TEXT2TASTE: A Versatile Egocentric Vision System for Intelligent Reading Assistance Using Large Language Model
2404.09254
0
0
Abstract
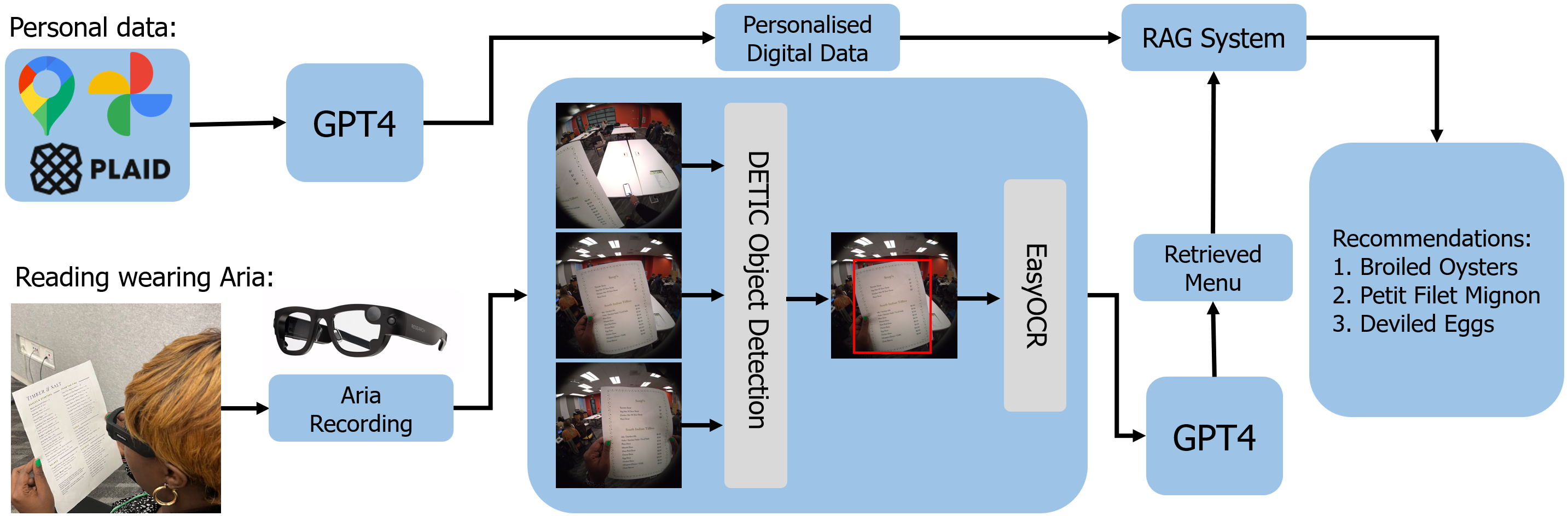
The ability to read, understand and find important information from written text is a critical skill in our daily lives for our independence, comfort and safety. However, a significant part of our society is affected by partial vision impairment, which leads to discomfort and dependency in daily activities. To address the limitations of this part of society, we propose an intelligent reading assistant based on smart glasses with embedded RGB cameras and a Large Language Model (LLM), whose functionality goes beyond corrective lenses. The video recorded from the egocentric perspective of a person wearing the glasses is processed to localise text information using object detection and optical character recognition methods. The LLM processes the data and allows the user to interact with the text and responds to a given query, thus extending the functionality of corrective lenses with the ability to find and summarize knowledge from the text. To evaluate our method, we create a chat-based application that allows the user to interact with the system. The evaluation is conducted in a real-world setting, such as reading menus in a restaurant, and involves four participants. The results show robust accuracy in text retrieval. The system not only provides accurate meal suggestions but also achieves high user satisfaction, highlighting the potential of smart glasses and LLMs in assisting people with special needs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents TEXT2TASTE, a versatile egocentric vision system that uses a large language model to provide intelligent reading assistance.
- The system is designed to help people with visual impairments or other reading difficulties by leveraging advanced computer vision and natural language processing techniques.
- The paper explores how this technology can be used to enhance the reading experience and improve accessibility for those who struggle with traditional print media.
Plain English Explanation
The researchers have developed a new system called TEXT2TASTE that aims to make reading easier for people who have trouble with traditional printed materials. The system uses a large language model and advanced camera technology to analyze what the user is looking at and provide helpful information or assistance.
For example, if the user is struggling to read a book or document, the system can detect the text, read it aloud, or provide a summary in simple language. It can also identify objects, colors, and other visual information and describe them to the user. This could be particularly useful for people with visual impairments or other disabilities that make reading challenging.
The goal of TEXT2TASTE is to leverage cutting-edge computer vision and natural language processing techniques to enhance the reading experience and improve accessibility for those who have difficulty with traditional print media. By using a large language model, the system can provide intelligent and context-aware assistance to users, tailoring its responses to their individual needs and preferences.
Technical Explanation
The TEXT2TASTE system is designed to leverage the capabilities of large language models (LLMs) to provide intelligent reading assistance in an egocentric vision setting. The researchers propose a novel architecture that integrates computer vision and natural language processing techniques to enable a range of helpful functionalities for users.
At the core of the system is a multimodal LLM that has been trained on a diverse dataset of text, images, and other modalities. This allows the model to understand and reason about the visual context of the user's environment, as well as the textual content they are attempting to read.
The system uses a wearable camera to capture the user's view of the world, and computer vision algorithms are employed to detect and extract relevant information, such as text, objects, and scene elements. This visual input is then passed to the LLM, which processes the information and generates appropriate responses or assistance for the user.
The researchers have designed a range of capabilities for the TEXT2TASTE system, including text extraction and reading, object and scene description, and personalized assistance based on the user's preferences and needs. The system can also leverage additional sensors and contextual information to further enhance the user experience, such as by providing real-time translations or explanations of technical terms.
Through extensive evaluation and user studies, the researchers have demonstrated the effectiveness of the TEXT2TASTE system in improving the reading experience and accessibility for individuals with visual impairments or other reading difficulties. The versatility and adaptability of the system make it a promising tool for enhancing the quality of life and independence of those who struggle with traditional print media.
Critical Analysis
The TEXT2TASTE system represents a significant advancement in the field of assistive technology, leveraging the power of large language models and computer vision to tackle the challenges faced by individuals with visual impairments or reading difficulties. The researchers have demonstrated the feasibility and potential of this approach through their extensive evaluation and user studies.
However, it is important to note that the technology is still in its early stages, and there are several areas that require further research and development. For example, the accuracy and reliability of the text extraction and object recognition algorithms may need to be improved, especially in more complex or dynamic environments.
Additionally, the researchers acknowledge the potential for privacy and security concerns, as the system requires the user to share their visual input with the LLM-based backend. Addressing these concerns through robust data protection and user control mechanisms will be crucial for the widespread adoption and trust in the technology.
Furthermore, the researchers mention the need to explore the personalization and adaptability of the system, ensuring that it can cater to the diverse needs and preferences of individual users. This may involve developing more advanced user modeling and preference learning capabilities within the LLM.
Despite these challenges, the TEXT2TASTE system represents a promising step forward in the field of assistive technology. By leveraging the power of large language models and computer vision, the researchers have demonstrated the potential to enhance the reading experience and improve accessibility for those who have traditionally faced barriers in accessing printed information. Continued research and development in this area could lead to transformative advancements in the quality of life and independence for people with visual impairments or other reading difficulties.
Conclusion
The TEXT2TASTE system presented in this paper is a significant contribution to the field of assistive technology, demonstrating the potential of large language models and computer vision to enhance the reading experience and improve accessibility for individuals with visual impairments or other reading difficulties.
By integrating advanced natural language processing and computer vision techniques, the researchers have developed a versatile system that can provide a range of helpful functionalities, from text extraction and reading to object and scene description. The system's ability to adapt to the user's preferences and needs, as well as leverage additional sensors and contextual information, makes it a promising tool for improving the quality of life and independence of those who struggle with traditional print media.
While the technology is still in its early stages and faces some challenges, the critical analysis suggests that continued research and development in this area could lead to transformative advancements in assistive technology. The TEXT2TASTE system represents an important step forward in leveraging the power of artificial intelligence to create more inclusive and accessible experiences for all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, Evangelos Kanoulas
0
0
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
4/30/2024
Training a Vision Language Model as Smartphone Assistant
Nicolai Dorka, Janusz Marecki, Ammar Anwar
0
0
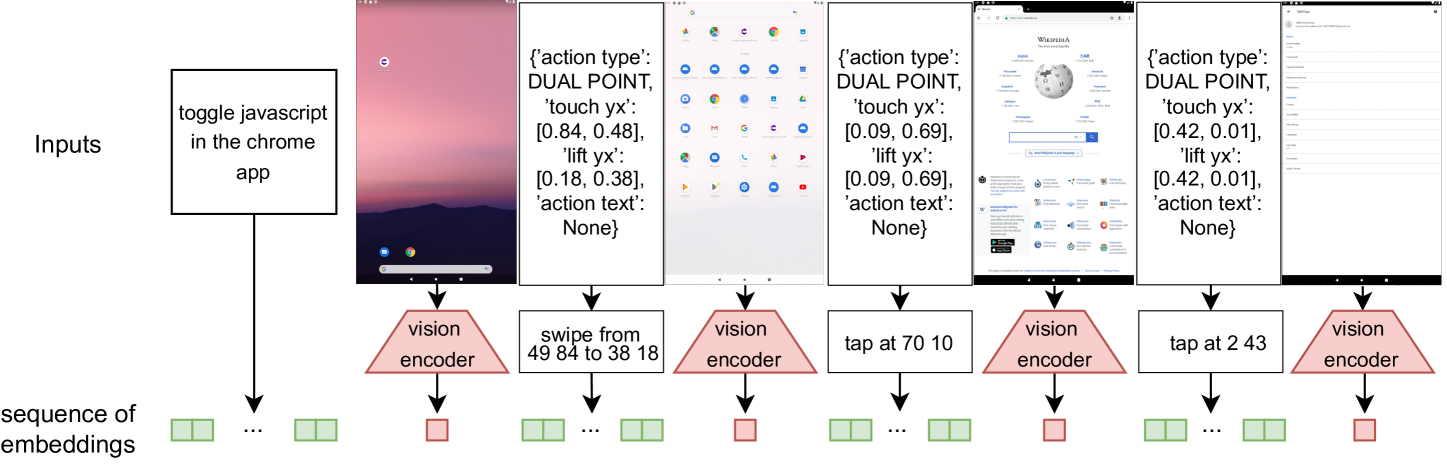
Addressing the challenge of a digital assistant capable of executing a wide array of user tasks, our research focuses on the realm of instruction-based mobile device control. We leverage recent advancements in large language models (LLMs) and present a visual language model (VLM) that can fulfill diverse tasks on mobile devices. Our model functions by interacting solely with the user interface (UI). It uses the visual input from the device screen and mimics human-like interactions, encompassing gestures such as tapping and swiping. This generality in the input and output space allows our agent to interact with any application on the device. Unlike previous methods, our model operates not only on a single screen image but on vision-language sentences created from sequences of past screenshots along with corresponding actions. Evaluating our method on the challenging Android in the Wild benchmark demonstrates its promising efficacy and potential.
4/16/2024
Beyond Human Vision: The Role of Large Vision Language Models in Microscope Image Analysis
Prateek Verma, Minh-Hao Van, Xintao Wu
0
0
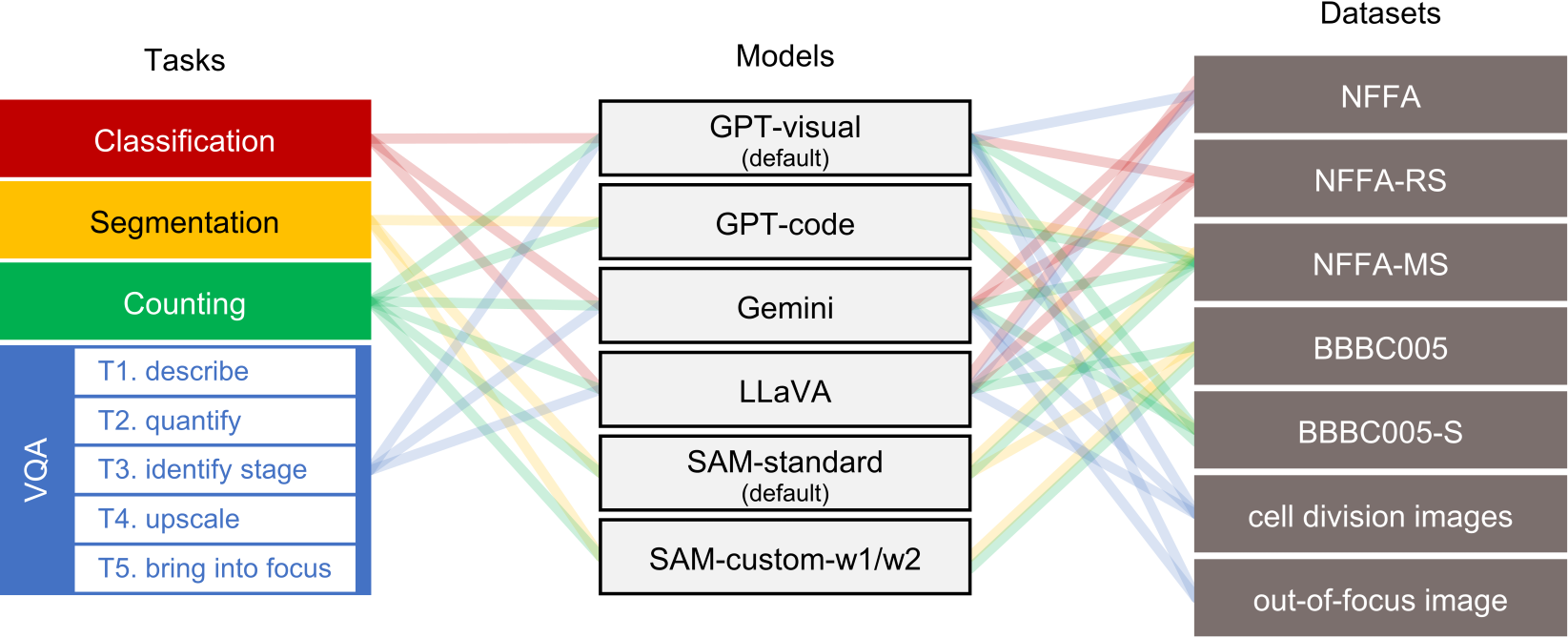
Vision language models (VLMs) have recently emerged and gained the spotlight for their ability to comprehend the dual modality of image and textual data. VLMs such as LLaVA, ChatGPT-4, and Gemini have recently shown impressive performance on tasks such as natural image captioning, visual question answering (VQA), and spatial reasoning. Additionally, a universal segmentation model by Meta AI, Segment Anything Model (SAM) shows unprecedented performance at isolating objects from unforeseen images. Since medical experts, biologists, and materials scientists routinely examine microscopy or medical images in conjunction with textual information in the form of captions, literature, or reports, and draw conclusions of great importance and merit, it is indubitably essential to test the performance of VLMs and foundation models such as SAM, on these images. In this study, we charge ChatGPT, LLaVA, Gemini, and SAM with classification, segmentation, counting, and VQA tasks on a variety of microscopy images. We observe that ChatGPT and Gemini are impressively able to comprehend the visual features in microscopy images, while SAM is quite capable at isolating artefacts in a general sense. However, the performance is not close to that of a domain expert - the models are readily encumbered by the introduction of impurities, defects, artefact overlaps and diversity present in the images.
5/3/2024
Contextual Emotion Recognition using Large Vision Language Models
Yasaman Etesam, Ozge Nilay Yalc{c}{i}n, Chuxuan Zhang, Angelica Lim
0
0
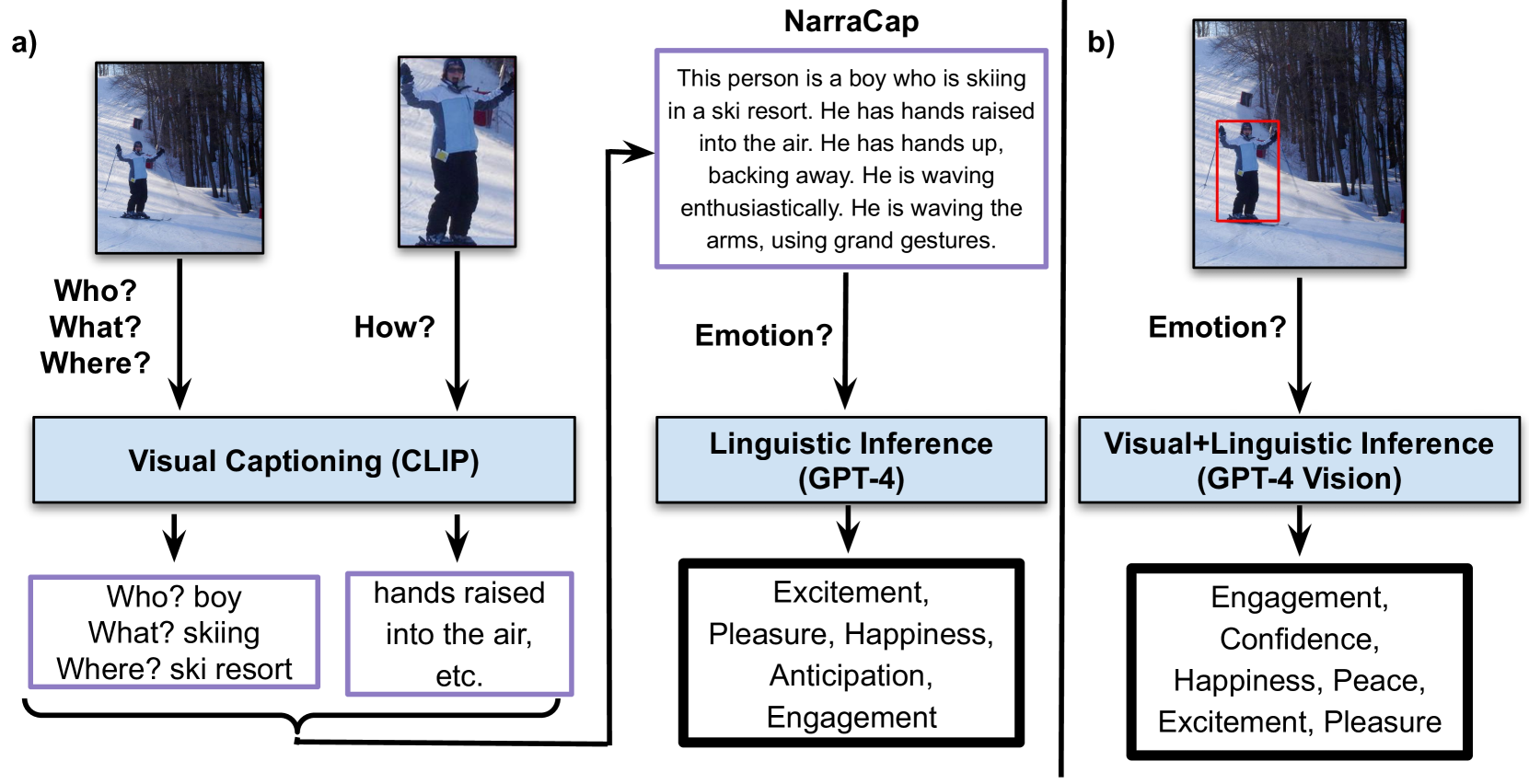
How does the person in the bounding box feel? Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
5/16/2024