Fully Test-Time Adaptation for Monocular 3D Object Detection
2405.19682
0
0

Abstract
Monocular 3D object detection (Mono 3Det) aims to identify 3D objects from a single RGB image. However, existing methods often assume training and test data follow the same distribution, which may not hold in real-world test scenarios. To address the out-of-distribution (OOD) problems, we explore a new adaptation paradigm for Mono 3Det, termed Fully Test-time Adaptation. It aims to adapt a well-trained model to unlabeled test data by handling potential data distribution shifts at test time without access to training data and test labels. However, applying this paradigm in Mono 3Det poses significant challenges due to OOD test data causing a remarkable decline in object detection scores. This decline conflicts with the pre-defined score thresholds of existing detection methods, leading to severe object omissions (i.e., rare positive detections and many false negatives). Consequently, the limited positive detection and plenty of noisy predictions cause test-time adaptation to fail in Mono 3Det. To handle this problem, we propose a novel Monocular Test-Time Adaptation (MonoTTA) method, based on two new strategies. 1) Reliability-driven adaptation: we empirically find that high-score objects are still reliable and the optimization of high-score objects can enhance confidence across all detections. Thus, we devise a self-adaptive strategy to identify reliable objects for model adaptation, which discovers potential objects and alleviates omissions. 2) Noise-guard adaptation: since high-score objects may be scarce, we develop a negative regularization term to exploit the numerous low-score objects via negative learning, preventing overfitting to noise and trivial solutions. Experimental results show that MonoTTA brings significant performance gains for Mono 3Det models in OOD test scenarios, approximately 190% gains by average on KITTI and 198% gains on nuScenes.
Create account to get full access
Overview
- This paper presents a novel approach for fully test-time adaptation of monocular 3D object detection models.
- The proposed method aims to improve the performance of these models by adapting them to the specific characteristics of the test environment, without requiring any additional annotations or fine-tuning during training.
- The method leverages the complementary strengths of two existing techniques - MonoTAKD and MonoDetRNext - to achieve this goal.
Plain English Explanation
Monocular 3D object detection is the task of identifying and locating objects in a 3D environment using a single camera. This is a challenging problem, as the 3D information needs to be inferred from a 2D image.
The authors of this paper have developed a new technique that can help these 3D object detection models perform better in real-world scenarios. Their approach involves "adapting" the model to the specific conditions of the test environment, without requiring any additional training or labeling of data.
The core idea is to leverage the complementary strengths of two existing techniques - MonoTAKD and MonoDetRNext. MonoTAKD helps the model learn from a "teacher" model, while MonoDetRNext improves the model's overall accuracy and efficiency.
By combining these two approaches, the researchers have created a method that can adapt the 3D object detection model to the unique characteristics of the test environment, without requiring any additional manual effort. This could lead to significant improvements in the real-world performance of these models, which is crucial for applications like autonomous vehicles and robotics.
Technical Explanation
The paper introduces a novel approach called "Fully Test-Time Adaptation for Monocular 3D Object Detection" (FTA-Mono3D). The key innovation is the ability to adapt the 3D object detection model to the test environment in a fully automated way, without requiring any additional annotations or fine-tuning during training.
The method works by leveraging two existing techniques: MonoTAKD and MonoDetRNext. MonoTAKD is a knowledge distillation approach that allows the model to learn from a more powerful "teacher" model, while MonoDetRNext is a high-performance monocular 3D object detection architecture.
The FTA-Mono3D method first trains the model using MonoDetRNext, which provides a strong baseline performance. It then applies MonoTAKD during the test-time adaptation phase, using the test images themselves as the "teacher" to guide the model's adaptation to the specific test environment.
The authors conduct extensive experiments on several benchmark datasets, demonstrating that FTA-Mono3D can significantly improve the 3D object detection performance compared to the baseline model and other state-of-the-art approaches, without requiring any additional annotations or fine-tuning.
Critical Analysis
The paper presents a compelling and well-designed approach to the challenge of improving monocular 3D object detection in real-world scenarios. The key strength of the FTA-Mono3D method is its ability to adapt the model to the test environment in a fully automated way, without requiring any additional human effort.
However, the paper does not discuss the potential limitations or drawbacks of the proposed approach. For example, it is unclear how the method would perform in cases where the test environment is drastically different from the training data, or if there are significant domain shifts between the training and test data.
Additionally, the paper does not provide a detailed analysis of the computational and memory requirements of the FTA-Mono3D method, which could be an important consideration for real-world deployment, especially in resource-constrained environments like autonomous vehicles.
Further research could also investigate the generalizability of the FTA-Mono3D approach to other 3D computer vision tasks, or explore the integration of additional adaptation techniques beyond MonoTAKD and MonoDetRNext to further enhance the model's performance.
Conclusion
This paper presents a novel and promising approach for fully test-time adaptation of monocular 3D object detection models. By leveraging the complementary strengths of MonoTAKD and MonoDetRNext, the FTA-Mono3D method can significantly improve the performance of these models in real-world scenarios, without requiring any additional annotations or fine-tuning during training.
The ability to adapt 3D object detection models to the unique characteristics of the test environment is a crucial capability for numerous applications, such as autonomous vehicles, robotics, and augmented reality. The FTA-Mono3D approach represents an important step forward in this direction, and could have a significant impact on the practical deployment of these technologies in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
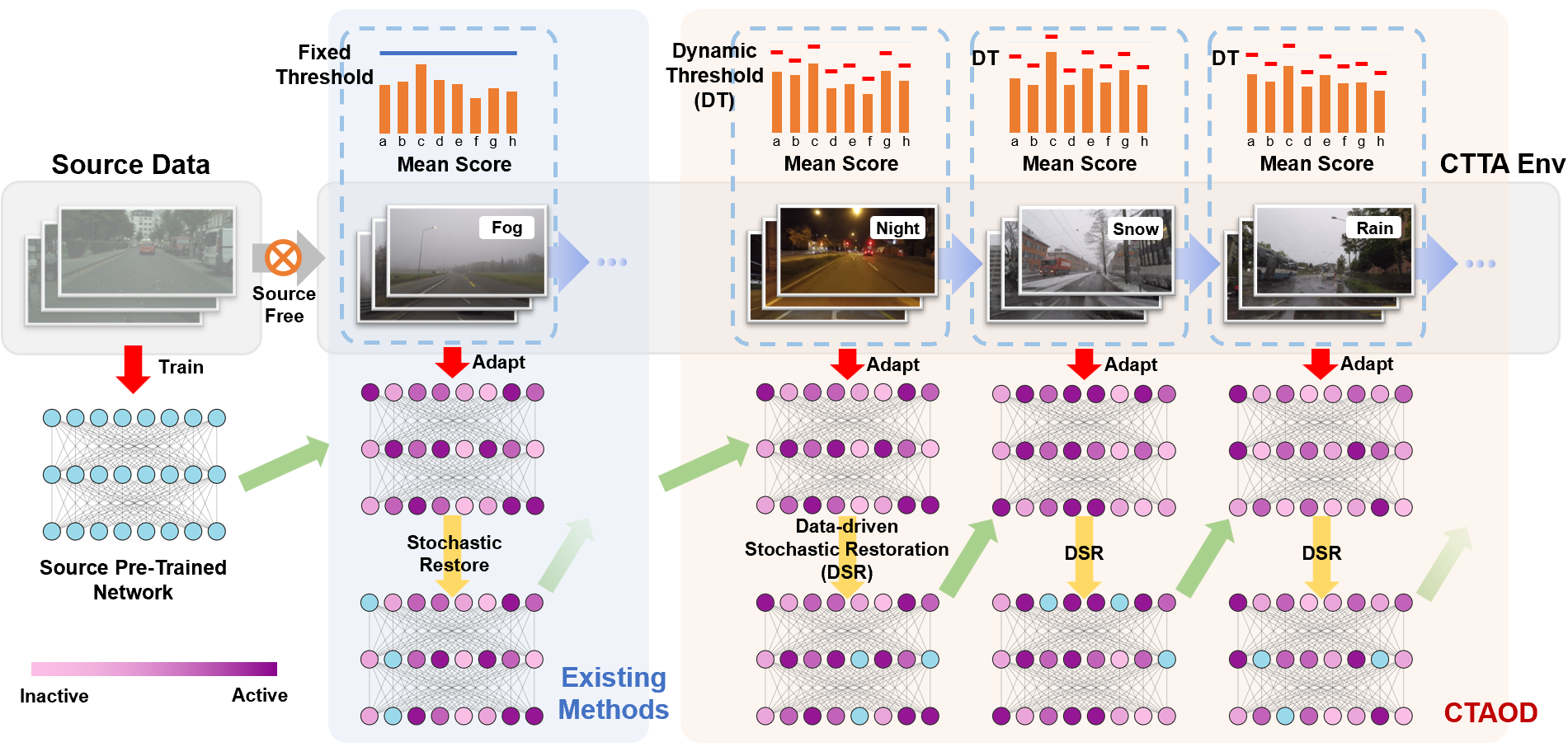
Exploring Test-Time Adaptation for Object Detection in Continually Changing Environments
Shilei Cao, Yan Liu, Juepeng Zheng, Weijia Li, Runmin Dong, Haohuan Fu
0
0
For real-world applications, neural network models are commonly deployed in dynamic environments, where the distribution of the target domain undergoes temporal changes. Continual Test-Time Adaptation (CTTA) has recently emerged as a promising technique to gradually adapt a source-trained model to test data drawn from a continually changing target domain. Despite recent advancements in addressing CTTA, two critical issues remain: 1) The use of a fixed threshold for pseudo-labeling in existing methodologies leads to the generation of low-quality pseudo-labels, as model confidence varies across categories and domains; 2) While current solutions utilize stochastic parameter restoration to mitigate catastrophic forgetting, their capacity to preserve critical information is undermined by its intrinsic randomness. To tackle these challenges, we present CTAOD, aiming to enhance the performance of detection models in CTTA scenarios. Inspired by prior CTTA works for effective adaptation, CTAOD is founded on the mean-teacher framework, characterized by three core components. Firstly, the object-level contrastive learning module tailored for object detection extracts object-level features using the teacher's region of interest features and optimizes them through contrastive learning. Secondly, the dynamic threshold strategy updates the category-specific threshold based on predicted confidence scores to improve the quality of pseudo-labels. Lastly, we design a data-driven stochastic restoration mechanism to selectively reset inactive parameters using the gradients as weights for a random mask matrix, thereby ensuring the retention of essential knowledge. We demonstrate the effectiveness of our approach on four CTTA tasks for object detection, where CTAOD outperforms existing methods, especially achieving a 3.0 mAP improvement on the Cityscapes-to-Cityscapes-C CTTA task.
6/26/2024
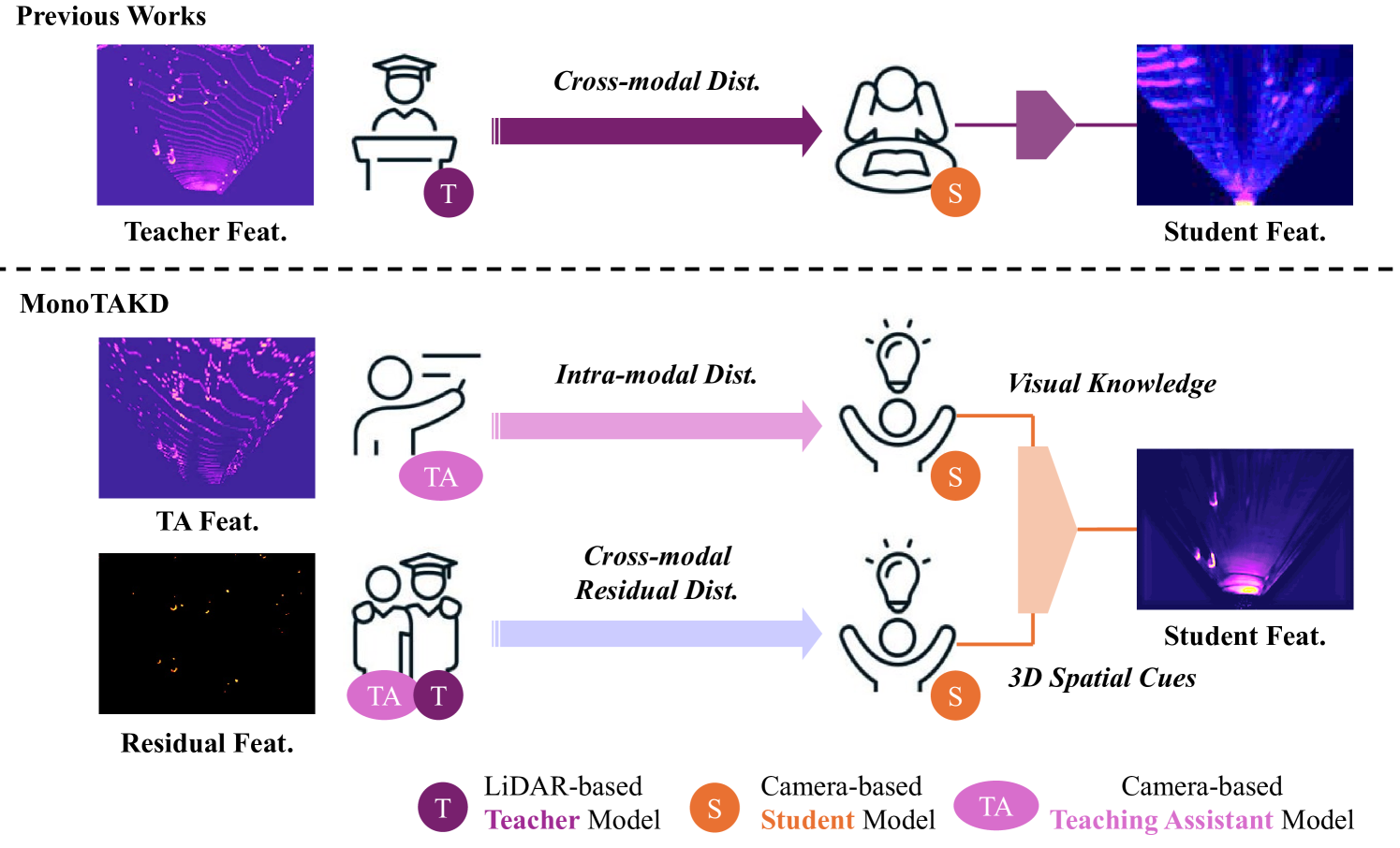
MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3D Object Detection
Hou-I Liu, Christine Wu, Jen-Hao Cheng, Wenhao Chai, Shian-Yun Wang, Gaowen Liu, Jenq-Neng Hwang, Hong-Han Shuai, Wen-Huang Cheng
0
0
Monocular 3D object detection (Mono3D) is an indispensable research topic in autonomous driving, thanks to the cost-effective monocular camera sensors and its wide range of applications. Since the image perspective has depth ambiguity, the challenges of Mono3D lie in understanding 3D scene geometry and reconstructing 3D object information from a single image. Previous methods attempted to transfer 3D information directly from the LiDAR-based teacher to the camera-based student. However, a considerable gap in feature representation makes direct cross-modal distillation inefficient, resulting in a significant performance deterioration between the LiDAR-based teacher and the camera-based student. To address this issue, we propose the Teaching Assistant Knowledge Distillation (MonoTAKD) to break down the learning objective by integrating intra-modal distillation with cross-modal residual distillation. In particular, we employ a strong camera-based teaching assistant model to distill powerful visual knowledge effectively through intra-modal distillation. Subsequently, we introduce the cross-modal residual distillation to transfer the 3D spatial cues. By acquiring both visual knowledge and 3D spatial cues, the predictions of our approach are rigorously evaluated on the KITTI 3D object detection benchmark and achieve state-of-the-art performance in Mono3D.
4/9/2024

DPO: Dual-Perturbation Optimization for Test-time Adaptation in 3D Object Detection
Zhuoxiao Chen, Zixin Wang, Sen Wang, Zi Huang, Yadan Luo
0
0
LiDAR-based 3D object detection has seen impressive advances in recent times. However, deploying trained 3D detectors in the real world often yields unsatisfactory performance when the distribution of the test data significantly deviates from the training data due to different weather conditions, object sizes, textit{etc}. A key factor in this performance degradation is the diminished generalizability of pre-trained models, which creates a sharp loss landscape during training. Such sharpness, when encountered during testing, can precipitate significant performance declines, even with minor data variations. To address the aforementioned challenges, we propose textbf{dual-perturbation optimization (DPO)} for textbf{underline{T}est-underline{t}ime underline{A}daptation in underline{3}D underline{O}bject underline{D}etection (TTA-3OD)}. We minimize the sharpness to cultivate a flat loss landscape to ensure model resiliency to minor data variations, thereby enhancing the generalization of the adaptation process. To fully capture the inherent variability of the test point clouds, we further introduce adversarial perturbation to the input BEV features to better simulate the noisy test environment. As the dual perturbation strategy relies on trustworthy supervision signals, we utilize a reliable Hungarian matcher to filter out pseudo-labels sensitive to perturbations. Additionally, we introduce early Hungarian cutoff to avoid error accumulation from incorrect pseudo-labels by halting the adaptation process. Extensive experiments across three types of transfer tasks demonstrate that the proposed DPO significantly surpasses previous state-of-the-art approaches, specifically on Waymo $rightarrow$ KITTI, outperforming the most competitive baseline by 57.72% in $text{AP}_text{3D}$ and reaching 91% of the fully supervised upper bound.
6/21/2024

MonoDETRNext: Next-generation Accurate and Efficient Monocular 3D Object Detection Method
Pan Liao, Feng Yang, Di Wu, Liu Bo
0
0
Monocular vision-based 3D object detection is crucial in various sectors, yet existing methods face significant challenges in terms of accuracy and computational efficiency. Building on the successful strategies in 2D detection and depth estimation, we propose MonoDETRNext, which seeks to optimally balance precision and processing speed. Our methodology includes the development of an efficient hybrid visual encoder, enhancement of depth prediction mechanisms, and introduction of an innovative query generation strategy, augmented by an advanced depth predictor. Building on MonoDETR, MonoDETRNext introduces two variants: MonoDETRNext-F, which emphasizes speed, and MonoDETRNext-A, which focuses on precision. We posit that MonoDETRNext establishes a new benchmark in monocular 3D object detection and opens avenues for future research. We conducted an exhaustive evaluation demonstrating the model's superior performance against existing solutions. Notably, MonoDETRNext-A demonstrated a 4.60% improvement in the AP3D metric on the KITTI test benchmark over MonoDETR, while MonoDETRNext-F showed a 2.21% increase. Additionally, the computational efficiency of MonoDETRNext-F slightly exceeds that of its predecessor.
5/27/2024