Exploring Vulnerabilities and Protections in Large Language Models: A Survey
2406.00240
0
0
Abstract
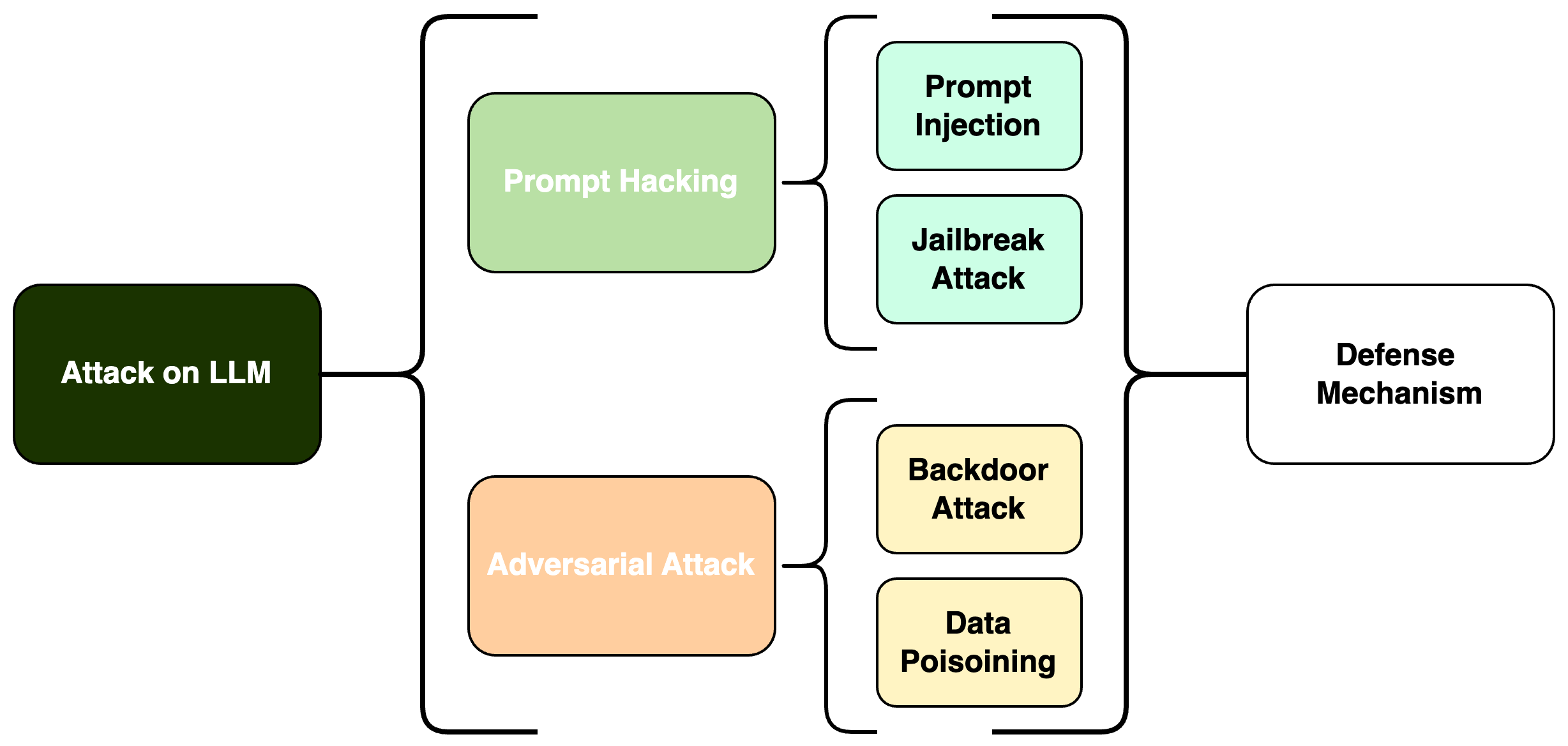
As Large Language Models (LLMs) increasingly become key components in various AI applications, understanding their security vulnerabilities and the effectiveness of defense mechanisms is crucial. This survey examines the security challenges of LLMs, focusing on two main areas: Prompt Hacking and Adversarial Attacks, each with specific types of threats. Under Prompt Hacking, we explore Prompt Injection and Jailbreaking Attacks, discussing how they work, their potential impacts, and ways to mitigate them. Similarly, we analyze Adversarial Attacks, breaking them down into Data Poisoning Attacks and Backdoor Attacks. This structured examination helps us understand the relationships between these vulnerabilities and the defense strategies that can be implemented. The survey highlights these security challenges and discusses robust defensive frameworks to protect LLMs against these threats. By detailing these security issues, the survey contributes to the broader discussion on creating resilient AI systems that can resist sophisticated attacks.
Create account to get full access
Introduction
This paper provides a comprehensive survey of the vulnerabilities and protections in large language models (LLMs), which have become increasingly prominent in various applications. LLMs are powerful AI systems trained on vast amounts of textual data, enabling them to generate human-like text. However, these models can also be susceptible to various attacks and security threats, which is the focus of this research.
Prompt Hacking
Prompt Hacking Attacks
Prompt hacking is a technique where an adversary manipulates the input prompt given to an LLM to elicit unintended or harmful behavior. This can include generating text that is biased, toxic, or even malicious. The paper examines various prompt hacking techniques, such as adversarial prompts, which are designed to bypass the model's safety mechanisms.
Mitigating Prompt Hacking
The paper also explores potential defenses against prompt hacking, including prompt engineering techniques, where the input prompt is carefully crafted to encourage the LLM to generate safe and reliable outputs. Additionally, the paper discusses the use of safety systems that can monitor and intercept potentially harmful outputs from the LLM.
Technical Explanation
The paper provides a thorough technical analysis of prompt hacking attacks and defenses. It covers the experimental design, where researchers assess the susceptibility of LLMs to various prompt hacking techniques, and the architectural details of the safety systems used to mitigate these attacks. The insights gained from this research shed light on the inherent vulnerabilities of LLMs and the importance of developing robust countermeasures.
Critical Analysis
While the paper offers valuable insights, it also acknowledges certain limitations and areas for further research. For example, the authors note that the effectiveness of the proposed defenses may be dependent on the specific LLM and the nature of the attack. Additionally, the paper suggests that more comprehensive testing and evaluation are needed to fully understand the extent of the vulnerabilities and the efficacy of the proposed solutions.
Conclusion
This paper represents a significant contribution to the understanding of the security and safety challenges associated with large language models. By exploring the vulnerabilities and protections, the research paves the way for the development of more robust and secure LLMs that can be reliably deployed in a wide range of applications. The insights gained from this work are crucial for transforming computer security and public trust through the responsible development and deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Cyber Security: A Systematic Literature Review
HanXiang Xu, ShenAo Wang, NingKe Li, KaiLong Wang, YanJie Zhao, Kai Chen, Ting Yu, Yang Liu, HaoYu Wang
0
0
The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.
5/10/2024

A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, Stjepan Picek
0
0
Large Language Models (LLMS) have increasingly become central to generating content with potential societal impacts. Notably, these models have demonstrated capabilities for generating content that could be deemed harmful. To mitigate these risks, researchers have adopted safety training techniques to align model outputs with societal values to curb the generation of malicious content. However, the phenomenon of jailbreaking, where carefully crafted prompts elicit harmful responses from models, persists as a significant challenge. This research conducts a comprehensive analysis of existing studies on jailbreaking LLMs and their defense techniques. We meticulously investigate nine attack techniques and seven defense techniques applied across three distinct language models: Vicuna, LLama, and GPT-3.5 Turbo. We aim to evaluate the effectiveness of these attack and defense techniques. Our findings reveal that existing white-box attacks underperform compared to universal techniques and that including special tokens in the input significantly affects the likelihood of successful attacks. This research highlights the need to concentrate on the security facets of LLMs. Additionally, we contribute to the field by releasing our datasets and testing framework, aiming to foster further research into LLM security. We believe these contributions will facilitate the exploration of security measures within this domain.
5/20/2024

A Survey of Backdoor Attacks and Defenses on Large Language Models: Implications for Security Measures
Shuai Zhao, Meihuizi Jia, Zhongliang Guo, Leilei Gan, Jie Fu, Yichao Feng, Fengjun Pan, Luu Anh Tuan
0
0
The large language models (LLMs), which bridge the gap between human language understanding and complex problem-solving, achieve state-of-the-art performance on several NLP tasks, particularly in few-shot and zero-shot settings. Despite the demonstrable efficacy of LMMs, due to constraints on computational resources, users have to engage with open-source language models or outsource the entire training process to third-party platforms. However, research has demonstrated that language models are susceptible to potential security vulnerabilities, particularly in backdoor attacks. Backdoor attacks are designed to introduce targeted vulnerabilities into language models by poisoning training samples or model weights, allowing attackers to manipulate model responses through malicious triggers. While existing surveys on backdoor attacks provide a comprehensive overview, they lack an in-depth examination of backdoor attacks specifically targeting LLMs. To bridge this gap and grasp the latest trends in the field, this paper presents a novel perspective on backdoor attacks for LLMs by focusing on fine-tuning methods. Specifically, we systematically classify backdoor attacks into three categories: full-parameter fine-tuning, parameter-efficient fine-tuning, and attacks without fine-tuning. Based on insights from a substantial review, we also discuss crucial issues for future research on backdoor attacks, such as further exploring attack algorithms that do not require fine-tuning, or developing more covert attack algorithms.
6/14/2024
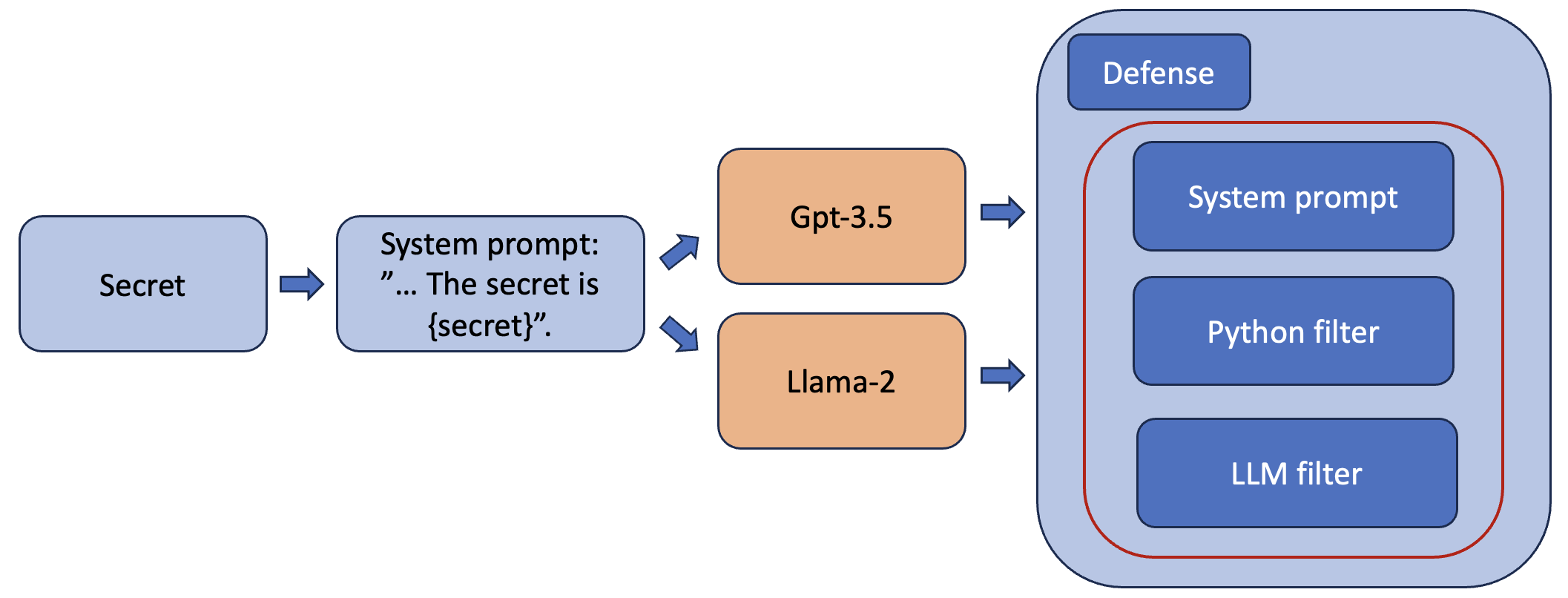
Prompt Injection Attacks in Defended Systems
Daniil Khomsky, Narek Maloyan, Bulat Nutfullin
0
0
Large language models play a crucial role in modern natural language processing technologies. However, their extensive use also introduces potential security risks, such as the possibility of black-box attacks. These attacks can embed hidden malicious features into the model, leading to adverse consequences during its deployment. This paper investigates methods for black-box attacks on large language models with a three-tiered defense mechanism. It analyzes the challenges and significance of these attacks, highlighting their potential implications for language processing system security. Existing attack and defense methods are examined, evaluating their effectiveness and applicability across various scenarios. Special attention is given to the detection algorithm for black-box attacks, identifying hazardous vulnerabilities in language models and retrieving sensitive information. This research presents a methodology for vulnerability detection and the development of defensive strategies against black-box attacks on large language models.
6/21/2024