GazeNoter: Co-Piloted AR Note-Taking via Gaze Selection of LLM Suggestions to Match Users' Intentions

0

Sign in to get full access
Overview
- The paper proposes "GazeNoter", a co-piloted augmented reality (AR) note-taking system that leverages gaze selection of language model suggestions to match users' intentions.
- The system aims to enhance the note-taking process by providing relevant text suggestions based on the user's gaze, allowing for more efficient and intentional note-taking.
- The key components include gaze tracking, language model integration, and a co-piloting approach that blends user input with system suggestions.
Plain English Explanation
The paper introduces GazeNoter, a new way to take notes using augmented reality (AR) technology. The main idea is to track where the user is looking (their "gaze") and use that information to automatically suggest relevant text that the user can quickly select and add to their notes.
Imagine you're attending a lecture and trying to take notes. With GazeNoter, as you look at different parts of the presentation slides or the speaker, the system would detect what you're focusing on and offer relevant text suggestions that you could easily choose from to include in your notes. This helps make the note-taking process more efficient and tailored to your specific interests and needs.
The key components of GazeNoter are:
- Tracking the user's gaze to determine what they are looking at
- Using a language model (a type of artificial intelligence that can generate human-like text) to produce relevant text suggestions based on the user's gaze
- Blending the user's own input with the system's suggestions, allowing the user to maintain control over the note-taking process while benefiting from the AI's assistance
The goal is to create a "co-piloted" note-taking experience, where the user and the system work together to capture the most important information in an intuitive and personalized way.
Technical Explanation
The paper presents "GazeNoter", a system that combines gaze tracking, language models, and a co-piloting approach to enhance the AR note-taking experience.
The key technical components include:
- Gaze Tracking: The system uses eye-tracking technology to monitor the user's gaze and determine the specific elements (e.g., slides, speaker) they are focusing on during the note-taking process.
- Language Model Integration: A large language model (LLM) is integrated into the system to generate relevant text suggestions based on the user's gaze. The LLM is trained on a diverse corpus of information to provide contextually appropriate suggestions.
- Co-Piloting: The system blends the user's own note-taking input with the LLM's suggestions, allowing the user to maintain control over the process while benefiting from the AI's assistance. The user can selectively incorporate the system's suggestions into their notes.
The paper describes experiments that evaluate the effectiveness of GazeNoter in improving the efficiency and quality of note-taking compared to traditional methods. The results suggest that the co-piloted approach can enhance the user's note-taking experience by reducing cognitive load and increasing the relevance of the captured information.
Critical Analysis
The paper presents a promising approach to enhancing AR note-taking through the integration of gaze tracking and language model suggestions. However, there are a few potential limitations and areas for further research:
- Accuracy of Gaze Tracking: The effectiveness of the system relies heavily on the accuracy of the gaze tracking technology. Factors such as lighting conditions, user movement, and individual differences in eye physiology could impact the reliability of the gaze detection.
- Personalization of Language Model Suggestions: While the paper mentions the use of a general-purpose language model, it may be beneficial to explore ways to further personalize the suggestions to match the user's unique knowledge, interests, and note-taking style.
- Integration with Existing Note-Taking Workflows: The paper does not provide details on how GazeNoter might seamlessly integrate with users' existing note-taking workflows, such as integration with popular note-taking apps or productivity suites.
- Privacy and Data Considerations: The use of gaze tracking and language model suggestions raises potential privacy concerns, which the paper does not address. The handling and storage of user data should be carefully considered.
Future research could explore these areas to further refine and enhance the GazeNoter system, ensuring it provides a more robust and user-centric note-taking experience.
Conclusion
The GazeNoter system proposed in this paper represents a promising step towards improving the note-taking process in augmented reality environments. By leveraging gaze tracking and language model suggestions, the system aims to create a more efficient and personalized note-taking experience, where the user and the AI system work together to capture the most relevant information.
While the paper highlights several technical advancements and positive experimental results, there are also opportunities to address potential limitations and further refine the system. Continued research in areas such as gaze tracking accuracy, personalization of language model suggestions, and integration with existing note-taking workflows could help GazeNoter reach its full potential and provide a transformative note-taking solution for users in various settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GazeNoter: Co-Piloted AR Note-Taking via Gaze Selection of LLM Suggestions to Match Users' Intentions
Hsin-Ruey Tsai, Shih-Kang Chiu, Bryan Wang
Note-taking is critical during speeches and discussions, serving not only for later summarization and organization but also for real-time question and opinion reminding in question-and-answer sessions or timely contributions in discussions. Manually typing on smartphones for note-taking could be distracting and increase cognitive load for users. While large language models (LLMs) are used to automatically generate summaries and highlights, the content generated by artificial intelligence (AI) may not match users' intentions without user input or interaction. Therefore, we propose an AI-copiloted augmented reality (AR) system, GazeNoter, to allow users to swiftly select diverse LLM-generated suggestions via gaze on an AR headset for real-time note-taking. GazeNoter leverages an AR headset as a medium for users to swiftly adjust the LLM output to match their intentions, forming a user-in-the-loop AI system for both within-context and beyond-context notes. We conducted two user studies to verify the usability of GazeNoter in attending speeches in a static sitting condition and walking meetings and discussions in a mobile walking condition, respectively.
Read more7/2/2024

0
Augmented Conversation with Embedded Speech-Driven On-the-Fly Referencing in AR
Shivesh Jadon, Mehrad Faridan, Edward Mah, Rajan Vaish, Wesley Willett, Ryo Suzuki
This paper introduces the concept of augmented conversation, which aims to support co-located in-person conversations via embedded speech-driven on-the-fly referencing in augmented reality (AR). Today computing technologies like smartphones allow quick access to a variety of references during the conversation. However, these tools often create distractions, reducing eye contact and forcing users to focus their attention on phone screens and manually enter keywords to access relevant information. In contrast, AR-based on-the-fly referencing provides relevant visual references in real-time, based on keywords extracted automatically from the spoken conversation. By embedding these visual references in AR around the conversation partner, augmented conversation reduces distraction and friction, allowing users to maintain eye contact and supporting more natural social interactions. To demonstrate this concept, we developed system, a Hololens-based interface that leverages real-time speech recognition, natural language processing and gaze-based interactions for on-the-fly embedded visual referencing. In this paper, we explore the design space of visual referencing for conversations, and describe our our implementation -- building on seven design guidelines identified through a user-centered design process. An initial user study confirms that our system decreases distraction and friction in conversations compared to smartphone searches, while providing highly useful and relevant information.
Read more5/30/2024

0
GazePointAR: A Context-Aware Multimodal Voice Assistant for Pronoun Disambiguation in Wearable Augmented Reality
Jaewook Lee, Jun Wang, Elizabeth Brown, Liam Chu, Sebastian S. Rodriguez, Jon E. Froehlich
Voice assistants (VAs) like Siri and Alexa are transforming human-computer interaction; however, they lack awareness of users' spatiotemporal context, resulting in limited performance and unnatural dialogue. We introduce GazePointAR, a fully-functional context-aware VA for wearable augmented reality that leverages eye gaze, pointing gestures, and conversation history to disambiguate speech queries. With GazePointAR, users can ask what's over there? or how do I solve this math problem? simply by looking and/or pointing. We evaluated GazePointAR in a three-part lab study (N=12): (1) comparing GazePointAR to two commercial systems; (2) examining GazePointAR's pronoun disambiguation across three tasks; (3) and an open-ended phase where participants could suggest and try their own context-sensitive queries. Participants appreciated the naturalness and human-like nature of pronoun-driven queries, although sometimes pronoun use was counter-intuitive. We then iterated on GazePointAR and conducted a first-person diary study examining how GazePointAR performs in-the-wild. We conclude by enumerating limitations and design considerations for future context-aware VAs.
Read more4/15/2024
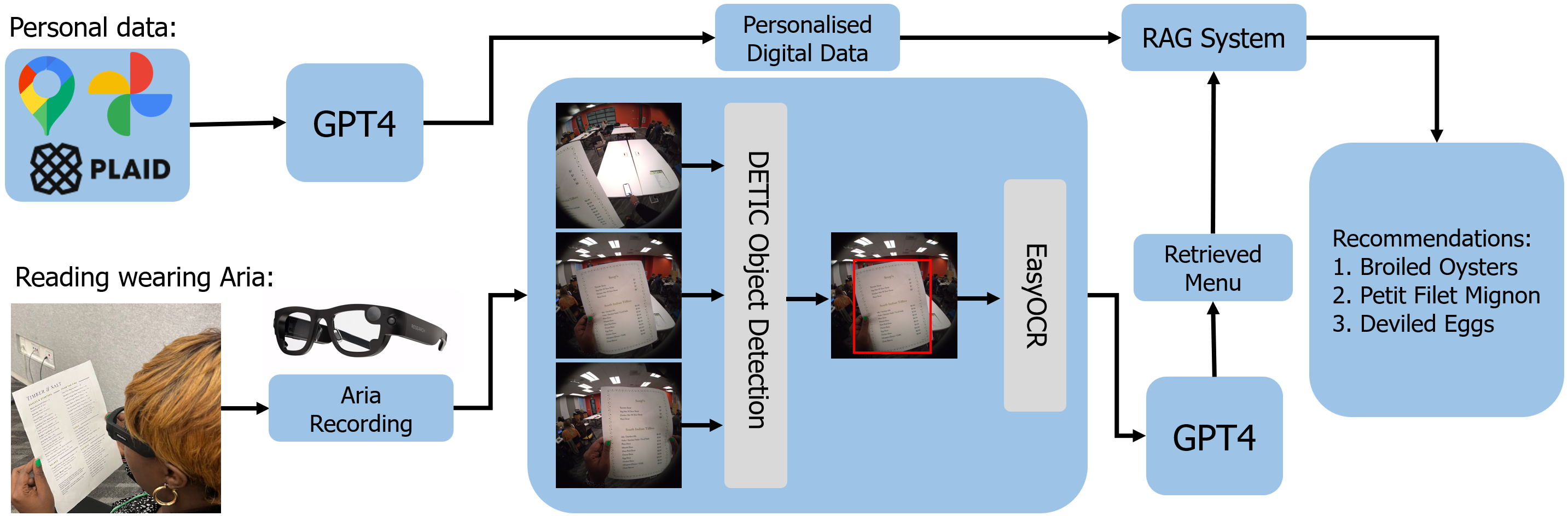
0
TEXT2TASTE: A Versatile Egocentric Vision System for Intelligent Reading Assistance Using Large Language Model
Wiktor Mucha, Florin Cuconasu, Naome A. Etori, Valia Kalokyri, Giovanni Trappolini
The ability to read, understand and find important information from written text is a critical skill in our daily lives for our independence, comfort and safety. However, a significant part of our society is affected by partial vision impairment, which leads to discomfort and dependency in daily activities. To address the limitations of this part of society, we propose an intelligent reading assistant based on smart glasses with embedded RGB cameras and a Large Language Model (LLM), whose functionality goes beyond corrective lenses. The video recorded from the egocentric perspective of a person wearing the glasses is processed to localise text information using object detection and optical character recognition methods. The LLM processes the data and allows the user to interact with the text and responds to a given query, thus extending the functionality of corrective lenses with the ability to find and summarize knowledge from the text. To evaluate our method, we create a chat-based application that allows the user to interact with the system. The evaluation is conducted in a real-world setting, such as reading menus in a restaurant, and involves four participants. The results show robust accuracy in text retrieval. The system not only provides accurate meal suggestions but also achieves high user satisfaction, highlighting the potential of smart glasses and LLMs in assisting people with special needs.
Read more4/16/2024