Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
2308.10410
0
0
💬
Abstract
Educational materials such as survey articles in specialized fields like computer science traditionally require tremendous expert inputs and are therefore expensive to create and update. Recently, Large Language Models (LLMs) have achieved significant success across various general tasks. However, their effectiveness and limitations in the education domain are yet to be fully explored. In this work, we examine the proficiency of LLMs in generating succinct survey articles specific to the niche field of NLP in computer science, focusing on a curated list of 99 topics. Automated benchmarks reveal that GPT-4 surpasses its predecessors, inluding GPT-3.5, PaLM2, and LLaMa2 by margins ranging from 2% to 20% in comparison to the established ground truth. We compare both human and GPT-based evaluation scores and provide in-depth analysis. While our findings suggest that GPT-created surveys are more contemporary and accessible than human-authored ones, certain limitations were observed. Notably, GPT-4, despite often delivering outstanding content, occasionally exhibited lapses like missing details or factual errors. At last, we compared the rating behavior between humans and GPT-4 and found systematic bias in using GPT evaluation.
Create account to get full access
Overview
- This research paper examines the ability of large language models (LLMs) to generate high-quality, concise survey articles on specific topics in the field of natural language processing (NLP) and computer science.
- The researchers evaluated the performance of various LLMs, including GPT-4, GPT-3.5, PaLM2, and LLaMa2, on a curated list of 99 NLP topics.
- Automated benchmarks showed that GPT-4 outperformed its predecessors by 2% to 20% in comparison to established ground truth.
- The study compared both human and GPT-based evaluation scores, providing an in-depth analysis of the strengths and limitations of LLMs in this domain.
Plain English Explanation
Creating educational materials, such as survey articles in specialized fields like computer science, can be a challenging and costly process, as it typically requires substantial expert input. However, the recent advancements in large language models (LLMs) have opened up new possibilities for generating these types of educational resources more efficiently.
In this study, the researchers explored the effectiveness of LLMs, specifically focusing on their ability to generate concise survey articles on a curated list of 99 topics within the niche field of natural language processing (NLP) and computer science. They compared the performance of several LLMs, including GPT-4, GPT-3.5, PaLM2, and LLaMa2, using automated benchmarks.
The results revealed that GPT-4 outperformed its predecessors by a significant margin, ranging from 2% to 20% in comparison to the established ground truth. This suggests that the latest generation of LLMs, such as GPT-4, can potentially be utilized to create more contemporary and accessible educational materials than traditional human-authored ones.
However, the researchers also identified some limitations in the LLMs' performance. While GPT-4 often delivered outstanding content, it occasionally exhibited lapses, such as missing details or factual errors. Additionally, the researchers observed systematic biases in the way humans and GPT-4 rated the generated survey articles, highlighting the need for further exploration and understanding of these differences.
Technical Explanation
The researchers in this study examined the ability of large language models (LLMs) to generate high-quality, concise survey articles on specific topics in the field of natural language processing (NLP) and computer science. They curated a list of 99 NLP topics and evaluated the performance of various LLMs, including GPT-4, GPT-3.5, PaLM2, and LLaMa2, on this task.
To assess the LLMs' performance, the researchers employed automated benchmarks that compared the generated survey articles to established ground truth. The results showed that GPT-4 consistently outperformed its predecessors, with margins ranging from 2% to 20% in comparison to the ground truth.
In addition to the automated evaluation, the researchers also compared human and GPT-based evaluation scores for the generated survey articles. This in-depth analysis provided insights into the strengths and limitations of LLMs in this domain. While the findings suggest that GPT-created surveys are more contemporary and accessible than human-authored ones, the researchers observed that GPT-4, despite often delivering outstanding content, occasionally exhibited lapses such as missing details or factual errors.
Furthermore, the study examined the rating behavior between humans and GPT-4, and found systematic biases in the way they evaluated the generated survey articles. This highlights the need for further exploration and understanding of the differences between human and LLM-based assessments, as it has implications for the deployment and interpretation of LLM-generated educational materials.
Critical Analysis
The research presented in this paper offers valuable insights into the potential of large language models (LLMs) in the education domain, specifically in generating concise survey articles on specialized topics. The researchers' approach of curating a comprehensive list of 99 NLP topics and systematically evaluating the performance of various LLMs, including the state-of-the-art GPT-4, provides a robust and rigorous assessment of the technology's capabilities.
One of the key strengths of this study is the comparative analysis between human and GPT-based evaluation scores. By identifying systematic biases in the rating behavior, the researchers have highlighted the need for further research to understand the nuances and limitations of LLM-generated educational content. This is crucial, as the adoption of LLMs in educational settings requires a deeper understanding of their strengths, weaknesses, and potential biases.
However, the study does not delve into the specific types of errors or lapses observed in the GPT-4-generated survey articles. A more detailed examination of the nature and causes of these issues could provide valuable insights for improving the quality and reliability of LLM-generated educational materials.
Additionally, the study focuses solely on the NLP domain within computer science. While this provides a useful case study, it would be beneficial to explore the performance of LLMs in generating survey articles across a broader range of academic disciplines to better understand the generalizability of the findings.
Conclusion
This research paper presents a comprehensive examination of the ability of large language models (LLMs) to generate high-quality, concise survey articles in the specialized field of natural language processing (NLP) and computer science. The study's findings suggest that the latest generation of LLMs, such as GPT-4, can outperform their predecessors in this task, potentially offering a more efficient and accessible approach to creating educational materials compared to traditional human-authored content.
However, the research also highlights the limitations and biases inherent in LLM-generated educational resources, emphasizing the need for continued exploration and understanding of these systems. As the adoption of LLMs in educational settings becomes more prevalent, it is crucial to address these challenges and ensure the reliable and unbiased deployment of these technologies.
Overall, this study contributes to the growing body of research on the applications of LLMs in specialized domains, and it provides valuable insights for educators, researchers, and policymakers interested in leveraging these powerful models to enhance the accessibility and quality of educational resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!A Large Language Model Approach to Educational Survey Feedback Analysis
Michael J. Parker, Caitlin Anderson, Claire Stone, YeaRim Oh
0
0
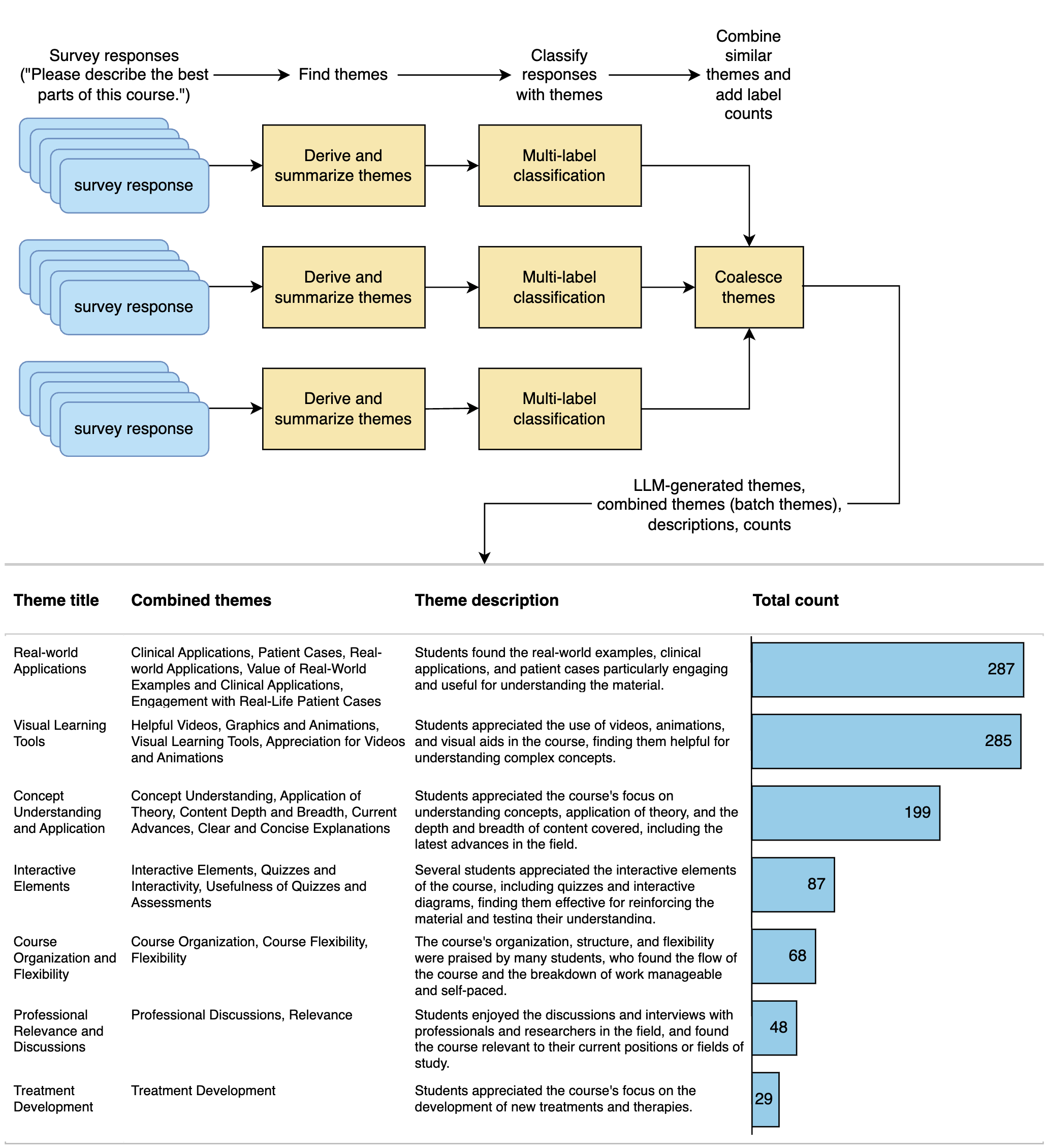
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
6/28/2024
💬
Can Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability to Mark Short Answer Questions in K-12 Education
Owen Henkel, Adam Boxer, Libby Hills, Bill Roberts
0
0
This paper presents reports on a series of experiments with a novel dataset evaluating how well Large Language Models (LLMs) can mark (i.e. grade) open text responses to short answer questions, Specifically, we explore how well different combinations of GPT version and prompt engineering strategies performed at marking real student answers to short answer across different domain areas (Science and History) and grade-levels (spanning ages 5-16) using a new, never-used-before dataset from Carousel, a quizzing platform. We found that GPT-4, with basic few-shot prompting performed well (Kappa, 0.70) and, importantly, very close to human-level performance (0.75). This research builds on prior findings that GPT-4 could reliably score short answer reading comprehension questions at a performance-level very close to that of expert human raters. The proximity to human-level performance, across a variety of subjects and grade levels suggests that LLMs could be a valuable tool for supporting low-stakes formative assessment tasks in K-12 education and has important implications for real-world education delivery.
5/7/2024

A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
Xuanfan Ni, Piji Li
0
0
Recent efforts have evaluated large language models (LLMs) in areas such as commonsense reasoning, mathematical reasoning, and code generation. However, to the best of our knowledge, no work has specifically investigated the performance of LLMs in natural language generation (NLG) tasks, a pivotal criterion for determining model excellence. Thus, this paper conducts a comprehensive evaluation of well-known and high-performing LLMs, namely ChatGPT, ChatGLM, T5-based models, LLaMA-based models, and Pythia-based models, in the context of NLG tasks. We select English and Chinese datasets encompassing Dialogue Generation and Text Summarization. Moreover, we propose a common evaluation setting that incorporates input templates and post-processing strategies. Our study reports both automatic results, accompanied by a detailed analysis.
5/17/2024
An Empirical Analysis on Large Language Models in Debate Evaluation
Xinyi Liu, Pinxin Liu, Hangfeng He
0
0
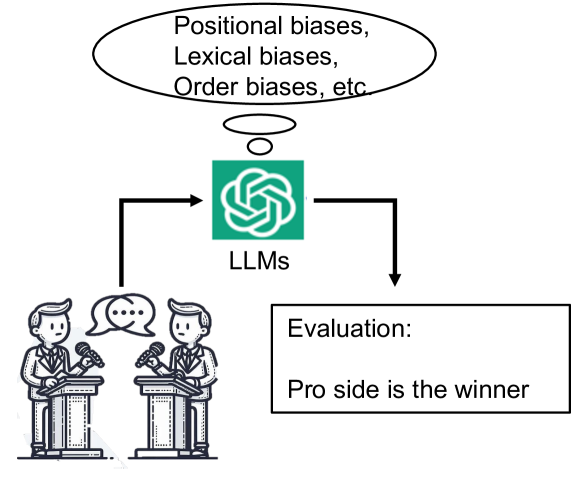
In this study, we investigate the capabilities and inherent biases of advanced large language models (LLMs) such as GPT-3.5 and GPT-4 in the context of debate evaluation. We discover that LLM's performance exceeds humans and surpasses the performance of state-of-the-art methods fine-tuned on extensive datasets in debate evaluation. We additionally explore and analyze biases present in LLMs, including positional bias, lexical bias, order bias, which may affect their evaluative judgments. Our findings reveal a consistent bias in both GPT-3.5 and GPT-4 towards the second candidate response presented, attributed to prompt design. We also uncover lexical biases in both GPT-3.5 and GPT-4, especially when label sets carry connotations such as numerical or sequential, highlighting the critical need for careful label verbalizer selection in prompt design. Additionally, our analysis indicates a tendency of both models to favor the debate's concluding side as the winner, suggesting an end-of-discussion bias.
6/5/2024