GaussianHeads: End-to-End Learning of Drivable Gaussian Head Avatars from Coarse-to-fine Representations

0

Sign in to get full access
Overview
- This paper introduces GaussianHeads, an end-to-end learning framework for creating drivable Gaussian head avatars from coarse-to-fine representations.
- The key ideas are to use Gaussian splatting and implicit representations to model volumetric head avatars, and to learn these avatars in an end-to-end fashion from diverse data.
- The goal is to enable realistic free-viewpoint rendering of human heads that can be driven by speech, facial expressions, and other inputs.
Plain English Explanation
The paper presents a new method called GaussianHeads for creating realistic 3D digital avatars of human heads. These avatars can be animated and viewed from different angles, allowing for free-viewpoint rendering.
The key innovation is the use of Volumetric Rendering and 3D Gaussian Splatting to model the head geometry and appearance. This allows the system to learn an Implicit Representation of the head that can be efficiently rendered from any viewpoint.
The system is trained in an End-to-End fashion using a diverse dataset, enabling it to produce high-quality, controllable head avatars. These avatars can then be 'driven' by inputs like speech or facial expressions, allowing for applications like virtual communication, gaming, and animation.
Technical Explanation
The paper introduces a new approach called GaussianHeads for learning drivable 3D head avatars from data. The key technical components are:
-
Volumetric Rendering: The system models the head as a volumetric 3D object, rather than a traditional surface mesh. This allows for more flexible and realistic rendering.
-
3D Gaussian Splatting: Instead of discretizing the volume into voxels, GaussianHeads represents the head as a set of 3D Gaussian primitives. This provides a more efficient and smooth representation.
-
Implicit Representations: The system learns an implicit function to represent the head geometry and appearance, rather than an explicit 3D mesh. This enables free-viewpoint rendering.
-
End-to-End Learning: GaussianHeads is trained in an end-to-end fashion, directly mapping from input data (e.g. images, scans) to the final drivable avatar representation. This avoids the need for complex multi-stage pipelines.
The paper demonstrates the effectiveness of this approach through extensive experiments, showing that GaussianHeads can produce high-quality, controllable head avatars from diverse training data.
Critical Analysis
The paper presents a compelling approach for learning 3D head avatars that can be efficiently rendered and driven by various inputs. The use of volumetric representations, Gaussian splatting, and implicit functions seems well-justified and enables flexible, high-quality results.
However, the paper does not fully address potential limitations or areas for further research. For example, the training data and evaluation scenarios are primarily focused on neutral head poses and expressions. It's unclear how well the system would handle more expressive, emotive, or occluded facial configurations.
Additionally, the paper does not discuss the computational and memory requirements of the learned models, which could be an important practical consideration for real-world deployment. Further benchmarking and analysis in this area would be valuable.
Overall, the GaussianHeads framework appears to be a significant advancement in the field of neural avatars and free-viewpoint rendering. With further research and refinement, it could enable a new generation of immersive virtual communication and entertainment experiences.
Conclusion
This paper introduces GaussianHeads, a novel end-to-end framework for learning drivable 3D head avatars from diverse data. By leveraging volumetric representations, Gaussian splatting, and implicit functions, the system can produce high-quality, free-viewpoint renderings of human heads that can be controlled by inputs like speech and facial expressions.
The technical innovations and experimental results suggest that GaussianHeads represents an important step forward in the field of neural avatars and volumetric rendering. With further development, this technology could enable a wide range of applications in virtual communication, gaming, animation, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GaussianHeads: End-to-End Learning of Drivable Gaussian Head Avatars from Coarse-to-fine Representations
Kartik Teotia, Hyeongwoo Kim, Pablo Garrido, Marc Habermann, Mohamed Elgharib, Christian Theobalt
Real-time rendering of human head avatars is a cornerstone of many computer graphics applications, such as augmented reality, video games, and films, to name a few. Recent approaches address this challenge with computationally efficient geometry primitives in a carefully calibrated multi-view setup. Albeit producing photorealistic head renderings, it often fails to represent complex motion changes such as the mouth interior and strongly varying head poses. We propose a new method to generate highly dynamic and deformable human head avatars from multi-view imagery in real-time. At the core of our method is a hierarchical representation of head models that allows to capture the complex dynamics of facial expressions and head movements. First, with rich facial features extracted from raw input frames, we learn to deform the coarse facial geometry of the template mesh. We then initialize 3D Gaussians on the deformed surface and refine their positions in a fine step. We train this coarse-to-fine facial avatar model along with the head pose as a learnable parameter in an end-to-end framework. This enables not only controllable facial animation via video inputs, but also high-fidelity novel view synthesis of challenging facial expressions, such as tongue deformations and fine-grained teeth structure under large motion changes. Moreover, it encourages the learned head avatar to generalize towards new facial expressions and head poses at inference time. We demonstrate the performance of our method with comparisons against the related methods on different datasets, spanning challenging facial expression sequences across multiple identities. We also show the potential application of our approach by demonstrating a cross-identity facial performance transfer application.
Read more9/19/2024
0
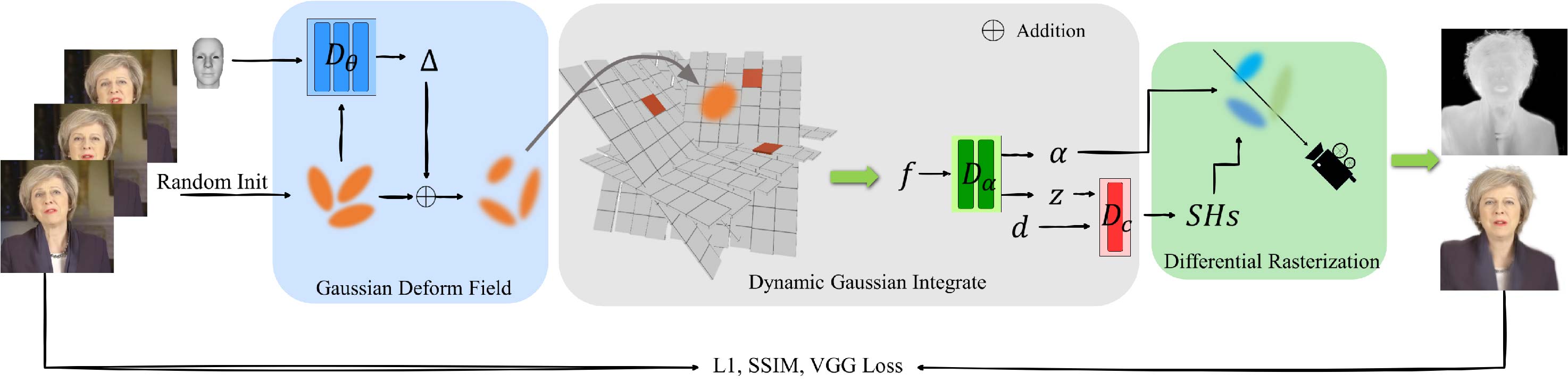
GaussianHead: High-fidelity Head Avatars with Learnable Gaussian Derivation
Jie Wang, Jiu-Cheng Xie, Xianyan Li, Feng Xu, Chi-Man Pun, Hao Gao
Constructing vivid 3D head avatars for given subjects and realizing a series of animations on them is valuable yet challenging. This paper presents GaussianHead, which models the actional human head with anisotropic 3D Gaussians. In our framework, a motion deformation field and multi-resolution tri-plane are constructed respectively to deal with the head's dynamic geometry and complex texture. Notably, we impose an exclusive derivation scheme on each Gaussian, which generates its multiple doppelgangers through a set of learnable parameters for position transformation. With this design, we can compactly and accurately encode the appearance information of Gaussians, even those fitting the head's particular components with sophisticated structures. In addition, an inherited derivation strategy for newly added Gaussians is adopted to facilitate training acceleration. Extensive experiments show that our method can produce high-fidelity renderings, outperforming state-of-the-art approaches in reconstruction, cross-identity reenactment, and novel view synthesis tasks. Our code is available at: https://github.com/chiehwangs/gaussian-head.
Read more5/31/2024

0
3D Gaussian Parametric Head Model
Yuelang Xu, Lizhen Wang, Zerong Zheng, Zhaoqi Su, Yebin Liu
Creating high-fidelity 3D human head avatars is crucial for applications in VR/AR, telepresence, digital human interfaces, and film production. Recent advances have leveraged morphable face models to generate animated head avatars from easily accessible data, representing varying identities and expressions within a low-dimensional parametric space. However, existing methods often struggle with modeling complex appearance details, e.g., hairstyles and accessories, and suffer from low rendering quality and efficiency. This paper introduces a novel approach, 3D Gaussian Parametric Head Model, which employs 3D Gaussians to accurately represent the complexities of the human head, allowing precise control over both identity and expression. Additionally, it enables seamless face portrait interpolation and the reconstruction of detailed head avatars from a single image. Unlike previous methods, the Gaussian model can handle intricate details, enabling realistic representations of varying appearances and complex expressions. Furthermore, this paper presents a well-designed training framework to ensure smooth convergence, providing a guarantee for learning the rich content. Our method achieves high-quality, photo-realistic rendering with real-time efficiency, making it a valuable contribution to the field of parametric head models.
Read more7/23/2024
0
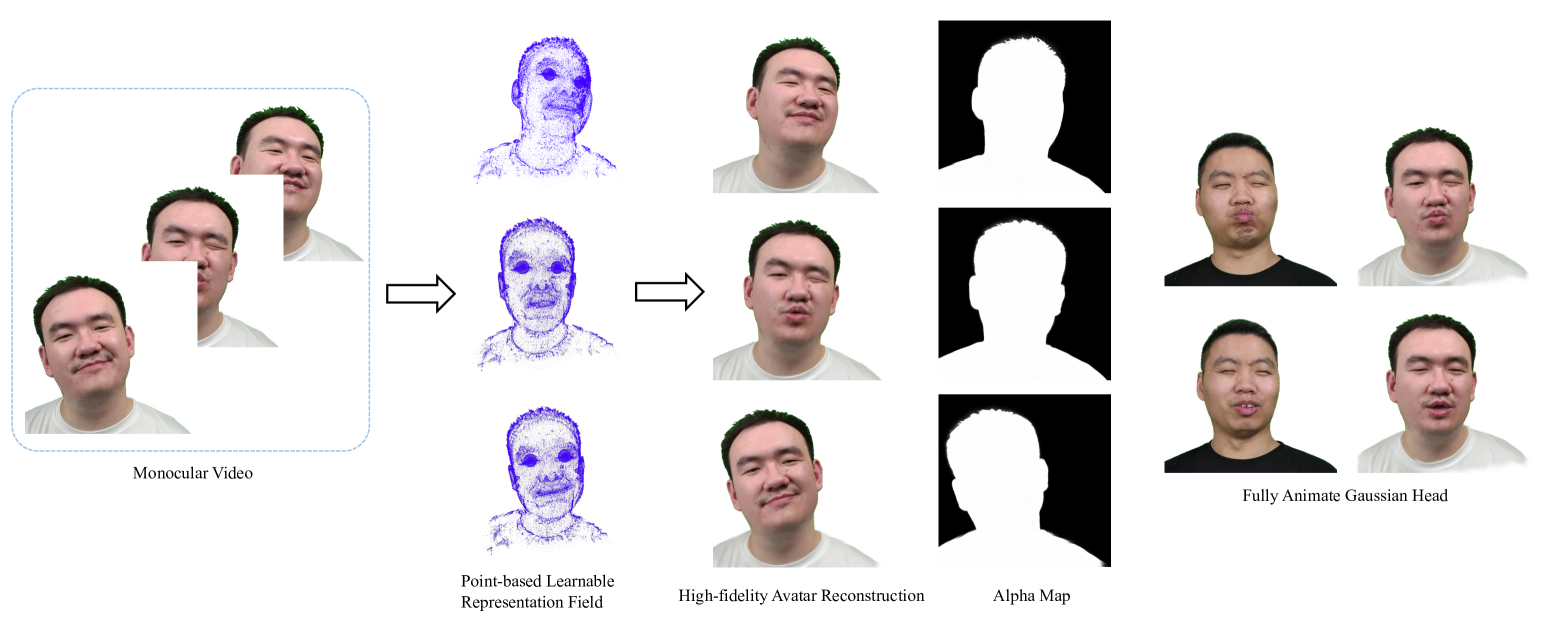
FAGhead: Fully Animate Gaussian Head from Monocular Videos
Yixin Xuan, Xinyang Li, Gongxin Yao, Shiwei Zhou, Donghui Sun, Xiaoxin Chen, Yu Pan
High-fidelity reconstruction of 3D human avatars has a wild application in visual reality. In this paper, we introduce FAGhead, a method that enables fully controllable human portraits from monocular videos. We explicit the traditional 3D morphable meshes (3DMM) and optimize the neutral 3D Gaussians to reconstruct with complex expressions. Furthermore, we employ a novel Point-based Learnable Representation Field (PLRF) with learnable Gaussian point positions to enhance reconstruction performance. Meanwhile, to effectively manage the edges of avatars, we introduced the alpha rendering to supervise the alpha value of each pixel. Extensive experimental results on the open-source datasets and our capturing datasets demonstrate that our approach is able to generate high-fidelity 3D head avatars and fully control the expression and pose of the virtual avatars, which is outperforming than existing works.
Read more7/1/2024