G3FA: Geometry-guided GAN for Face Animation

0

Sign in to get full access
Overview
- The paper introduces a new method called G3FA, which stands for Geometry-guided GAN for Face Animation.
- G3FA generates realistic face animations by conditioning the generation on 3D facial geometry.
- The approach outperforms previous state-of-the-art methods in terms of visual quality and temporal coherence.
Plain English Explanation
G3FA: Geometry-guided GAN for Face Animation proposes a new way to create realistic and natural-looking face animations. The key idea is to use 3D facial geometry information to guide the generation of the animated faces.
Traditionally, face animation methods have struggled to achieve high visual quality and temporal consistency, where the animated faces look unnatural or "jittery" over time. The researchers behind G3FA realized that by incorporating the underlying 3D facial structure into the generation process, they could produce much more convincing and stable face animations.
The G3FA system takes in a source face image and a sequence of target 3D facial landmarks. It then generates a video of the source face seamlessly morphing and moving to match the target facial expressions and head poses. The 3D geometric information acts as a guide, ensuring the generated faces preserve the correct facial structure and movement throughout the animation.
Through extensive experiments, the authors demonstrate that G3FA outperforms previous state-of-the-art face animation methods in terms of visual fidelity and temporal coherence. The incorporation of 3D facial geometry appears to be a key innovation that leads to these improvements.
Technical Explanation
G3FA: Geometry-guided GAN for Face Animation presents a novel approach for generating realistic face animations by conditioning the generation on 3D facial geometry. The core of the G3FA system is a Generative Adversarial Network (GAN) that learns to map a source face image and a sequence of 3D facial landmarks to a video of the source face performing the target facial expressions and head poses.
The generator network in G3FA takes as input the source face image and the 3D landmark sequence, and outputs a video of the animated face. The discriminator network, on the other hand, aims to distinguish between real and generated face animation videos. By training this GAN in an adversarial manner, the generator learns to produce highly realistic and temporally coherent face animations that preserve the correct facial structure.
A key innovation in G3FA is the use of 3D facial geometry as a conditioning input to the generator. This 3D information, in the form of facial landmark coordinates, serves as a strong prior to guide the generation process and ensure the animated faces maintain the appropriate facial structure and movements.
The authors demonstrate the effectiveness of G3FA through extensive qualitative and quantitative evaluations, showing that it outperforms previous state-of-the-art face animation methods in terms of visual quality and temporal consistency. The incorporation of 3D facial geometry appears to be a critical factor in achieving these improvements.
Critical Analysis
The G3FA paper presents a promising approach for generating realistic and temporally stable face animations. By leveraging 3D facial geometry as a conditioning input, the method is able to produce animations that maintain the correct facial structure and movements, addressing a key limitation of previous techniques.
However, the paper does not discuss the potential limitations or failure cases of the G3FA system. For example, it is unclear how the method would perform on more challenging scenarios, such as faces with extreme expressions, occlusions, or large head rotations. Additionally, the paper does not provide much insight into the computational efficiency and real-time capabilities of the approach, which could be important for certain applications.
Further research could explore ways to extend the G3FA framework to handle a wider range of facial dynamics and expressions, or to investigate its robustness to various real-world conditions. Integrating the system with other face-related tasks, such as face recognition or emotion analysis, could also be an interesting direction for future work.
Overall, the G3FA paper makes a valuable contribution to the field of face animation by demonstrating the advantages of incorporating 3D facial geometry into the generation process. However, there is still room for improvement and further exploration to fully realize the potential of this approach.
Conclusion
The G3FA paper introduces a novel method for generating realistic and temporally coherent face animations by conditioning the generation on 3D facial geometry. By using the 3D facial landmark information as a guide, the system is able to produce animated faces that maintain the correct facial structure and movements, outperforming previous state-of-the-art techniques.
This work highlights the importance of leveraging 3D geometric information in the face animation task, as it provides a strong prior to ensure the generated faces are physically plausible and visually appealing. The G3FA approach represents a promising step forward in the field of face animation, with potential applications in areas such as virtual reality, gaming, and film production.
While the paper demonstrates the effectiveness of the proposed method, further research is needed to explore its limitations and potential extensions. Integrating G3FA with other face-related tasks and investigating its real-world performance could lead to even more powerful and versatile face animation systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
G3FA: Geometry-guided GAN for Face Animation
Alireza Javanmardi, Alain Pagani, Didier Stricker
Animating human face images aims to synthesize a desired source identity in a natural-looking way mimicking a driving video's facial movements. In this context, Generative Adversarial Networks have demonstrated remarkable potential in real-time face reenactment using a single source image, yet are constrained by limited geometry consistency compared to graphic-based approaches. In this paper, we introduce Geometry-guided GAN for Face Animation (G3FA) to tackle this limitation. Our novel approach empowers the face animation model to incorporate 3D information using only 2D images, improving the image generation capabilities of the talking head synthesis model. We integrate inverse rendering techniques to extract 3D facial geometry properties, improving the feedback loop to the generator through a weighted average ensemble of discriminators. In our face reenactment model, we leverage 2D motion warping to capture motion dynamics along with orthogonal ray sampling and volume rendering techniques to produce the ultimate visual output. To evaluate the performance of our G3FA, we conducted comprehensive experiments using various evaluation protocols on VoxCeleb2 and TalkingHead benchmarks to demonstrate the effectiveness of our proposed framework compared to the state-of-the-art real-time face animation methods.
Read more8/26/2024
0
G2Face: High-Fidelity Reversible Face Anonymization via Generative and Geometric Priors
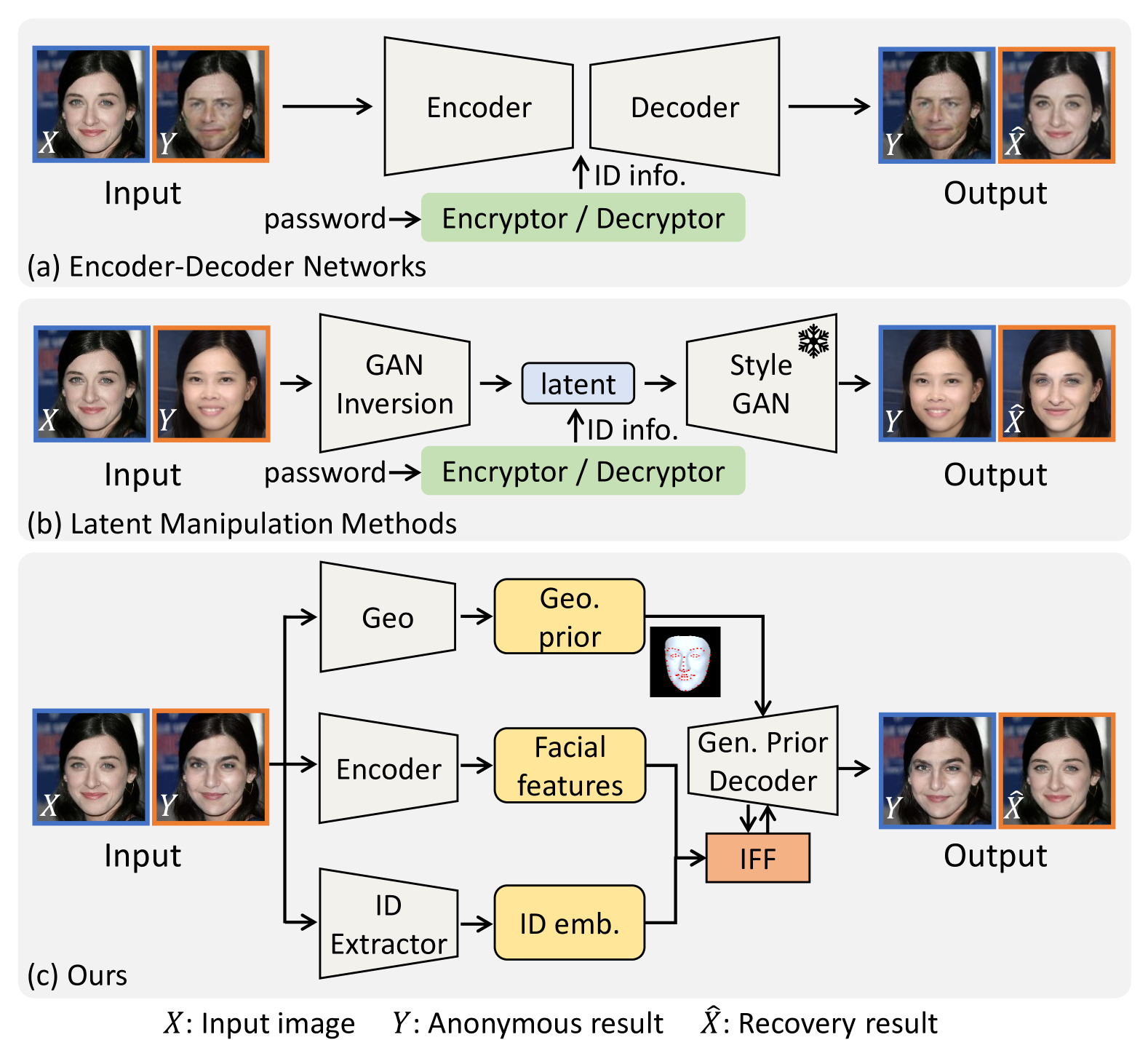
Haoxin Yang, Xuemiao Xu, Cheng Xu, Huaidong Zhang, Jing Qin, Yi Wang, Pheng-Ann Heng, Shengfeng He
Reversible face anonymization, unlike traditional face pixelization, seeks to replace sensitive identity information in facial images with synthesized alternatives, preserving privacy without sacrificing image clarity. Traditional methods, such as encoder-decoder networks, often result in significant loss of facial details due to their limited learning capacity. Additionally, relying on latent manipulation in pre-trained GANs can lead to changes in ID-irrelevant attributes, adversely affecting data utility due to GAN inversion inaccuracies. This paper introduces Gtextsuperscript{2}Face, which leverages both generative and geometric priors to enhance identity manipulation, achieving high-quality reversible face anonymization without compromising data utility. We utilize a 3D face model to extract geometric information from the input face, integrating it with a pre-trained GAN-based decoder. This synergy of generative and geometric priors allows the decoder to produce realistic anonymized faces with consistent geometry. Moreover, multi-scale facial features are extracted from the original face and combined with the decoder using our novel identity-aware feature fusion blocks (IFF). This integration enables precise blending of the generated facial patterns with the original ID-irrelevant features, resulting in accurate identity manipulation. Extensive experiments demonstrate that our method outperforms existing state-of-the-art techniques in face anonymization and recovery, while preserving high data utility. Code is available at https://github.com/Harxis/G2Face.
Read more8/20/2024
0
FAGhead: Fully Animate Gaussian Head from Monocular Videos
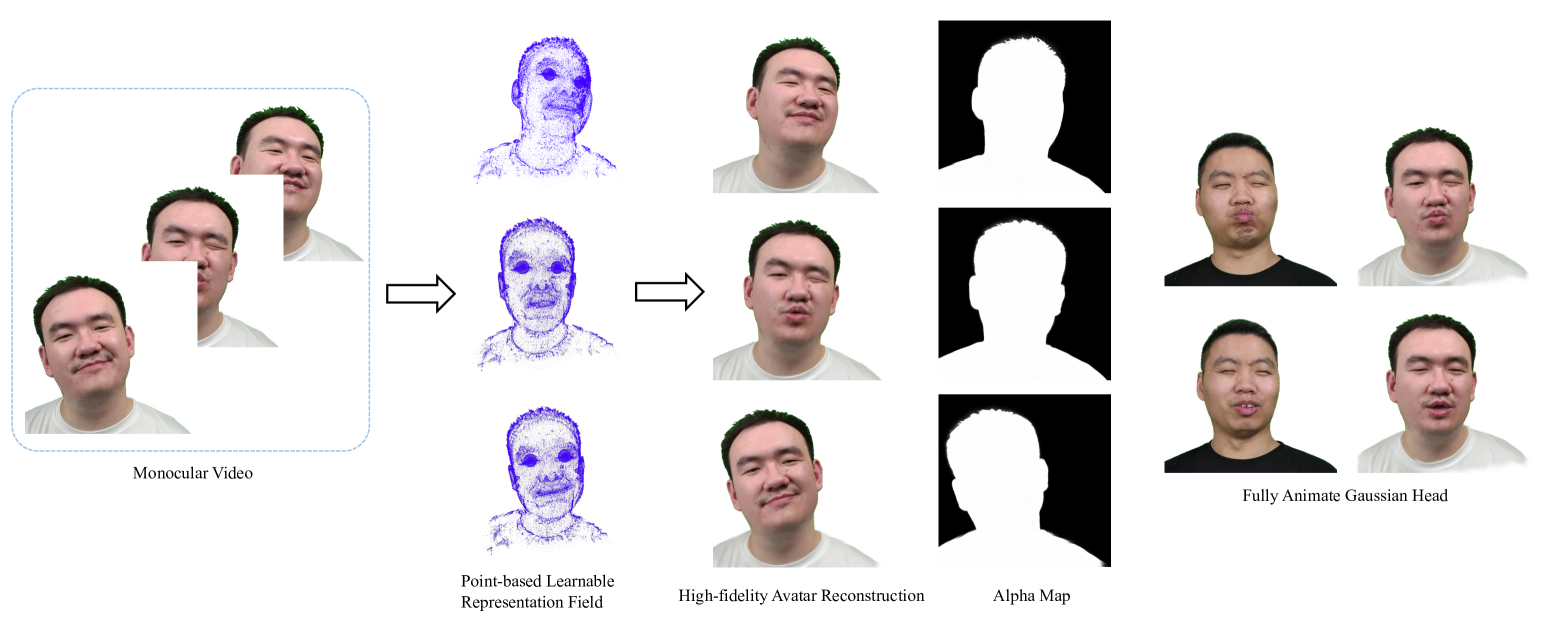
Yixin Xuan, Xinyang Li, Gongxin Yao, Shiwei Zhou, Donghui Sun, Xiaoxin Chen, Yu Pan
High-fidelity reconstruction of 3D human avatars has a wild application in visual reality. In this paper, we introduce FAGhead, a method that enables fully controllable human portraits from monocular videos. We explicit the traditional 3D morphable meshes (3DMM) and optimize the neutral 3D Gaussians to reconstruct with complex expressions. Furthermore, we employ a novel Point-based Learnable Representation Field (PLRF) with learnable Gaussian point positions to enhance reconstruction performance. Meanwhile, to effectively manage the edges of avatars, we introduced the alpha rendering to supervise the alpha value of each pixel. Extensive experimental results on the open-source datasets and our capturing datasets demonstrate that our approach is able to generate high-fidelity 3D head avatars and fully control the expression and pose of the virtual avatars, which is outperforming than existing works.
Read more7/1/2024

0
G$^2$V$^2$former: Graph Guided Video Vision Transformer for Face Anti-Spoofing
Jingyi Yang, Zitong Yu, Xiuming Ni, Jia He, Hui Li
In videos containing spoofed faces, we may uncover the spoofing evidence based on either photometric or dynamic abnormality, even a combination of both. Prevailing face anti-spoofing (FAS) approaches generally concentrate on the single-frame scenario, however, purely photometric-driven methods overlook the dynamic spoofing clues that may be exposed over time. This may lead FAS systems to conclude incorrect judgments, especially in cases where it is easily distinguishable in terms of dynamics but challenging to discern in terms of photometrics. To this end, we propose the Graph Guided Video Vision Transformer (G$^2$V$^2$former), which combines faces with facial landmarks for photometric and dynamic feature fusion. We factorize the attention into space and time, and fuse them via a spatiotemporal block. Specifically, we design a novel temporal attention called Kronecker temporal attention, which has a wider receptive field, and is beneficial for capturing dynamic information. Moreover, we leverage the low-semantic motion of facial landmarks to guide the high-semantic change of facial expressions based on the motivation that regions containing landmarks may reveal more dynamic clues. Extensive experiments on nine benchmark datasets demonstrate that our method achieves superior performance under various scenarios. The codes will be released soon.
Read more8/15/2024