From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples
2404.07544
119
1
Abstract
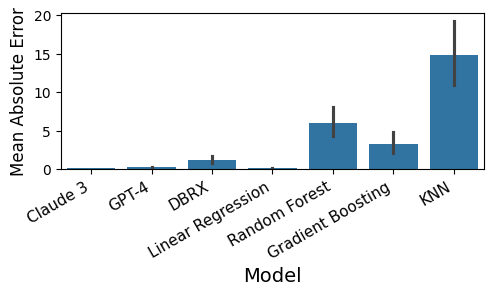
We analyze how well pre-trained large language models (e.g., Llama2, GPT-4, Claude 3, etc) can do linear and non-linear regression when given in-context examples, without any additional training or gradient updates. Our findings reveal that several large language models (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as Random Forest, Bagging, or Gradient Boosting. For example, on the challenging Friedman #2 regression dataset, Claude 3 outperforms many supervised methods such as AdaBoost, SVM, Random Forest, KNN, or Gradient Boosting. We then investigate how well the performance of large language models scales with the number of in-context exemplars. We borrow from the notion of regret from online learning and empirically show that LLMs are capable of obtaining a sub-linear regret.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the surprising capability of large language models (LLMs) to perform regression tasks when provided with in-context examples.
- The researchers show that LLMs can effectively convert text prompts into numerical outputs, demonstrating their potential as versatile regression models.
- The study highlights the untapped potential of LLMs beyond their traditional use in language tasks, opening new avenues for their application in various fields.
Plain English Explanation
Large language models (LLMs) like GPT-3 are known for their impressive abilities in tasks like text generation and language understanding. However, this paper reveals that these models have a hidden talent: they can also perform regression tasks, which involve converting text prompts into numerical outputs.
The researchers found that by providing LLMs with a few examples of text-to-number mapping, the models can learn to accurately predict numerical values for new text prompts. This is a surprising capability, as LLMs are primarily designed for language-based tasks, not numerical ones.
For example, if you show an LLM a few examples of how to convert text descriptions of objects (like "a small red apple") into their corresponding numerical attributes (like the object's size or color value), the model can then use this information to predict numerical values for new text descriptions it has never seen before.
This discovery unlocks new possibilities for how LLMs can be applied. Instead of just working with language, these models could be used to tackle a wide range of regression problems, where the goal is to map textual inputs to numerical outputs. This could be useful in fields like finance, science, and engineering, where there is a need to convert descriptive information into quantifiable data.
Technical Explanation
The researchers conducted experiments to assess the regression capabilities of large language models (LLMs) when provided with in-context examples. They used a variety of datasets, including image-text regression tasks, mathematical word problems, and natural language to numerical attribute mapping.
The researchers found that by presenting LLMs with a few examples of the desired text-to-number mapping, the models were able to learn to accurately predict numerical outputs for new, unseen text prompts. This capability was observed across multiple datasets and task types, suggesting that LLMs possess a general regression-learning ability that can be unlocked through in-context learning.
The paper also discusses the potential implications of this discovery, noting that it could lead to new applications of LLMs in fields that require converting descriptive information into quantitative data, such as finance or engineering. The researchers highlight the need for further research to understand the limits and generalization capabilities of this regression-learning phenomenon in LLMs.
Critical Analysis
The paper presents a compelling demonstration of the unexpected regression capabilities of large language models. However, it's important to note that the experiments were conducted on a limited set of datasets and tasks, and the researchers acknowledge the need for more extensive evaluation to fully understand the scope and limitations of this capability.
Additionally, the paper does not delve into the potential biases or systematic errors that may arise when using LLMs for regression tasks. As with any machine learning model, there is a risk of the model learning and perpetuating biases present in the training data, which could lead to inaccurate or undesirable outputs.
Further research is needed to explore the robustness and generalization of LLM regression performance, particularly when faced with more complex or ambiguous text inputs. The paper also does not address potential issues around the interpretability and explainability of the LLM's regression decision-making process, which could be important for applications in sensitive domains.
Overall, the paper presents an intriguing discovery that expands our understanding of the capabilities of large language models. However, more work is needed to fully assess the practical implications and potential pitfalls of using LLMs for regression tasks.
Conclusion
This paper uncovers a surprising capability of large language models (LLMs): their ability to effectively perform regression tasks when provided with in-context examples. The researchers demonstrate that LLMs can learn to convert textual prompts into numerical outputs, opening up new possibilities for their application beyond traditional language-based tasks.
The findings suggest that LLMs possess a general regression-learning ability that can be leveraged in a variety of domains, from finance and science to engineering and beyond. This discovery highlights the untapped potential of these powerful language models and encourages further exploration of their versatility in solving a wider range of real-world problems.
As the research in this area continues to evolve, it will be important to address the potential limitations and challenges associated with using LLMs for regression tasks, such as bias, interpretability, and generalization. Nevertheless, the insights presented in this paper mark an important step forward in understanding the capabilities and future applications of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Model Enhanced Machine Learning Estimators for Classification
Yuhang Wu, Yingfei Wang, Chu Wang, Zeyu Zheng
0
0
Pre-trained large language models (LLM) have emerged as a powerful tool for simulating various scenarios and generating output given specific instructions and multimodal input. In this work, we analyze the specific use of LLM to enhance a classical supervised machine learning method for classification problems. We propose a few approaches to integrate LLM into a classical machine learning estimator to further enhance the prediction performance. We examine the performance of the proposed approaches through both standard supervised learning binary classification tasks, and a transfer learning task where the test data observe distribution changes compared to the training data. Numerical experiments using four publicly available datasets are conducted and suggest that using LLM to enhance classical machine learning estimators can provide significant improvement on prediction performance.
5/10/2024

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024
Large Language Models for Mathematicians
Simon Frieder, Julius Berner, Philipp Petersen, Thomas Lukasiewicz
0
0
Large language models (LLMs) such as ChatGPT have received immense interest for their general-purpose language understanding and, in particular, their ability to generate high-quality text or computer code. For many professions, LLMs represent an invaluable tool that can speed up and improve the quality of work. In this note, we discuss to what extent they can aid professional mathematicians. We first provide a mathematical description of the transformer model used in all modern language models. Based on recent studies, we then outline best practices and potential issues and report on the mathematical abilities of language models. Finally, we shed light on the potential of LLMs to change how mathematicians work.
4/3/2024
💬
How good are Large Language Models on African Languages?
Jessica Ojo, Kelechi Ogueji, Pontus Stenetorp, David Ifeoluwa Adelani
0
0
Recent advancements in natural language processing have led to the proliferation of large language models (LLMs). These models have been shown to yield good performance, using in-context learning, even on tasks and languages they are not trained on. However, their performance on African languages is largely understudied relative to high-resource languages. We present an analysis of four popular large language models (mT0, Aya, LLaMa 2, and GPT-4) on six tasks (topic classification, sentiment classification, machine translation, summarization, question answering, and named entity recognition) across 60 African languages, spanning different language families and geographical regions. Our results suggest that all LLMs produce lower performance for African languages, and there is a large gap in performance compared to high-resource languages (such as English) for most tasks. We find that GPT-4 has an average to good performance on classification tasks, yet its performance on generative tasks such as machine translation and summarization is significantly lacking. Surprisingly, we find that mT0 had the best overall performance for cross-lingual QA, better than the state-of-the-art supervised model (i.e. fine-tuned mT5) and GPT-4 on African languages. Similarly, we find the recent Aya model to have comparable result to mT0 in almost all tasks except for topic classification where it outperform mT0. Overall, LLaMa 2 showed the worst performance, which we believe is due to its English and code-centric~(around 98%) pre-training corpus. Our findings confirms that performance on African languages continues to remain a hurdle for the current LLMs, underscoring the need for additional efforts to close this gap.
5/1/2024