Game-MUG: Multimodal Oriented Game Situation Understanding and Commentary Generation Dataset
2404.19175
0
0
🤔
Abstract
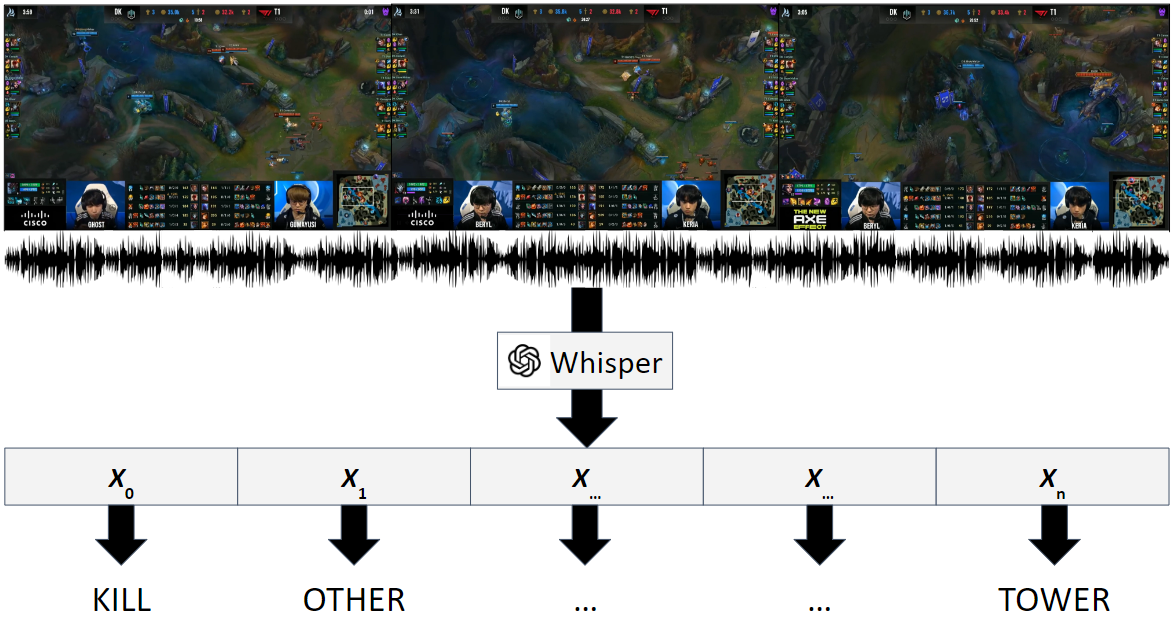
The dynamic nature of esports makes the situation relatively complicated for average viewers. Esports broadcasting involves game expert casters, but the caster-dependent game commentary is not enough to fully understand the game situation. It will be richer by including diverse multimodal esports information, including audiences' talks/emotions, game audio, and game match event information. This paper introduces GAME-MUG, a new multimodal game situation understanding and audience-engaged commentary generation dataset and its strong baseline. Our dataset is collected from 2020-2022 LOL game live streams from YouTube and Twitch, and includes multimodal esports game information, including text, audio, and time-series event logs, for detecting the game situation. In addition, we also propose a new audience conversation augmented commentary dataset by covering the game situation and audience conversation understanding, and introducing a robust joint multimodal dual learning model as a baseline. We examine the model's game situation/event understanding ability and commentary generation capability to show the effectiveness of the multimodal aspects coverage and the joint integration learning approach.
Create account to get full access
Overview
- The paper introduces a new multimodal dataset called GAME-MUG for understanding esports game situations and generating audience-engaged commentary.
- The dataset includes text, audio, and event log data from live esports streams, aiming to provide a more comprehensive understanding of the game situation beyond just the expert casters' commentary.
- The paper also proposes a new joint multimodal learning model as a baseline for the dataset, examining its ability to understand game events and generate relevant commentary.
Plain English Explanation
Watching esports, or competitive video gaming, can be challenging for average viewers to fully understand. This is because the commentary provided by expert casters, while helpful, doesn't always give a complete picture of what's happening in the game. The paper introduces a new dataset called GAME-MUG that aims to provide a richer understanding of esports games by incorporating additional information beyond just the casters' commentary.
The dataset includes text, audio, and time-series event logs from live esports streams, covering things like the audience's reactions and conversations, as well as detailed information about the events and actions happening in the game. By combining these different types of data, the researchers believe they can develop a more comprehensive understanding of the game situation and provide more engaging and informative commentary for viewers.
The paper also proposes a new machine learning model that can jointly process this multimodal data, understanding the game events and generating commentary that reflects the audience's perspective and engagement. This approach aims to create a more immersive and interactive viewing experience for esports fans.
Technical Explanation
The GAME-MUG dataset is collected from 2020-2022 League of Legends live streams on YouTube and Twitch. It includes text transcripts of the casters' commentary, audio recordings of the game audio and audience reactions, as well as time-series event logs that provide detailed information about the actions and events happening in the game.
The researchers propose a new joint multimodal learning model as a baseline for the dataset. This model is designed to process the different data modalities (text, audio, and event logs) and learn to both understand the game situation and generate relevant commentary that reflects the audience's perspective and engagement.
The paper evaluates the model's performance on two key tasks: 1) game situation and event understanding, and 2) generating audience-engaged commentary. The results demonstrate the effectiveness of the multimodal approach and the joint learning strategy in improving the system's overall understanding and commentary generation capabilities.
Critical Analysis
The paper makes a compelling case for the need to go beyond traditional caster-focused commentary in esports broadcasting, and the proposed GAME-MUG dataset and joint learning model represent a promising step in this direction.
However, the paper does not address some potential limitations or challenges that may arise in real-world deployment. For example, the dataset may not fully capture the diversity of esports audiences and their engagement patterns, and the joint learning approach may be computationally intensive or difficult to scale to larger datasets and more complex game scenarios.
Additionally, the paper does not discuss potential ethical considerations, such as the privacy implications of collecting and analyzing audience conversations, or the potential for the generated commentary to perpetuate biases or misrepresent the audience's sentiments.
Overall, the research presented in the paper is a valuable contribution to the field of multimodal understanding and generation for esports broadcasting, but further work is needed to address these potential limitations and ensure the responsible development and deployment of such systems.
Conclusion
This paper introduces a new multimodal dataset called GAME-MUG and a joint learning model for understanding esports game situations and generating audience-engaged commentary. The dataset includes a rich collection of text, audio, and event log data from live esports streams, going beyond the traditional caster-focused approach to provide a more comprehensive understanding of the game.
The proposed joint learning model demonstrates the effectiveness of processing this multimodal data to both understand the game events and generate commentary that reflects the audience's perspective and engagement. While the research represents an important step forward, further work is needed to address potential limitations and ensure the responsible development of such systems for enhancing the esports viewing experience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Commentary Generation from Data Records of Multiplayer Strategy Esports Game
Zihan Wang, Naoki Yoshinaga
0
0
Esports, a sports competition on video games, has become one of the most important sporting events. Although esports play logs have been accumulated, only a small portion of them accompany text commentaries for the audience to retrieve and understand the plays. In this study, we therefore introduce the task of generating game commentaries from esports' data records. We first build large-scale esports data-to-text datasets that pair structured data and commentaries from a popular esports game, League of Legends. We then evaluate Transformer-based models to generate game commentaries from structured data records, while examining the impact of the pre-trained language models. Evaluation results on our dataset revealed the challenges of this novel task. We will release our dataset to boost potential research in the data-to-text generation community.
5/9/2024
3M: Multi-modal Multi-task Multi-teacher Learning for Game Event Detection
Thye Shan Ng, Feiqi Cao, Soyeon Caren Han
0
0
Esports has rapidly emerged as a global phenomenon with an ever-expanding audience via platforms, like YouTube. Due to the inherent complexity nature of the game, it is challenging for newcomers to comprehend what the event entails. The chaotic nature of online chat, the fast-paced speech of the game commentator, and the game-specific user interface further compound the difficulty for users in comprehending the gameplay. To overcome these challenges, it is crucial to integrate the Multi-Modal (MM) information from the platform and understand the event. The paper introduces a new MM multi-teacher-based game event detection framework, with the ultimate goal of constructing a comprehensive framework that enhances the comprehension of the ongoing game situation. While conventional MM models typically prioritise aligning MM data through concurrent training towards a unified objective, our framework leverages multiple teachers trained independently on different tasks to accomplish the Game Event Detection. The experiment clearly shows the effectiveness of the proposed MM multi-teacher framework.
6/14/2024
💬
Language and Multimodal Models in Sports: A Survey of Datasets and Applications
Haotian Xia, Zhengbang Yang, Yun Zhao, Yuqing Wang, Jingxi Li, Rhys Tracy, Zhuangdi Zhu, Yuan-fang Wang, Hanjie Chen, Weining Shen
0
0
Recent integration of Natural Language Processing (NLP) and multimodal models has advanced the field of sports analytics. This survey presents a comprehensive review of the datasets and applications driving these innovations post-2020. We overviewed and categorized datasets into three primary types: language-based, multimodal, and convertible datasets. Language-based and multimodal datasets are for tasks involving text or multimodality (e.g., text, video, audio), respectively. Convertible datasets, initially single-modal (video), can be enriched with additional annotations, such as explanations of actions and video descriptions, to become multimodal, offering future potential for richer and more diverse applications. Our study highlights the contributions of these datasets to various applications, from improving fan experiences to supporting tactical analysis and medical diagnostics. We also discuss the challenges and future directions in dataset development, emphasizing the need for diverse, high-quality data to support real-time processing and personalized user experiences. This survey provides a foundational resource for researchers and practitioners aiming to leverage NLP and multimodal models in sports, offering insights into current trends and future opportunities in the field.
6/19/2024
🧪
MemeMQA: Multimodal Question Answering for Memes via Rationale-Based Inferencing
Siddhant Agarwal, Shivam Sharma, Preslav Nakov, Tanmoy Chakraborty
0
0
Memes have evolved as a prevalent medium for diverse communication, ranging from humour to propaganda. With the rising popularity of image-focused content, there is a growing need to explore its potential harm from different aspects. Previous studies have analyzed memes in closed settings - detecting harm, applying semantic labels, and offering natural language explanations. To extend this research, we introduce MemeMQA, a multimodal question-answering framework aiming to solicit accurate responses to structured questions while providing coherent explanations. We curate MemeMQACorpus, a new dataset featuring 1,880 questions related to 1,122 memes with corresponding answer-explanation pairs. We further propose ARSENAL, a novel two-stage multimodal framework that leverages the reasoning capabilities of LLMs to address MemeMQA. We benchmark MemeMQA using competitive baselines and demonstrate its superiority - ~18% enhanced answer prediction accuracy and distinct text generation lead across various metrics measuring lexical and semantic alignment over the best baseline. We analyze ARSENAL's robustness through diversification of question-set, confounder-based evaluation regarding MemeMQA's generalizability, and modality-specific assessment, enhancing our understanding of meme interpretation in the multimodal communication landscape.
5/21/2024