Finding structure in logographic writing with library learning

0
Sign in to get full access
Overview
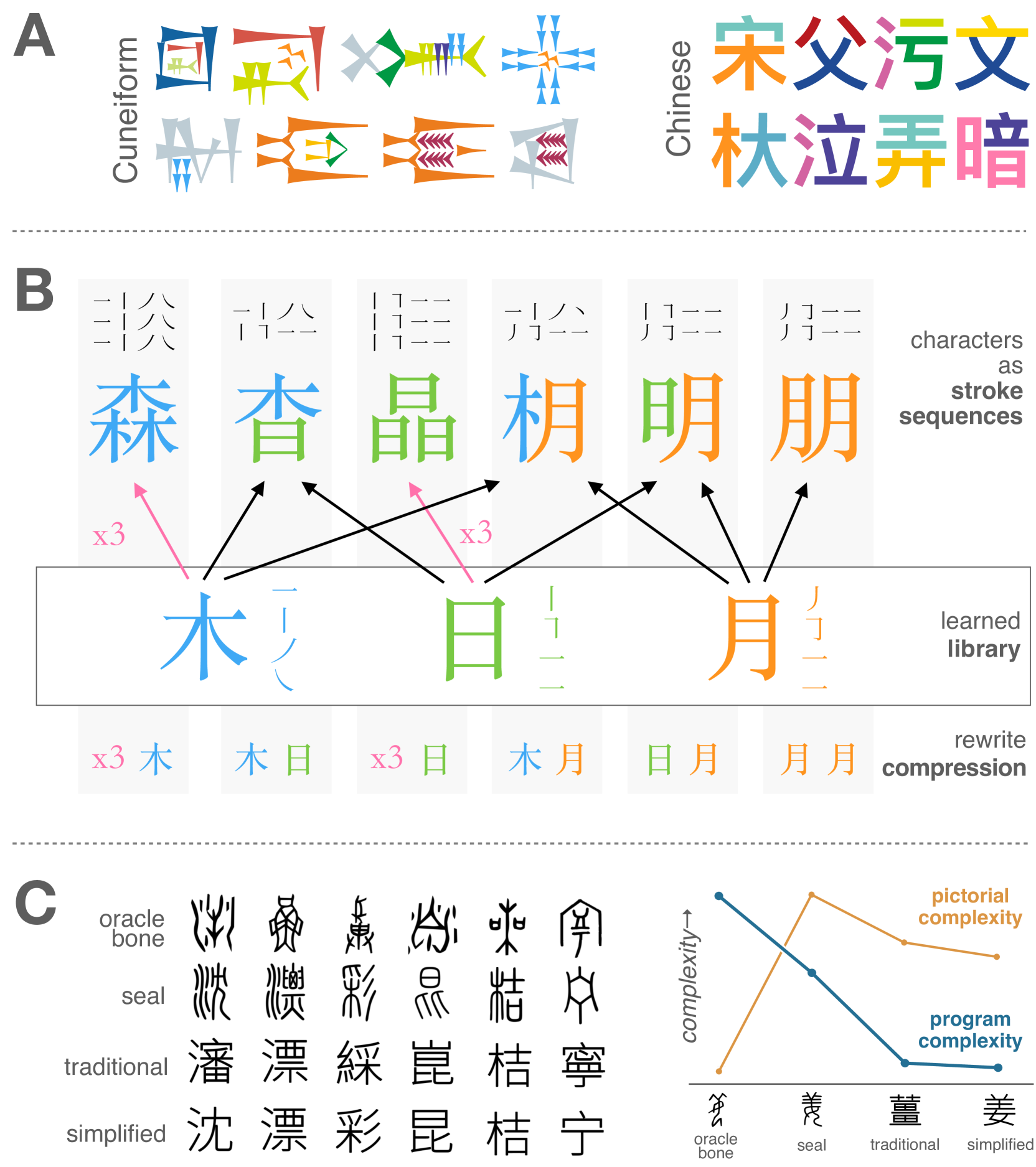
- This paper explores a library learning model for understanding the structure of the Chinese writing system, which is a logographic system where characters represent whole words or concepts rather than individual sounds.
- The researchers propose a model that can learn the underlying structure of Chinese characters by building a "library" of common character components and their relationships.
- The goal is to better understand how the Chinese writing system encodes linguistic and semantic information, and to develop more effective learning and recognition systems for Chinese characters.
Plain English Explanation
The Chinese writing system is quite different from alphabetic writing systems like English. Instead of using letters to represent individual sounds, Chinese characters represent whole words or concepts. This makes the writing system more compositional - the characters are built up from common components that carry meaning.
The researchers in this paper wanted to understand how this compositional structure works in the Chinese writing system. They developed a library learning model that can automatically discover the common character components and their relationships. The idea is similar to how we might build a "library" of words and their parts to understand a language.
By learning this underlying structure, the model can help us better recognize and process Chinese characters, just like understanding the building blocks of words can help us learn and use a language more effectively. This could lead to improvements in Chinese language learning, character recognition systems, and our overall understanding of how logographic writing systems encode information.
Technical Explanation
The core of the researchers' approach is a library learning model that aims to discover the structural components of Chinese characters and how they relate to each other.
The model takes a large corpus of Chinese characters as input and learns a library of common character components, along with their spatial arrangements and semantic relationships. This library acts as a kind of "dictionary" that the model can use to analyze and decompose new characters it encounters.
To train the model, the researchers used an unsupervised iterative learning approach. The model repeatedly processes the character corpus, updating its library and the relationships between components. This allows the model to gradually build up a more sophisticated understanding of the writing system's structure.
The researchers evaluated their model on several tasks, including character recognition and the identification of semantic relationships between characters. The results showed that the library learning approach outperformed traditional methods, demonstrating its potential to uncover the underlying compositional nature of the Chinese writing system.
Critical Analysis
The researchers acknowledge several limitations and areas for further exploration in their work. For example, the current model is trained on a limited corpus of characters and could benefit from scaling up to larger datasets. Additionally, the model's ability to capture more nuanced semantic relationships between character components is an area that requires further investigation.
Another potential concern is the extent to which the discovered character components and their relationships align with experts' understanding of the Chinese writing system. While the model's performance on various tasks is promising, it would be valuable to cross-validate the learned structures with linguistic and historical knowledge of character formation.
Finally, the researchers note that their approach focuses on the structural aspects of Chinese characters, but does not directly address higher-level language processing tasks like sentence understanding or translation. Integrating the library learning model with other language modeling techniques could be an interesting direction for future research.
Conclusion
This paper presents a novel library learning approach to modeling the structure of the Chinese writing system, a logographic system where characters represent whole words or concepts. The model's ability to discover the underlying compositional nature of Chinese characters and their relationships demonstrates its potential to enhance our understanding of this unique writing system.
By uncovering the building blocks of Chinese characters and their semantic connections, the library learning model could lead to improvements in character recognition, language learning, and other applications that rely on effective processing of logographic scripts. The researchers' work highlights the value of exploring the compositional structure of writing systems, which may offer insights into the cognitive and linguistic mechanisms underlying human language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Finding structure in logographic writing with library learning
Guangyuan Jiang, Matthias Hofer, Jiayuan Mao, Lionel Wong, Joshua B. Tenenbaum, Roger P. Levy
One hallmark of human language is its combinatoriality -- reusing a relatively small inventory of building blocks to create a far larger inventory of increasingly complex structures. In this paper, we explore the idea that combinatoriality in language reflects a human inductive bias toward representational efficiency in symbol systems. We develop a computational framework for discovering structure in a writing system. Built on top of state-of-the-art library learning and program synthesis techniques, our computational framework discovers known linguistic structures in the Chinese writing system and reveals how the system evolves towards simplification under pressures for representational efficiency. We demonstrate how a library learning approach, utilizing learned abstractions and compression, may help reveal the fundamental computational principles that underlie the creation of combinatorial structures in human cognition, and offer broader insights into the evolution of efficient communication systems.
Read more5/14/2024

0
Linguistic Structure from a Bottleneck on Sequential Information Processing
Richard Futrell, Michael Hahn
Human language is a unique form of communication in the natural world, distinguished by its structured nature. Most fundamentally, it is systematic, meaning that signals can be broken down into component parts that are individually meaningful -- roughly, words -- which are combined in a regular way to form sentences. Furthermore, the way in which these parts are combined maintains a kind of locality: words are usually concatenated together, and they form contiguous phrases, keeping related parts of sentences close to each other. We address the challenge of understanding how these basic properties of language arise from broader principles of efficient communication under information processing constraints. Here we show that natural-language-like systematicity arises from minimization of excess entropy, a measure of statistical complexity that represents the minimum amount of information necessary for predicting the future of a sequence based on its past. In simulations, we show that codes that minimize excess entropy factorize their source distributions into approximately independent components, and then express those components systematically and locally. Next, in a series of massively cross-linguistic corpus studies, we show that human languages are structured to have low excess entropy at the level of phonology, morphology, syntax, and semantics. Our result suggests that human language performs a sequential generalization of Independent Components Analysis on the statistical distribution over meanings that need to be expressed. It establishes a link between the statistical and algebraic structure of human language, and reinforces the idea that the structure of human language may have evolved to minimize cognitive load while maximizing communicative expressiveness.
Read more5/21/2024
💬
0
Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning
Jun Zhao, Jingqi Tong, Yurong Mou, Ming Zhang, Qi Zhang, Xuanjing Huang
Human cognition exhibits systematic compositionality, the algebraic ability to generate infinite novel combinations from finite learned components, which is the key to understanding and reasoning about complex logic. In this work, we investigate the compositionality of large language models (LLMs) in mathematical reasoning. Specifically, we construct a new dataset textsc{MathTrap}footnotemark[3] by introducing carefully designed logical traps into the problem descriptions of MATH and GSM8k. Since problems with logical flaws are quite rare in the real world, these represent ``unseen'' cases to LLMs. Solving these requires the models to systematically compose (1) the mathematical knowledge involved in the original problems with (2) knowledge related to the introduced traps. Our experiments show that while LLMs possess both components of requisite knowledge, they do not textbf{spontaneously} combine them to handle these novel cases. We explore several methods to mitigate this deficiency, such as natural language prompts, few-shot demonstrations, and fine-tuning. We find that LLMs' performance can be textbf{passively} improved through the above external intervention. Overall, systematic compositionality remains an open challenge for large language models.
Read more7/15/2024
💬
0
What Makes a Language Easy to Deep-Learn?
Lukas Galke, Yoav Ram, Limor Raviv
Deep neural networks drive the success of natural language processing. A fundamental property of language is its compositional structure, allowing humans to systematically produce forms for new meanings. For humans, languages with more compositional and transparent structures are typically easier to learn than those with opaque and irregular structures. However, this learnability advantage has not yet been shown for deep neural networks, limiting their use as models for human language learning. Here, we directly test how neural networks compare to humans in learning and generalizing different languages that vary in their degree of compositional structure. We evaluate the memorization and generalization capabilities of a large language model and recurrent neural networks, and show that both deep neural networks exhibit a learnability advantage for more structured linguistic input: neural networks exposed to more compositional languages show more systematic generalization, greater agreement between different agents, and greater similarity to human learners.
Read more4/5/2024