Can only LLMs do Reasoning?: Potential of Small Language Models in Task Planning
2404.03891
0
0
Abstract
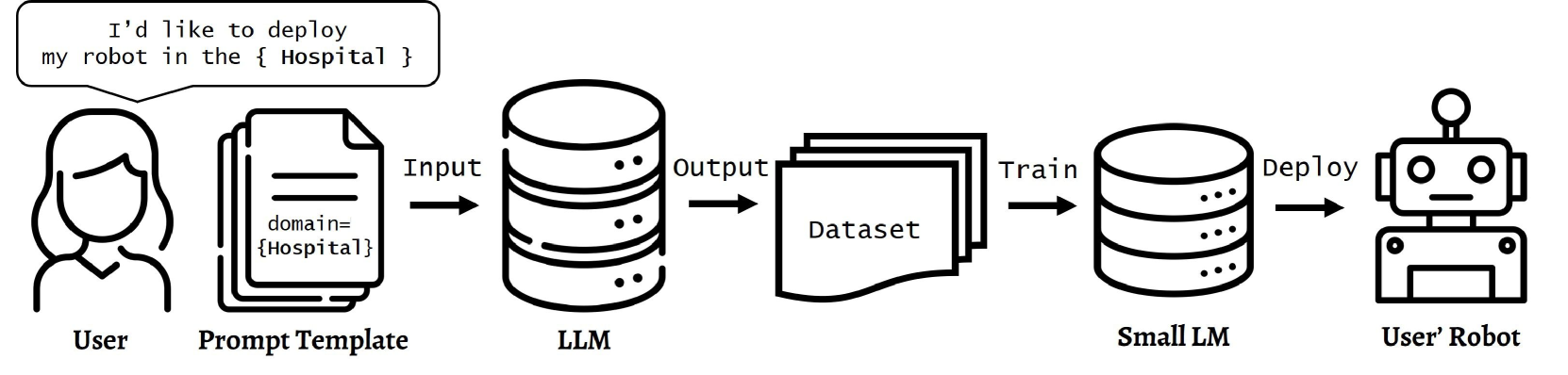
In robotics, the use of Large Language Models (LLMs) is becoming prevalent, especially for understanding human commands. In particular, LLMs are utilized as domain-agnostic task planners for high-level human commands. LLMs are capable of Chain-of-Thought (CoT) reasoning, and this allows LLMs to be task planners. However, we need to consider that modern robots still struggle to perform complex actions, and the domains where robots can be deployed are limited in practice. This leads us to pose a question: If small LMs can be trained to reason in chains within a single domain, would even small LMs be good task planners for the robots? To train smaller LMs to reason in chains, we build `COmmand-STeps datasets' (COST) consisting of high-level commands along with corresponding actionable low-level steps, via LLMs. We release not only our datasets but also the prompt templates used to generate them, to allow anyone to build datasets for their domain. We compare GPT3.5 and GPT4 with the finetuned GPT2 for task domains, in tabletop and kitchen environments, and the result shows that GPT2-medium is comparable to GPT3.5 for task planning in a specific domain. Our dataset, code, and more output samples can be found in https://github.com/Gawon-Choi/small-LMs-Task-Planning
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the potential of small language models (SLMs) in task planning, challenging the prevailing belief that only large language models (LLMs) are capable of reasoning.
- The authors investigate whether SLMs can effectively perform planning tasks, which typically require complex reasoning abilities often attributed only to LLMs.
- The research aims to provide insights into the capabilities of SLMs and their potential use cases, particularly in domains where resource-constrained models may be more practical.
Plain English Explanation
The paper examines whether small language models (SLMs) - which are generally less complex and have fewer parameters than large language models (LLMs) - can be used for task planning. Task planning is the process of determining a sequence of actions to achieve a specific goal, and it's often seen as a complex task that requires advanced reasoning abilities.
Traditionally, it's been assumed that only the powerful LLMs are capable of this type of complex reasoning. However, the researchers in this paper wanted to explore whether SLMs, which are more compact and efficient, could also be effective at task planning. This could be important in situations where resource-constrained models are preferred, such as on edge devices or in low-power applications.
The paper investigates the capabilities of SLMs in task planning and compares their performance to that of LLMs. The goal is to provide a better understanding of the potential of SLMs and challenge the prevailing assumption that only LLMs can handle complex reasoning tasks. This relates to the broader question of whether LLMs are truly "superhuman" in all domains.
Technical Explanation
The paper presents a series of experiments designed to assess the task planning capabilities of SLMs compared to LLMs. The authors use a set of benchmark planning tasks, including classic AI planning problems and robotics-inspired tasks, to evaluate the models' performance.
The researchers experiment with different SLM architectures, including transformer-based models and recurrent neural networks, and compare their results to those of state-of-the-art LLMs. The planning tasks involve generating a sequence of actions to achieve a specific goal, such as navigating a maze or assembling an object.
The paper's key findings suggest that SLMs can indeed perform well on these planning tasks, often matching or even exceeding the performance of larger LLMs. The authors attribute this to the SLMs' ability to effectively capture the necessary reasoning and abstraction capabilities required for task planning, despite their smaller size and parameter count.
The paper also explores the potential of using SLMs in multi-agent coordination scenarios, where the models need to reason about the actions and goals of multiple agents to plan effectively.
Critical Analysis
While the paper presents promising results for the capabilities of SLMs in task planning, the authors acknowledge several caveats and areas for further research. For example, the paper focuses on a limited set of benchmark tasks, and it's unclear how the models would perform on more complex, real-world planning problems.
Additionally, the paper does not delve deeply into the specific mechanisms or architectural features that enable SLMs to excel at task planning. Further research is needed to better understand the underlying factors that contribute to the SLMs' reasoning abilities.
There are also open questions about the generalizability of these findings, particularly in relation to the broader discussion around the capabilities of LLMs. The paper's results suggest that SLMs may be more capable than previously believed, but more comprehensive evaluations across diverse domains would be necessary to fully assess their potential.
Conclusion
The paper offers a compelling challenge to the prevailing assumption that only large language models (LLMs) are capable of complex reasoning tasks, such as task planning. The researchers demonstrate that smaller, more resource-efficient language models (SLMs) can also perform well on a range of planning benchmarks, often matching or exceeding the performance of their larger counterparts.
These findings have important implications for the development and deployment of AI systems, particularly in scenarios where resource constraints or computational efficiency are critical factors. The paper's insights suggest that SLMs could be a viable alternative to LLMs in certain applications, potentially expanding the reach and accessibility of advanced AI capabilities.
While the paper presents a promising first step, more research is needed to fully understand the capabilities and limitations of SLMs in task planning and other complex reasoning tasks. Nonetheless, this work contributes to the growing body of evidence that challenges the notion of LLMs as the sole arbiters of advanced reasoning, opening up new avenues for exploration in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
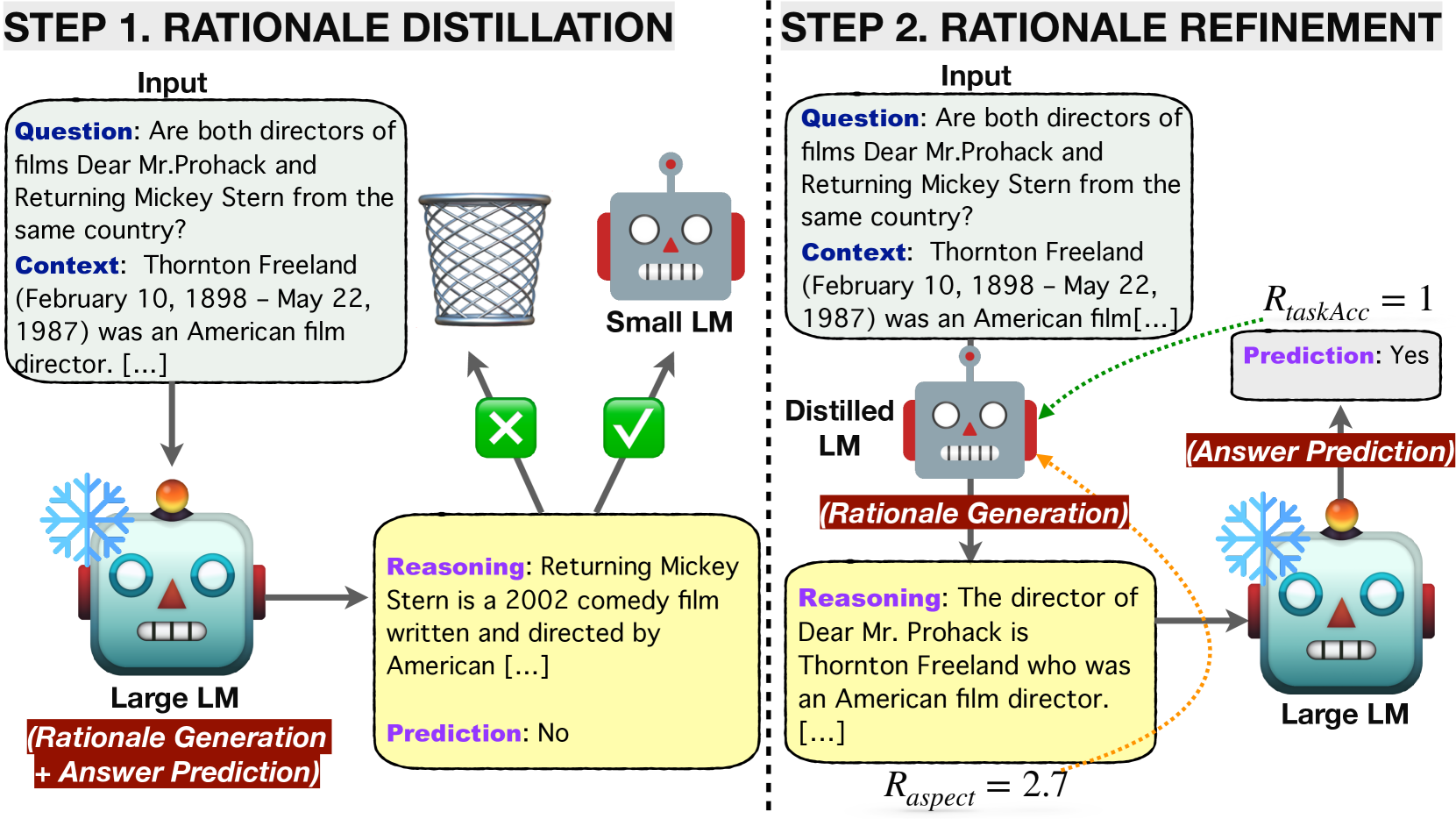
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
0
0
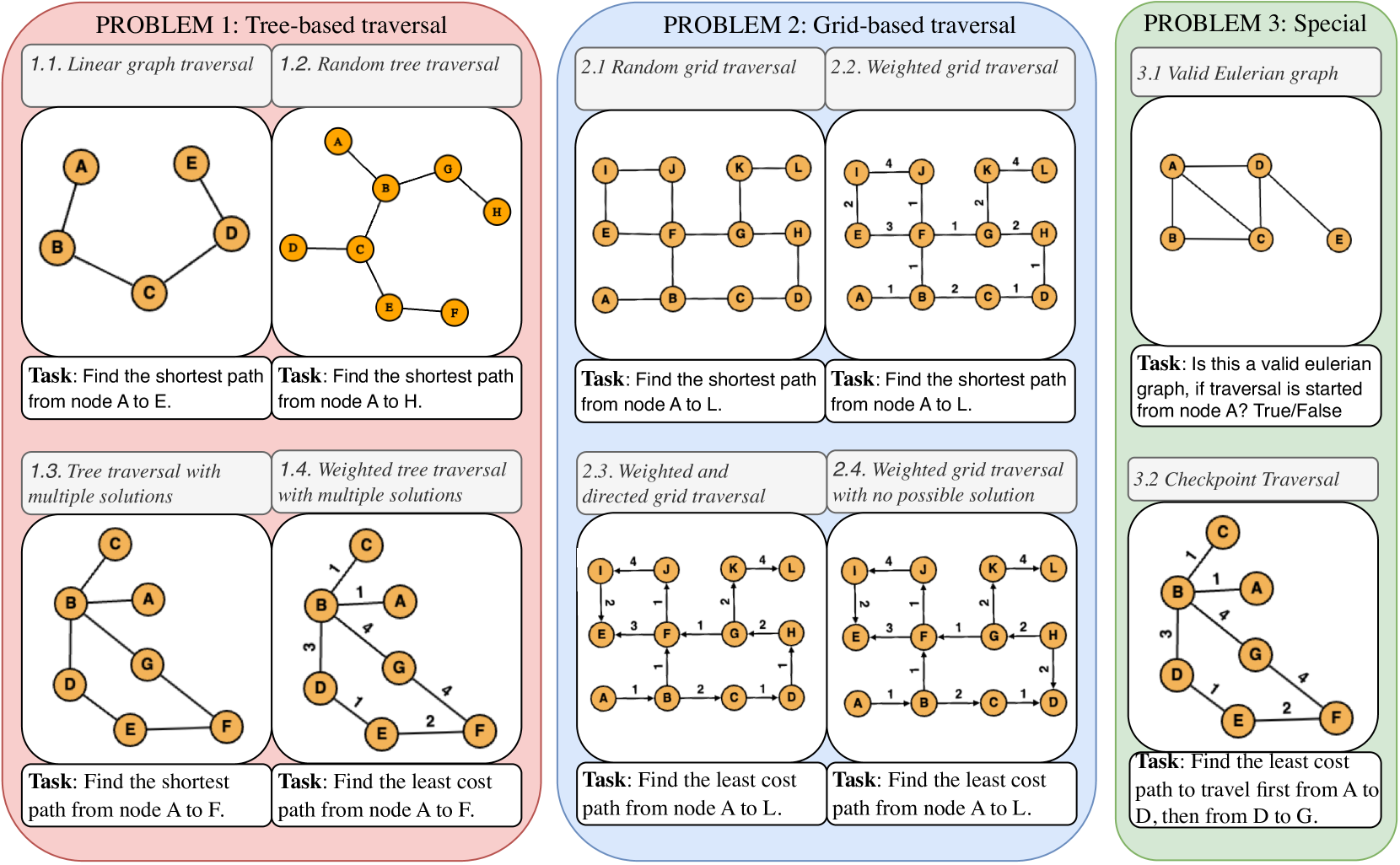
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
4/19/2024
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
0
0
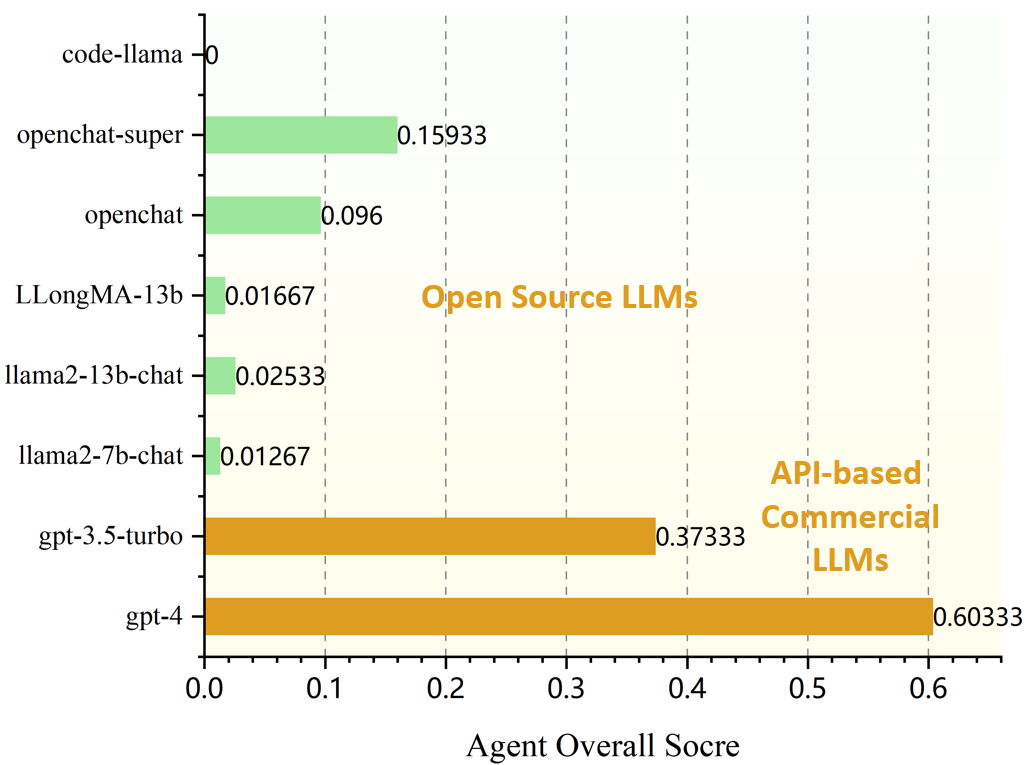
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
4/1/2024
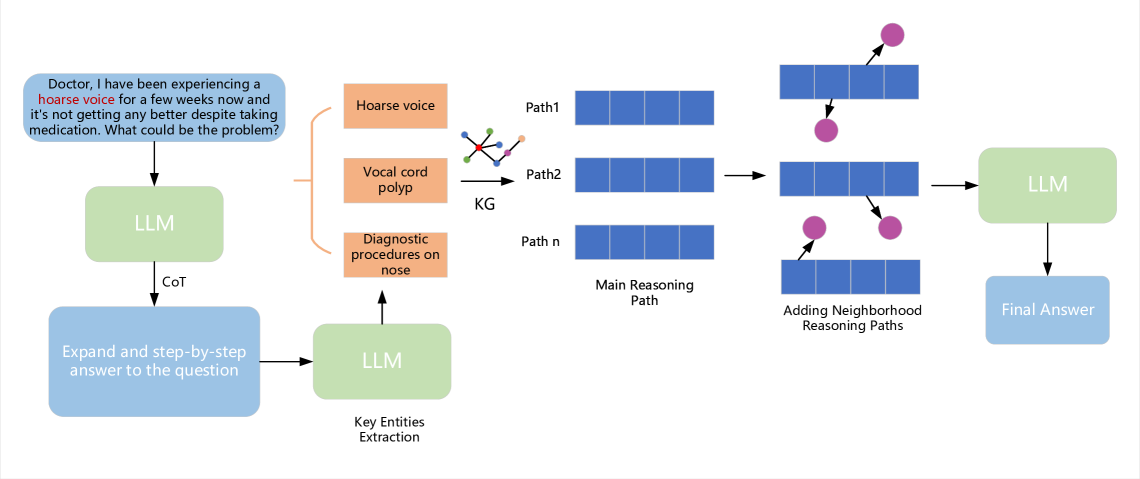
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024