MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3D Object Detection
2404.04910
0
0
Abstract
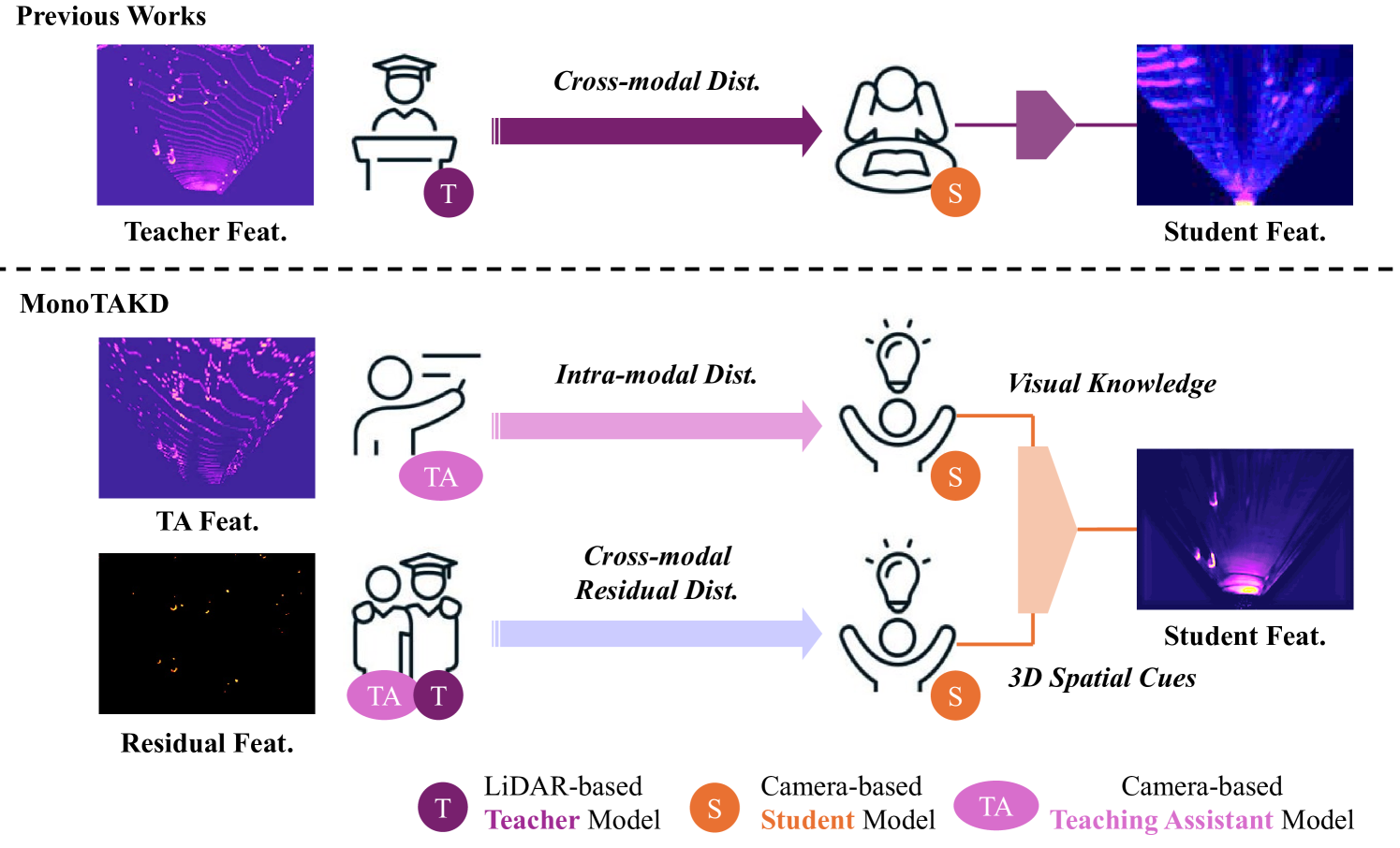
Monocular 3D object detection (Mono3D) is an indispensable research topic in autonomous driving, thanks to the cost-effective monocular camera sensors and its wide range of applications. Since the image perspective has depth ambiguity, the challenges of Mono3D lie in understanding 3D scene geometry and reconstructing 3D object information from a single image. Previous methods attempted to transfer 3D information directly from the LiDAR-based teacher to the camera-based student. However, a considerable gap in feature representation makes direct cross-modal distillation inefficient, resulting in a significant performance deterioration between the LiDAR-based teacher and the camera-based student. To address this issue, we propose the Teaching Assistant Knowledge Distillation (MonoTAKD) to break down the learning objective by integrating intra-modal distillation with cross-modal residual distillation. In particular, we employ a strong camera-based teaching assistant model to distill powerful visual knowledge effectively through intra-modal distillation. Subsequently, we introduce the cross-modal residual distillation to transfer the 3D spatial cues. By acquiring both visual knowledge and 3D spatial cues, the predictions of our approach are rigorously evaluated on the KITTI 3D object detection benchmark and achieve state-of-the-art performance in Mono3D.
Create account to get full access
Overview
- This research paper introduces MonoTAKD, a novel method for improving the performance of monocular 3D object detection models using knowledge distillation from a teaching assistant model.
- Monocular 3D object detection, which uses a single camera to estimate the 3D position and dimensions of objects, is a challenging computer vision task with many real-world applications.
- The authors propose using a teaching assistant model, typically a more accurate but computationally expensive LiDAR-based 3D detector, to guide the training of a monocular 3D detector in a knowledge distillation framework.
Plain English Explanation
Monocular 3D object detection is the task of using a single camera to figure out the 3D location and size of objects in an image. This is a tricky problem because a single camera doesn't have the same depth information as a 3D sensor like a LiDAR. The authors of this paper have come up with a way to improve monocular 3D object detectors by having them learn from a more accurate, but slower, LiDAR-based 3D detector.
The key idea is to use the LiDAR-based detector as a "teaching assistant" to guide the training of the monocular detector. The monocular detector tries to mimic the outputs of the teaching assistant, which helps it learn to make better 3D predictions from the single camera input. This knowledge distillation approach allows the monocular model to benefit from the 3D understanding of the more complex LiDAR-based model, without having to be as computationally expensive.
Technical Explanation
The authors propose a novel knowledge distillation framework called MonoTAKD (Monocular Teaching Assistant Knowledge Distillation) to improve the performance of monocular 3D object detectors. Typically, monocular 3D detectors struggle to match the accuracy of more complex LiDAR-based 3D detectors. MonoTAKD addresses this by using a LiDAR-based 3D detector as a "teaching assistant" to guide the training of the monocular 3D detector.
The teaching assistant model is used to generate ground truth 3D bounding boxes and other outputs, which the monocular detector then tries to mimic during training. This allows the monocular model to learn from the 3D understanding captured by the more accurate, but computationally expensive, LiDAR-based model. The authors demonstrate that this knowledge distillation approach leads to significant performance improvements for monocular 3D object detection on standard benchmarks, without increasing the inference time of the final monocular model.
Critical Analysis
The MonoTAKD approach presented in this paper is a clever way to leverage the strengths of LiDAR-based 3D detectors to improve monocular 3D object detection. By using a teaching assistant model, the authors are able to distill 3D knowledge without the computational cost of the more complex LiDAR model.
One potential limitation is that the performance of MonoTAKD is still dependent on the accuracy of the teaching assistant model. If the LiDAR-based detector has blind spots or makes mistakes, those errors could be propagated to the monocular detector during training. The authors do not extensively explore the robustness of their approach to imperfect teaching assistants.
Additionally, the paper does not provide a deep analysis of the types of 3D information being transferred from the teaching assistant to the monocular detector. Further research could investigate which specific 3D cues and features are most effectively learned through this knowledge distillation process.
Overall, the MonoTAKD framework represents a promising direction for improving monocular 3D object detection by complementing the limitations of single-camera input with the 3D understanding of multi-modal sensors. The authors have made a valuable contribution to the field, but there are still opportunities for further refinement and investigation.
Conclusion
This research paper introduces MonoTAKD, a novel knowledge distillation approach that allows monocular 3D object detectors to learn from the 3D understanding of more accurate, but computationally expensive, LiDAR-based detectors. By using the LiDAR-based model as a teaching assistant, the monocular detector can benefit from the 3D cues and features captured by the multi-modal sensor, leading to significant performance improvements without increasing inference time.
The MonoTAKD framework represents an important step forward in bridging the gap between monocular and LiDAR-based 3D object detection, with potential applications in autonomous vehicles, robotics, and augmented reality. While the paper highlights some promising results, there are also opportunities for further research to explore the robustness and generalizability of this knowledge distillation approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fully Test-Time Adaptation for Monocular 3D Object Detection
Hongbin Lin, Yifan Zhang, Shuaicheng Niu, Shuguang Cui, Zhen Li
0
0
Monocular 3D object detection (Mono 3Det) aims to identify 3D objects from a single RGB image. However, existing methods often assume training and test data follow the same distribution, which may not hold in real-world test scenarios. To address the out-of-distribution (OOD) problems, we explore a new adaptation paradigm for Mono 3Det, termed Fully Test-time Adaptation. It aims to adapt a well-trained model to unlabeled test data by handling potential data distribution shifts at test time without access to training data and test labels. However, applying this paradigm in Mono 3Det poses significant challenges due to OOD test data causing a remarkable decline in object detection scores. This decline conflicts with the pre-defined score thresholds of existing detection methods, leading to severe object omissions (i.e., rare positive detections and many false negatives). Consequently, the limited positive detection and plenty of noisy predictions cause test-time adaptation to fail in Mono 3Det. To handle this problem, we propose a novel Monocular Test-Time Adaptation (MonoTTA) method, based on two new strategies. 1) Reliability-driven adaptation: we empirically find that high-score objects are still reliable and the optimization of high-score objects can enhance confidence across all detections. Thus, we devise a self-adaptive strategy to identify reliable objects for model adaptation, which discovers potential objects and alleviates omissions. 2) Noise-guard adaptation: since high-score objects may be scarce, we develop a negative regularization term to exploit the numerous low-score objects via negative learning, preventing overfitting to noise and trivial solutions. Experimental results show that MonoTTA brings significant performance gains for Mono 3Det models in OOD test scenarios, approximately 190% gains by average on KITTI and 198% gains on nuScenes.
5/31/2024

Better Monocular 3D Detectors with LiDAR from the Past
Yurong You, Cheng Perng Phoo, Carlos Andres Diaz-Ruiz, Katie Z Luo, Wei-Lun Chao, Mark Campbell, Bharath Hariharan, Kilian Q Weinberger
0
0
Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
4/11/2024

MTKD: Multi-Teacher Knowledge Distillation for Image Super-Resolution
Yuxuan Jiang, Chen Feng, Fan Zhang, David Bull
0
0
Knowledge distillation (KD) has emerged as a promising technique in deep learning, typically employed to enhance a compact student network through learning from their high-performance but more complex teacher variant. When applied in the context of image super-resolution, most KD approaches are modified versions of methods developed for other computer vision tasks, which are based on training strategies with a single teacher and simple loss functions. In this paper, we propose a novel Multi-Teacher Knowledge Distillation (MTKD) framework specifically for image super-resolution. It exploits the advantages of multiple teachers by combining and enhancing the outputs of these teacher models, which then guides the learning process of the compact student network. To achieve more effective learning performance, we have also developed a new wavelet-based loss function for MTKD, which can better optimize the training process by observing differences in both the spatial and frequency domains. We fully evaluate the effectiveness of the proposed method by comparing it to five commonly used KD methods for image super-resolution based on three popular network architectures. The results show that the proposed MTKD method achieves evident improvements in super-resolution performance, up to 0.46dB (based on PSNR), over state-of-the-art KD approaches across different network structures. The source code of MTKD will be made available here for public evaluation.
4/16/2024

CrossKD: Cross-Head Knowledge Distillation for Object Detection
Jiabao Wang, Yuming Chen, Zhaohui Zheng, Xiang Li, Ming-Ming Cheng, Qibin Hou
0
0
Knowledge Distillation (KD) has been validated as an effective model compression technique for learning compact object detectors. Existing state-of-the-art KD methods for object detection are mostly based on feature imitation. In this paper, we present a general and effective prediction mimicking distillation scheme, called CrossKD, which delivers the intermediate features of the student's detection head to the teacher's detection head. The resulting cross-head predictions are then forced to mimic the teacher's predictions. This manner relieves the student's head from receiving contradictory supervision signals from the annotations and the teacher's predictions, greatly improving the student's detection performance. Moreover, as mimicking the teacher's predictions is the target of KD, CrossKD offers more task-oriented information in contrast with feature imitation. On MS COCO, with only prediction mimicking losses applied, our CrossKD boosts the average precision of GFL ResNet-50 with 1x training schedule from 40.2 to 43.7, outperforming all existing KD methods. In addition, our method also works well when distilling detectors with heterogeneous backbones. Code is available at https://github.com/jbwang1997/CrossKD.
4/16/2024