient, such as language learners. Using a novel framework, we evaluate the effectiveness of several key approaches for this task, including few-shot prompting, supervised finetuning, and reinforcement learning (RL), utilising both GPT-4 and open source alternatives like LLama2-7B and Mistral-7B. Our findings reveal a large performance gap between GPT-4 and the open source models when using prompt-based strategies. However, we show how to bridge this gap with a careful combination of finetuning and RL alignment. Our best model, CALM (CEFR-Aligned Language Model), surpasses the performance of GPT-4 and other strategies, at only a fraction of the cost. We further validate the quality of our results through a small-scale human study.
Create account to get full access
Overview
- This paper explores techniques for controlling the language proficiency level of large language models (LLMs) to generate content at a desired reading level.
- The authors investigate prompting strategies and architectural modifications to enable LLMs to produce text that aligns with specific target proficiency levels, from elementary to advanced.
- The research aims to improve the accessibility and usability of LLM-generated content, making it suitable for a range of audiences, from young readers to subject-matter experts.
Plain English Explanation
The paper looks at ways to adjust the language skills of powerful AI language models so they can generate content that matches the reading level of the intended audience. These models are very capable and can write on almost any topic, but the language they use is often complex and difficult for some people to understand.
The researchers tested different prompting techniques and model changes to get the AI to produce text that is simpler and more accessible for less proficient readers, as well as more advanced content for expert audiences. This could be useful for creating educational materials, news articles, or other information that needs to be tailored to different skill levels.
For example, the model might be able to write a children's book using simple vocabulary and sentence structure, and then create a more technical version of the same content for university students. By controlling the language proficiency, the AI can make its generated text more usable for a wider range of people.
Technical Explanation
The paper explores methods for controlling the language proficiency level of LLMs for content generation, building on prior research into prompting techniques for large language models and language model-based text generation.
The authors investigate two approaches: prompt-based control and architectural modifications. For prompt-based control, they experiment with various prompting strategies to guide the LLM towards a target proficiency level. This includes using prompts that explicitly specify the desired reading level, as well as prompts that adjust the complexity of the content through lexical and syntactic choices.
The architectural modification approach involves fine-tuning the LLM on corpora aligned with different proficiency levels, as well as incorporating specialized modules that can adjust the language complexity of the generated output. The authors evaluate these techniques on both intrinsic and extrinsic metrics, assessing the models' ability to generate text at a specified reading level while maintaining coherence and fluency.
Critical Analysis
The paper presents a novel and valuable approach to improving the accessibility of LLM-generated content. By enabling LLMs to produce text at a target proficiency level, the research addresses an important challenge in making these powerful language models more usable for a wider range of applications and audiences.
However, the paper does not fully explore the potential limitations and unintended consequences of this technology. For instance, there may be concerns around the ethical implications of AI-generated content that is optimized for specific reading levels, particularly in the context of educational or informational materials. There is also the risk of oversimplification or loss of nuance when content is tailored to lower proficiency levels.
Additionally, the evaluation metrics used in the paper, while relevant, may not capture all the important aspects of language proficiency, such as the ability to convey complex ideas or maintain a consistent tone and voice. Further research is needed to explore the long-term impacts and potential misuses of this technology.
Conclusion
This paper introduces an innovative approach to controlling the language proficiency level of LLMs, which could have significant implications for the development of more accessible and adaptable AI-generated content. By empowering LLMs to produce text that aligns with the reading skills of the target audience, the research has the potential to improve the usability and impact of these powerful language models across a wide range of domains, from education to journalism to creative writing.
However, the technology also raises important ethical considerations that warrant further investigation and discussion. As LLMs become more widely adopted, it will be crucial to carefully examine the potential risks and unintended consequences of such capabilities, ensuring that they are developed and deployed in a responsible and equitable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Vernacular? I Barely Know Her: Challenges with Style Control and Stereotyping
Ankit Aich, Tingting Liu, Salvatore Giorgi, Kelsey Isman, Lyle Ungar, Brenda Curtis
0
0
Large Language Models (LLMs) are increasingly being used in educational and learning applications. Research has demonstrated that controlling for style, to fit the needs of the learner, fosters increased understanding, promotes inclusion, and helps with knowledge distillation. To understand the capabilities and limitations of contemporary LLMs in style control, we evaluated five state-of-the-art models: GPT-3.5, GPT-4, GPT-4o, Llama-3, and Mistral-instruct- 7B across two style control tasks. We observed significant inconsistencies in the first task, with model performances averaging between 5th and 8th grade reading levels for tasks intended for first-graders, and standard deviations up to 27.6. For our second task, we observed a statistically significant improvement in performance from 0.02 to 0.26. However, we find that even without stereotypes in reference texts, LLMs often generated culturally insensitive content during their tasks. We provide a thorough analysis and discussion of the results.
6/19/2024
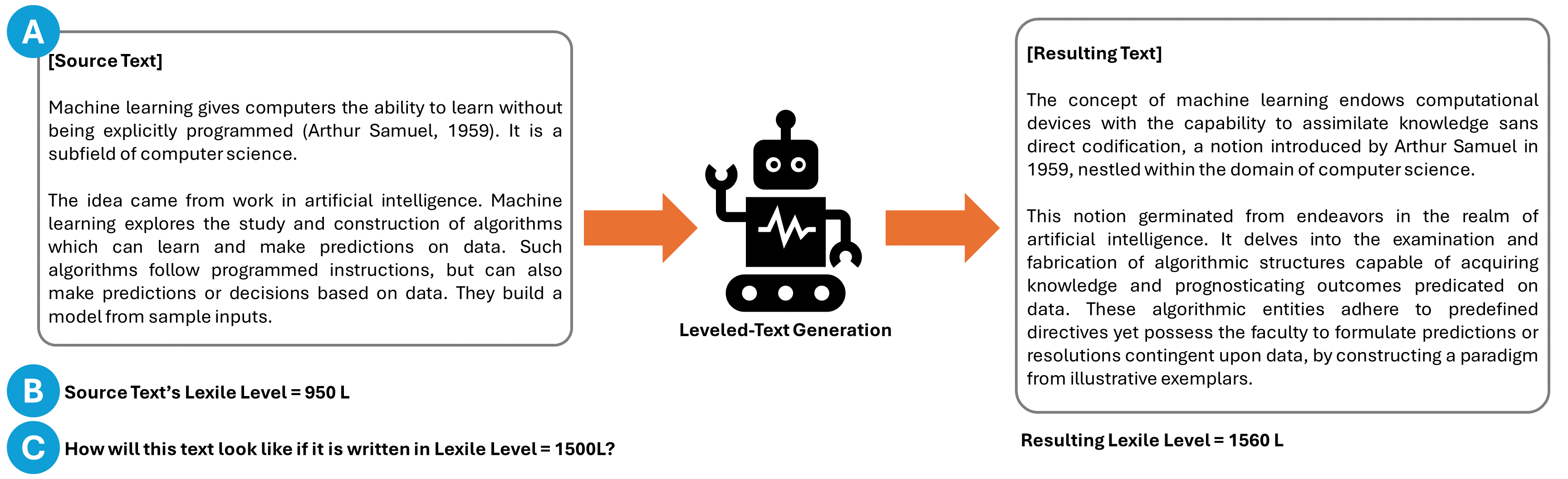
Generating Educational Materials with Different Levels of Readability using LLMs
Chieh-Yang Huang, Jing Wei, Ting-Hao 'Kenneth' Huang
0
0
This study introduces the leveled-text generation task, aiming to rewrite educational materials to specific readability levels while preserving meaning. We assess the capability of GPT-3.5, LLaMA-2 70B, and Mixtral 8x7B, to generate content at various readability levels through zero-shot and few-shot prompting. Evaluating 100 processed educational materials reveals that few-shot prompting significantly improves performance in readability manipulation and information preservation. LLaMA-2 70B performs better in achieving the desired difficulty range, while GPT-3.5 maintains original meaning. However, manual inspection highlights concerns such as misinformation introduction and inconsistent edit distribution. These findings emphasize the need for further research to ensure the quality of generated educational content.
6/19/2024

Multi-Objective Linguistic Control of Large Language Models
Dang Nguyen, Jiuhai Chen, Tianyi Zhou
0
0
Large language models (LLMs), despite their breakthroughs on many challenging benchmark tasks, lean to generate verbose responses and lack the controllability of output complexity, which is usually preferred by human users in practice. In this paper, we study how to precisely control multiple linguistic complexities of LLM output by finetuning using off-the-shelf data. To this end, we propose multi-control tuning (MCTune), which includes multiple linguistic complexity values of ground-truth responses as controls in the input for instruction tuning. We finetune LLaMA2-7B on Alpaca-GPT4 and WizardLM datasets. Evaluations on widely used benchmarks demonstrate that our method does not only improve LLMs' multi-complexity controllability substantially but also retains or even enhances the quality of the responses as a side benefit.
6/26/2024

New!Understanding and Mitigating Language Confusion in LLMs
Kelly Marchisio, Wei-Yin Ko, Alexandre B'erard, Th'eo Dehaze, Sebastian Ruder
0
0
We investigate a surprising limitation of LLMs: their inability to consistently generate text in a user's desired language. We create the Language Confusion Benchmark (LCB) to evaluate such failures, covering 15 typologically diverse languages with existing and newly-created English and multilingual prompts. We evaluate a range of LLMs on monolingual and cross-lingual generation reflecting practical use cases, finding that Llama Instruct and Mistral models exhibit high degrees of language confusion and even the strongest models fail to consistently respond in the correct language. We observe that base and English-centric instruct models are more prone to language confusion, which is aggravated by complex prompts and high sampling temperatures. We find that language confusion can be partially mitigated via few-shot prompting, multilingual SFT and preference tuning. We release our language confusion benchmark, which serves as a first layer of efficient, scalable multilingual evaluation at https://github.com/for-ai/language-confusion.
7/1/2024