The fusion of phonography and ideographic characters into virtual Chinese characters -- Based on Chinese and English

0
📉
Sign in to get full access
Overview
- Modern writing systems are primarily divided into ideographic and phonetic characters
- Both have advantages and disadvantages
- Chinese is difficult to learn but easy to master, while English is easy to learn but has a large vocabulary
- There is no language that combines the advantages of both and is easy to learn with low memory requirements
Plain English Explanation
The main types of writing systems used in modern countries are ideographic characters and phonetic characters. Ideographic characters, like those used in Chinese, represent whole concepts or ideas. Phonetic characters, like those used in English, represent the individual sounds of a language.
Both writing systems have their pros and cons. Chinese is challenging to learn initially, as you need to memorize thousands of unique characters. However, once learned, it is relatively easy to express complex ideas. English, on the other hand, is easier to pick up, but has a massive vocabulary that can be difficult to master.
Essentially, there is no existing language that combines the benefits of both ideographic and phonetic writing. An ideal system would be easy to learn, like English, but also allow for the efficient expression of complex ideas, like Chinese. It would also require less memory capacity to store all the necessary characters or sounds.
Technical Explanation
The paper explores the possibility of creating a new writing system that draws on the strengths of both ideographic and phonetic characters. The key elements include:
-
Observing Advantages and Disadvantages: The researchers analyze the vocabulary, information content, and ease of learning of Chinese and English, particularly in the context of scientific knowledge.
-
Comparative Analysis: They use a comparative approach to evaluate the overall performance of a hypothetical new writing system, considering factors like vocabulary size, learnability, and expressive power.
-
New Character Design: The proposed system would feature new characters that can be combined to form words, reducing the total number of unique characters that need to be learned.
-
Semantic Categorization: Special prefixes would allow beginners to quickly infer the approximate meaning and category of unfamiliar words.
-
Learning Efficiency: The new characters and word-building approach are designed to enable faster acquisition of advanced knowledge compared to existing writing systems.
Critical Analysis
The paper presents a compelling vision for a new writing system that could address some of the key limitations of ideographic and phonetic languages. However, it is important to consider a few potential caveats:
- The feasibility and practicality of implementing a completely new writing system at a global scale is questionable, as it would require widespread adoption and adaptation.
- The specific design choices for the new characters and word-building rules would need to be thoroughly tested and validated to ensure they achieve the desired benefits.
- The paper does not address potential challenges in terms of technological support, software compatibility, and integration with existing digital systems.
Conclusion
The research proposes an innovative approach to designing a new writing system that combines the strengths of ideographic and phonetic characters. By creating new characters that can be combined into words, the system aims to reduce the overall memory burden while maintaining the expressive power of Chinese and the learnability of English.
If successfully developed and adopted, this new writing system could enable more efficient knowledge acquisition and communication, potentially bridging the gap between the two dominant language paradigms. However, the practicality and feasibility of such a radical change in global writing systems warrant further exploration and consideration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
The fusion of phonography and ideographic characters into virtual Chinese characters -- Based on Chinese and English
Hongfa Zi, Zhen Liu
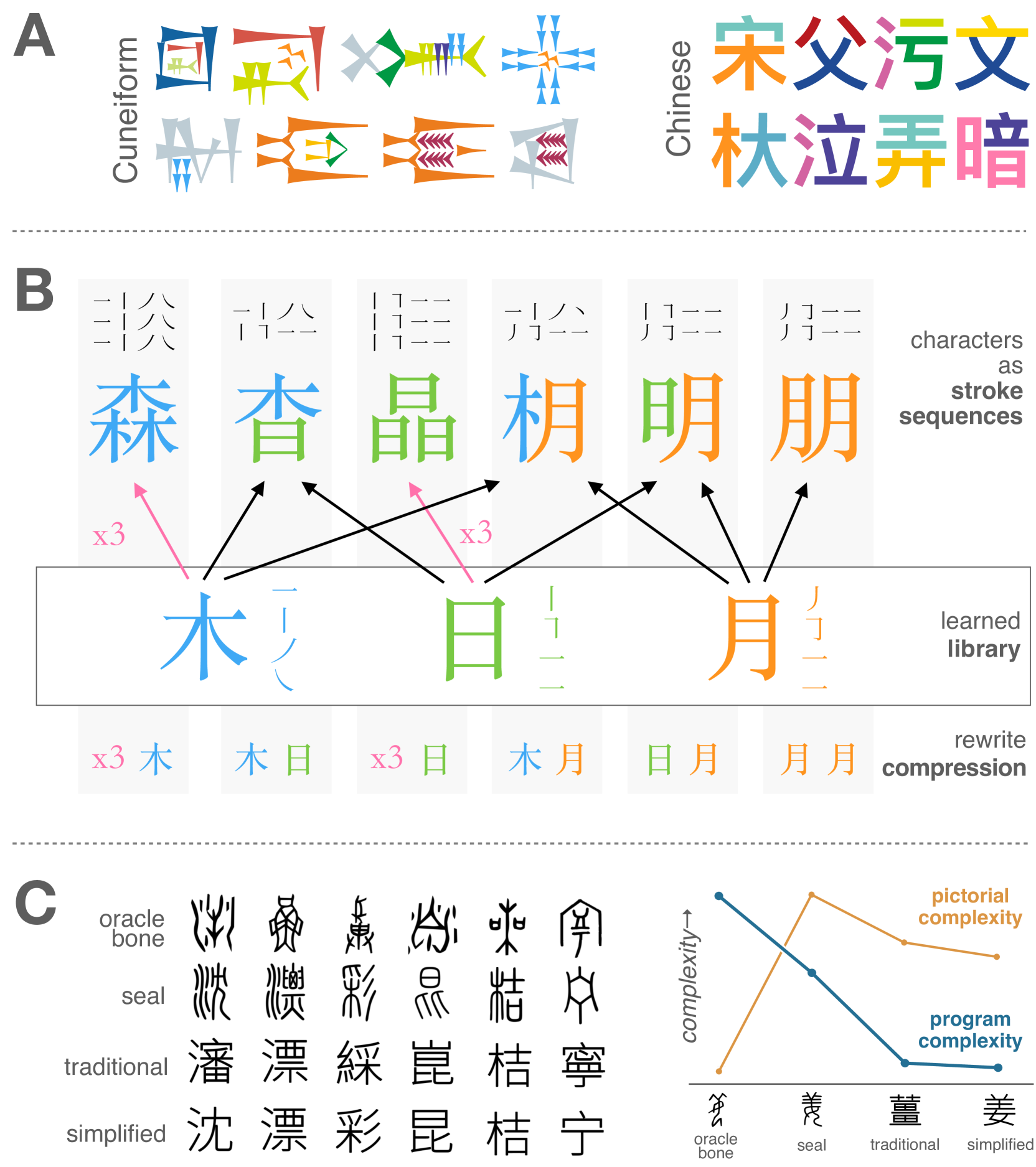
The characters used in modern countries are mainly divided into ideographic characters and phonetic characters, both of which have their advantages and disadvantages. Chinese is difficult to learn and easy to master, while English is easy to learn but has a large vocabulary. There is still no language that combines the advantages of both languages and has less memory capacity, can form words, and is easy to learn. Therefore, inventing new characters that can be combined and the popularization of deep knowledge, and reduce disputes through communication. Firstly, observe the advantages and disadvantages of Chinese and English, such as their vocabulary, information content, and ease of learning in deep scientific knowledge, and create a new writing system. Then, use comparative analysis to observe the total score of the new language. Through this article, it can be concluded that the new text combines the advantages of both pictographic and alphabetical writing: new characters that can be combined into words reduces the vocabulary that needs to be learned; Special prefixes allow beginners to quickly guess the approximate category and meaning of unseen words; New characters can enable humans to quickly learn more advanced knowledge.
Read more8/21/2024
0
Finding structure in logographic writing with library learning
Guangyuan Jiang, Matthias Hofer, Jiayuan Mao, Lionel Wong, Joshua B. Tenenbaum, Roger P. Levy
One hallmark of human language is its combinatoriality -- reusing a relatively small inventory of building blocks to create a far larger inventory of increasingly complex structures. In this paper, we explore the idea that combinatoriality in language reflects a human inductive bias toward representational efficiency in symbol systems. We develop a computational framework for discovering structure in a writing system. Built on top of state-of-the-art library learning and program synthesis techniques, our computational framework discovers known linguistic structures in the Chinese writing system and reveals how the system evolves towards simplification under pressures for representational efficiency. We demonstrate how a library learning approach, utilizing learned abstractions and compression, may help reveal the fundamental computational principles that underlie the creation of combinatorial structures in human cognition, and offer broader insights into the evolution of efficient communication systems.
Read more5/14/2024

0
Classifying Graphemes in English Words Through the Application of a Fuzzy Inference System
Samuel Rose, Chandrasekhar Kambhampati
In Linguistics, a grapheme is a written unit of a writing system corresponding to a phonological sound. In Natural Language Processing tasks, written language is analysed through two different mediums, word analysis, and character analysis. This paper focuses on a third approach, the analysis of graphemes. Graphemes have advantages over word and character analysis by being self-contained representations of phonetic sounds. Due to the nature of splitting a word into graphemes being based on complex, non-binary rules, the application of fuzzy logic would provide a suitable medium upon which to predict the number of graphemes in a word. This paper proposes the application of a Fuzzy Inference System to split words into their graphemes. This Fuzzy Inference System results in a correct prediction of the number of graphemes in a word 50.18% of the time, with 93.51% being within a margin of +- 1 from the correct classification. Given the variety in language, graphemes are tied with pronunciation and therefore can change depending on a regional accent/dialect, the +- 1 accuracy represents the impreciseness of grapheme classification when regional variances are accounted for. To give a baseline of comparison, a second method involving a recursive IPA mapping exercise using a pronunciation dictionary was developed to allow for comparisons to be made.
Read more4/3/2024
✅
0
Unicode Normalization and Grapheme Parsing of Indic Languages
Nazmuddoha Ansary, Quazi Adibur Rahman Adib, Tahsin Reasat, Asif Shahriyar Sushmit, Ahmed Imtiaz Humayun, Sazia Mehnaz, Kanij Fatema, Mohammad Mamun Or Rashid, Farig Sadeque
Writing systems of Indic languages have orthographic syllables, also known as complex graphemes, as unique horizontal units. A prominent feature of these languages is these complex grapheme units that comprise consonants/consonant conjuncts, vowel diacritics, and consonant diacritics, which, together make a unique Language. Unicode-based writing schemes of these languages often disregard this feature of these languages and encode words as linear sequences of Unicode characters using an intricate scheme of connector characters and font interpreters. Due to this way of using a few dozen Unicode glyphs to write thousands of different unique glyphs (complex graphemes), there are serious ambiguities that lead to malformed words. In this paper, we are proposing two libraries: i) a normalizer for normalizing inconsistencies caused by a Unicode-based encoding scheme for Indic languages and ii) a grapheme parser for Abugida text. It deconstructs words into visually distinct orthographic syllables or complex graphemes and their constituents. Our proposed normalizer is a more efficient and effective tool than the previously used IndicNLP normalizer. Moreover, our parser and normalizer are also suitable tools for general Abugida text processing as they performed well in our robust word-based and NLP experiments. We report the pipeline for the scripts of 7 languages in this work and develop the framework for the integration of more scripts.
Read more5/28/2024