garak: A Framework for Security Probing Large Language Models
2406.11036
2
0

Abstract
As Large Language Models (LLMs) are deployed and integrated into thousands of applications, the need for scalable evaluation of how models respond to adversarial attacks grows rapidly. However, LLM security is a moving target: models produce unpredictable output, are constantly updated, and the potential adversary is highly diverse: anyone with access to the internet and a decent command of natural language. Further, what constitutes a security weak in one context may not be an issue in a different context; one-fits-all guardrails remain theoretical. In this paper, we argue that it is time to rethink what constitutes ``LLM security'', and pursue a holistic approach to LLM security evaluation, where exploration and discovery of issues are central. To this end, this paper introduces garak (Generative AI Red-teaming and Assessment Kit), a framework which can be used to discover and identify vulnerabilities in a target LLM or dialog system. garak probes an LLM in a structured fashion to discover potential vulnerabilities. The outputs of the framework describe a target model's weaknesses, contribute to an informed discussion of what composes vulnerabilities in unique contexts, and can inform alignment and policy discussions for LLM deployment.
Create account to get full access
Overview
- Introduces a framework called "garak" for probing the security vulnerabilities of large language models (LLMs)
- Includes techniques for generating adversarial prompts and evaluating LLM responses to assess their robustness and security
- Explores how LLMs can be misused for malicious purposes, and how to safeguard against such threats
Plain English Explanation
The paper presents a framework called "garak" that allows researchers to thoroughly test the security of large language models (LLMs) - advanced AI systems that can generate human-like text. LLMs have become increasingly powerful and widespread, but they can also be vulnerable to misuse, such as generating misinformation or being exploited by bad actors.
The "garak" framework provides a way to probe these vulnerabilities by generating adversarial prompts - carefully crafted inputs designed to trick the LLM into producing harmful or unintended outputs. By evaluating how the LLM responds to these prompts, researchers can assess the model's robustness and identify potential security weaknesses.
This is an important area of research, as LLMs are becoming more prominent in a wide range of applications, from content generation to cybersecurity and beyond. Understanding the potential security risks of these models, and developing ways to mitigate them, is crucial for ensuring they are used safely and responsibly.
Technical Explanation
The paper introduces a framework called "garak" that provides a structured approach for probing the security vulnerabilities of large language models (LLMs). The key components of the framework include:
-
Prompt Generation: The framework can generate a diverse set of adversarial prompts - carefully crafted inputs designed to elicit harmful or unintended responses from the LLM. These prompts target various security aspects, such as the generation of misinformation, hate speech, or code exploits.
-
Response Evaluation: The framework evaluates the LLM's responses to the adversarial prompts, assessing factors like toxicity, factual accuracy, and security implications. This allows researchers to identify potential vulnerabilities and the LLM's overall robustness.
-
Mitigation Strategies: The paper also explores potential mitigation strategies, such as using filtering techniques or fine-tuning the LLM on curated datasets, to improve the model's security and reduce the risk of misuse.
The researchers demonstrate the effectiveness of the "garak" framework through a series of experiments on popular LLMs, including GPT-3 and DALL-E. The results highlight the ability of the framework to uncover a range of security vulnerabilities, providing valuable insights for the development of more secure and trustworthy LLMs.
Critical Analysis
The paper provides a comprehensive and well-designed framework for probing the security vulnerabilities of large language models (LLMs). The researchers have thoughtfully considered the potential risks and misuses of these powerful AI systems, and have developed a systematic approach to identify and mitigate these issues.
One potential limitation of the research is that it focuses primarily on the security aspects of LLMs, without delving deeply into the broader ethical and societal implications of these technologies. While the paper touches on the importance of developing secure and responsible LLMs, further research could explore the wider ramifications of LLM usage, such as the impact on content moderation, disinformation, and privacy.
Additionally, the paper could benefit from a more in-depth discussion of the limitations and challenges of the "garak" framework itself. While the researchers mention potential mitigation strategies, there may be other factors or considerations that could impact the effectiveness of the framework in real-world scenarios.
Overall, the "garak" framework represents a valuable contribution to the growing body of research on the security and responsible development of large language models. By continuing to explore these important issues, researchers can help ensure that these powerful AI systems are used in a safe and ethical manner.
Conclusion
The "garak" framework introduced in this paper provides a comprehensive approach for probing the security vulnerabilities of large language models (LLMs). By generating adversarial prompts and evaluating the LLM's responses, researchers can identify potential weaknesses and develop mitigation strategies to improve the robustness and security of these AI systems.
As LLMs become more prevalent in a wide range of applications, understanding and addressing their security risks is crucial. The "garak" framework offers a valuable tool for researchers and developers to assess the security of LLMs, contributing to the broader goal of ensuring these powerful AI systems are used in a safe and responsible manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring Vulnerabilities and Protections in Large Language Models: A Survey
Frank Weizhen Liu, Chenhui Hu
0
0
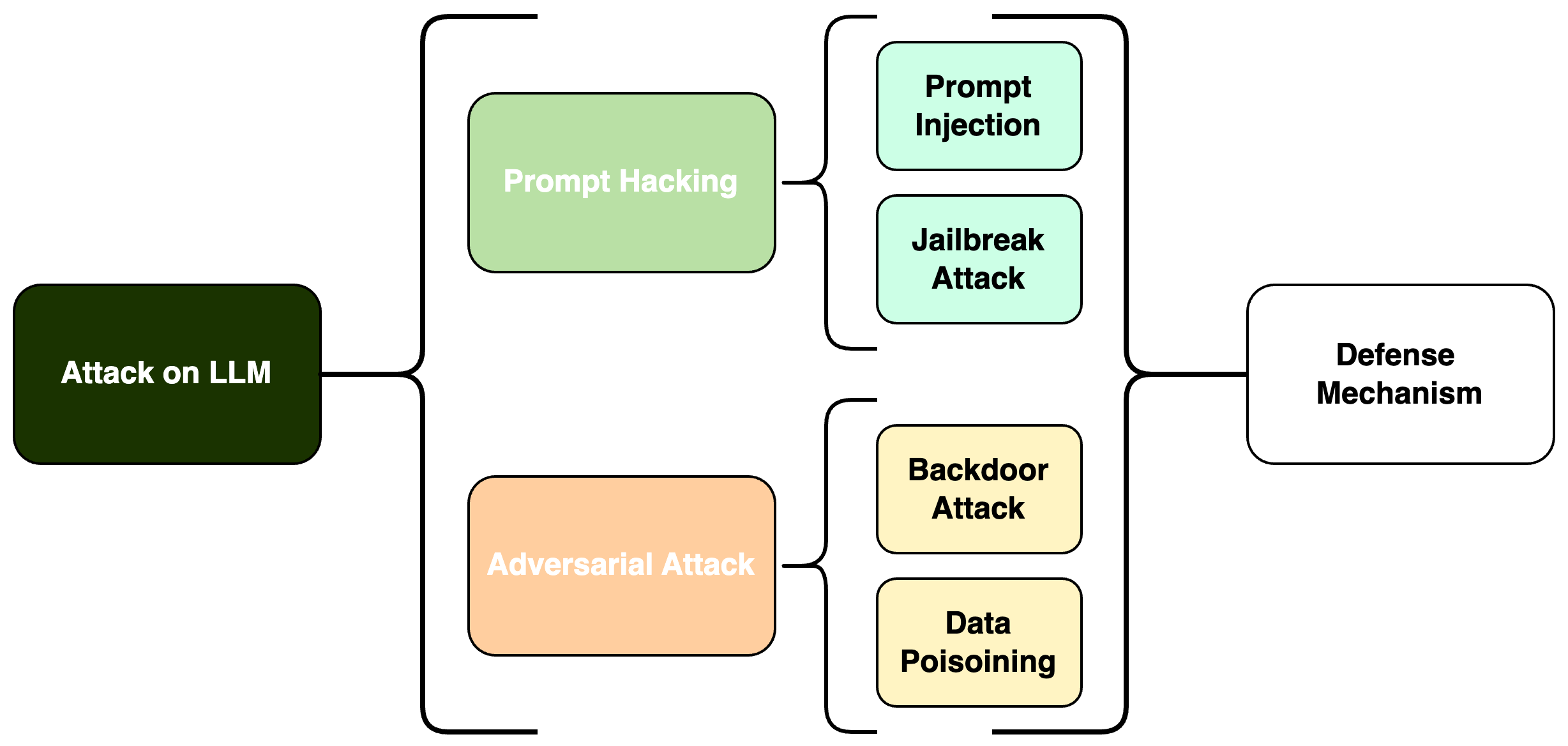
As Large Language Models (LLMs) increasingly become key components in various AI applications, understanding their security vulnerabilities and the effectiveness of defense mechanisms is crucial. This survey examines the security challenges of LLMs, focusing on two main areas: Prompt Hacking and Adversarial Attacks, each with specific types of threats. Under Prompt Hacking, we explore Prompt Injection and Jailbreaking Attacks, discussing how they work, their potential impacts, and ways to mitigate them. Similarly, we analyze Adversarial Attacks, breaking them down into Data Poisoning Attacks and Backdoor Attacks. This structured examination helps us understand the relationships between these vulnerabilities and the defense strategies that can be implemented. The survey highlights these security challenges and discusses robust defensive frameworks to protect LLMs against these threats. By detailing these security issues, the survey contributes to the broader discussion on creating resilient AI systems that can resist sophisticated attacks.
6/4/2024
🤖
Generative AI and Large Language Models for Cyber Security: All Insights You Need
Mohamed Amine Ferrag, Fatima Alwahedi, Ammar Battah, Bilel Cherif, Abdechakour Mechri, Norbert Tihanyi
0
0
This paper provides a comprehensive review of the future of cybersecurity through Generative AI and Large Language Models (LLMs). We explore LLM applications across various domains, including hardware design security, intrusion detection, software engineering, design verification, cyber threat intelligence, malware detection, and phishing detection. We present an overview of LLM evolution and its current state, focusing on advancements in models such as GPT-4, GPT-3.5, Mixtral-8x7B, BERT, Falcon2, and LLaMA. Our analysis extends to LLM vulnerabilities, such as prompt injection, insecure output handling, data poisoning, DDoS attacks, and adversarial instructions. We delve into mitigation strategies to protect these models, providing a comprehensive look at potential attack scenarios and prevention techniques. Furthermore, we evaluate the performance of 42 LLM models in cybersecurity knowledge and hardware security, highlighting their strengths and weaknesses. We thoroughly evaluate cybersecurity datasets for LLM training and testing, covering the lifecycle from data creation to usage and identifying gaps for future research. In addition, we review new strategies for leveraging LLMs, including techniques like Half-Quadratic Quantization (HQQ), Reinforcement Learning with Human Feedback (RLHF), Direct Preference Optimization (DPO), Quantized Low-Rank Adapters (QLoRA), and Retrieval-Augmented Generation (RAG). These insights aim to enhance real-time cybersecurity defenses and improve the sophistication of LLM applications in threat detection and response. Our paper provides a foundational understanding and strategic direction for integrating LLMs into future cybersecurity frameworks, emphasizing innovation and robust model deployment to safeguard against evolving cyber threats.
5/22/2024
🤖
Current state of LLM Risks and AI Guardrails
Suriya Ganesh Ayyamperumal, Limin Ge
0
0
Large language models (LLMs) have become increasingly sophisticated, leading to widespread deployment in sensitive applications where safety and reliability are paramount. However, LLMs have inherent risks accompanying them, including bias, potential for unsafe actions, dataset poisoning, lack of explainability, hallucinations, and non-reproducibility. These risks necessitate the development of guardrails to align LLMs with desired behaviors and mitigate potential harm. This work explores the risks associated with deploying LLMs and evaluates current approaches to implementing guardrails and model alignment techniques. We examine intrinsic and extrinsic bias evaluation methods and discuss the importance of fairness metrics for responsible AI development. The safety and reliability of agentic LLMs (those capable of real-world actions) are explored, emphasizing the need for testability, fail-safes, and situational awareness. Technical strategies for securing LLMs are presented, including a layered protection model operating at external, secondary, and internal levels. System prompts, Retrieval-Augmented Generation (RAG) architectures, and techniques to minimize bias and protect privacy are highlighted. Effective guardrail design requires a deep understanding of the LLM's intended use case, relevant regulations, and ethical considerations. Striking a balance between competing requirements, such as accuracy and privacy, remains an ongoing challenge. This work underscores the importance of continuous research and development to ensure the safe and responsible use of LLMs in real-world applications.
6/21/2024
Safeguarding Large Language Models: A Survey
Yi Dong, Ronghui Mu, Yanghao Zhang, Siqi Sun, Tianle Zhang, Changshun Wu, Gaojie Jin, Yi Qi, Jinwei Hu, Jie Meng, Saddek Bensalem, Xiaowei Huang
0
0
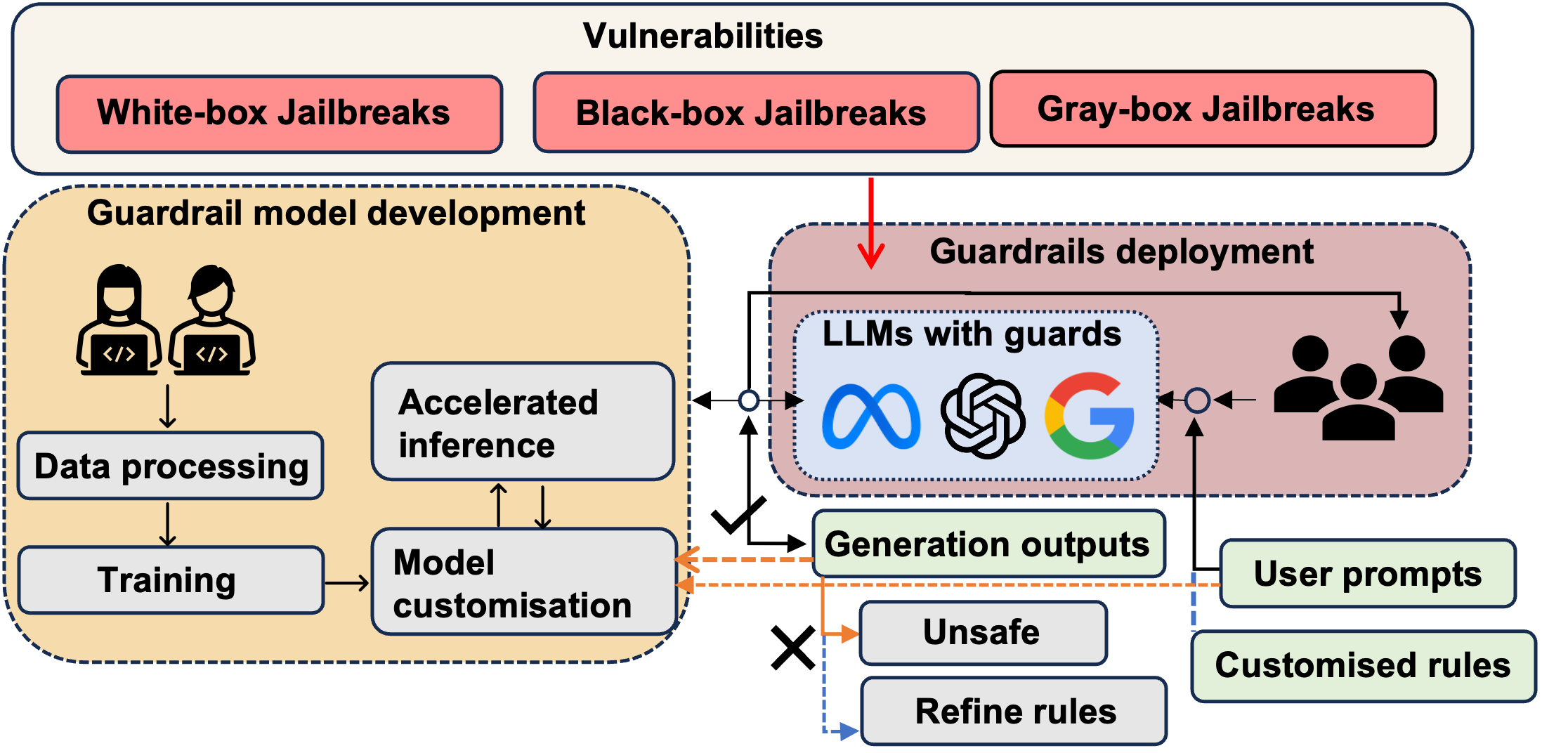
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as safeguards or guardrails, has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
6/6/2024