GD doesn't make the cut: Three ways that non-differentiability affects neural network training
2401.08426
0
0
🧠
Abstract
This paper investigates the distinctions between gradient methods applied to non-differentiable functions (NGDMs) and classical gradient descents (GDs) designed for differentiable functions. First, we demonstrate significant differences in the convergence properties of NGDMs compared to GDs, challenging the applicability of the extensive neural network convergence literature based on $L-smoothness$ to non-smooth neural networks. Next, we demonstrate the paradoxical nature of NGDM solutions for $L_{1}$-regularized problems, showing that increasing the regularization penalty leads to an increase in the $L_{1}$ norm of optimal solutions in NGDMs. Consequently, we show that widely adopted $L_{1}$ penalization-based techniques for network pruning do not yield expected results. Additionally, we dispel the common belief that optimization algorithms like Adam and RMSProp perform similarly in non-differentiable contexts. Finally, we explore the Edge of Stability phenomenon, indicating its inapplicability even to Lipschitz continuous convex differentiable functions, leaving its relevance to non-convex non-differentiable neural networks inconclusive. Our analysis exposes misguided interpretations of NGDMs in widely referenced papers and texts due to an overreliance on strong smoothness assumptions, emphasizing the necessity for a nuanced understanding of foundational assumptions in the analysis of these systems.
Create account to get full access
Overview
- This paper investigates the differences between gradient methods applied to non-differentiable functions (NGDMs) and classical gradient descents (GDs) designed for differentiable functions.
- It challenges the widely held assumption that the extensive convergence literature on neural networks, based on Lipschitz smoothness, applies to non-smooth neural networks.
- The paper exposes paradoxical behaviors of NGDM solutions for L1-regularized problems and shows that widely adopted L1 penalization-based techniques for network pruning do not yield expected results.
- It also dispels the common belief that optimization algorithms like Adam and RMSProp perform similarly in non-differentiable contexts.
- Finally, the paper explores the Edge of Stability phenomenon, indicating its inapplicability to Lipschitz continuous convex differentiable functions and leaving its relevance to non-convex non-differentiable neural networks inconclusive.
Plain English Explanation
The paper looks at the differences between two types of optimization methods: those designed for smooth, differentiable functions (gradient descent) and those used for non-smooth, non-differentiable functions (non-gradient descent methods or NGDMs). The researchers find that the extensive research on the convergence of neural networks, which assumes the functions are smooth, does not apply to neural networks with non-smooth components.
They also discover some paradoxical behaviors when using NGDMs on problems with L1 regularization (a common technique for network pruning). Surprisingly, increasing the regularization penalty can actually increase the L1 norm of the optimal solution, contrary to expectations. This means that the widely used L1 penalization-based pruning methods may not work as well as assumed.
The paper also shows that popular optimization algorithms like Adam and RMSProp, which work well for smooth functions, behave quite differently in non-differentiable contexts.
Finally, the researchers explore a phenomenon called the "Edge of Stability," which was thought to be relevant even for Lipschitz continuous convex differentiable functions. However, the paper suggests that this may not be the case, and its relevance to the more complex case of non-convex non-differentiable neural networks remains uncertain.
Overall, the paper highlights the importance of understanding the underlying assumptions and limitations of optimization methods, especially when applying them to the complex, non-smooth functions that arise in modern machine learning models.
Technical Explanation
The paper begins by demonstrating significant differences in the convergence properties of NGDMs compared to classical gradient descents (GDs) designed for differentiable functions. This challenges the widespread assumption that the extensive literature on the convergence of neural networks, which is based on Lipschitz smoothness, can be applied to non-smooth neural networks.
Next, the researchers investigate the paradoxical nature of NGDM solutions for L1-regularized problems. They show that increasing the regularization penalty can lead to an increase in the L1 norm of the optimal solutions. This finding contradicts the common belief that L1 penalization-based techniques, such as those used for network pruning, will yield the expected results.
Additionally, the paper dispels the common assumption that optimization algorithms like Adam and RMSProp perform similarly in non-differentiable contexts, as they do in the differentiable case.
Finally, the researchers explore the Edge of Stability phenomenon, which was thought to be relevant even for Lipschitz continuous convex differentiable functions. However, the paper indicates that this assumption may not hold, leaving the relevance of the Edge of Stability to non-convex non-differentiable neural networks inconclusive.
Throughout the analysis, the paper exposes misguided interpretations of NGDMs in widely referenced papers and texts due to an overreliance on strong smoothness assumptions. This emphasizes the necessity for a nuanced understanding of the foundational assumptions in the analysis of these systems.
Critical Analysis
The paper raises important concerns about the widespread applicability of the extensive literature on neural network convergence, which is based on the assumption of Lipschitz smoothness. By demonstrating significant differences in the convergence properties of NGDMs compared to GDs, the authors challenge this assumption and highlight the need for a more nuanced understanding of optimization methods for non-smooth neural networks.
The findings regarding the paradoxical behavior of NGDM solutions for L1-regularized problems are particularly concerning, as they suggest that widely adopted network pruning techniques may not yield the expected results. This is a crucial insight that could have significant implications for the development of efficient and effective neural network architectures.
While the paper explores the Edge of Stability phenomenon, the authors acknowledge the inconclusiveness of its relevance to non-convex non-differentiable neural networks. This highlights the need for further research to fully understand the implications of this phenomenon in the context of modern machine learning models.
One potential limitation of the study is the scope of the analysis, which may not capture the full complexity of real-world neural network architectures and training scenarios. Additionally, the paper does not provide specific recommendations or alternative approaches for addressing the issues it identifies, leaving room for further research and development in this area.
Overall, this paper presents a thought-provoking and valuable contribution to the understanding of optimization methods for non-smooth neural networks. Its findings challenge widely held assumptions and call for a more nuanced and rigorous approach to the analysis of these complex systems.
Conclusion
This paper provides a comprehensive exploration of the distinctions between gradient methods applied to non-differentiable functions (NGDMs) and classical gradient descents (GDs) designed for differentiable functions. By exposing the limitations of the existing literature on neural network convergence, the authors highlight the necessity for a more nuanced understanding of the underlying assumptions and behaviors of optimization methods in the context of non-smooth neural networks.
The paper's key insights, such as the paradoxical nature of NGDM solutions for L1-regularized problems and the inapplicability of the Edge of Stability phenomenon, challenge common beliefs and have significant implications for the development of efficient and effective neural network architectures. These findings underscore the importance of critical analysis and a rigorous approach to the study of optimization methods in modern machine learning.
As the field of artificial intelligence continues to advance, this paper serves as a valuable resource for researchers and practitioners, encouraging a more nuanced understanding of the foundational principles governing the optimization of non-smooth, non-differentiable functions. By addressing these fundamental challenges, the research community can pave the way for more robust and reliable machine learning models that can tackle the complex problems of the modern world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Stepsize Gradient Descent for Non-Homogeneous Two-Layer Networks: Margin Improvement and Fast Optimization
Yuhang Cai, Jingfeng Wu, Song Mei, Michael Lindsey, Peter L. Bartlett
0
0
The typical training of neural networks using large stepsize gradient descent (GD) under the logistic loss often involves two distinct phases, where the empirical risk oscillates in the first phase but decreases monotonically in the second phase. We investigate this phenomenon in two-layer networks that satisfy a near-homogeneity condition. We show that the second phase begins once the empirical risk falls below a certain threshold, dependent on the stepsize. Additionally, we show that the normalized margin grows nearly monotonically in the second phase, demonstrating an implicit bias of GD in training non-homogeneous predictors. If the dataset is linearly separable and the derivative of the activation function is bounded away from zero, we show that the average empirical risk decreases, implying that the first phase must stop in finite steps. Finally, we demonstrate that by choosing a suitably large stepsize, GD that undergoes this phase transition is more efficient than GD that monotonically decreases the risk. Our analysis applies to networks of any width, beyond the well-known neural tangent kernel and mean-field regimes.
6/28/2024
🏋️
Approximation and Gradient Descent Training with Neural Networks
G. Welper
0
0
It is well understood that neural networks with carefully hand-picked weights provide powerful function approximation and that they can be successfully trained in over-parametrized regimes. Since over-parametrization ensures zero training error, these two theories are not immediately compatible. Recent work uses the smoothness that is required for approximation results to extend a neural tangent kernel (NTK) optimization argument to an under-parametrized regime and show direct approximation bounds for networks trained by gradient flow. Since gradient flow is only an idealization of a practical method, this paper establishes analogous results for networks trained by gradient descent.
5/21/2024
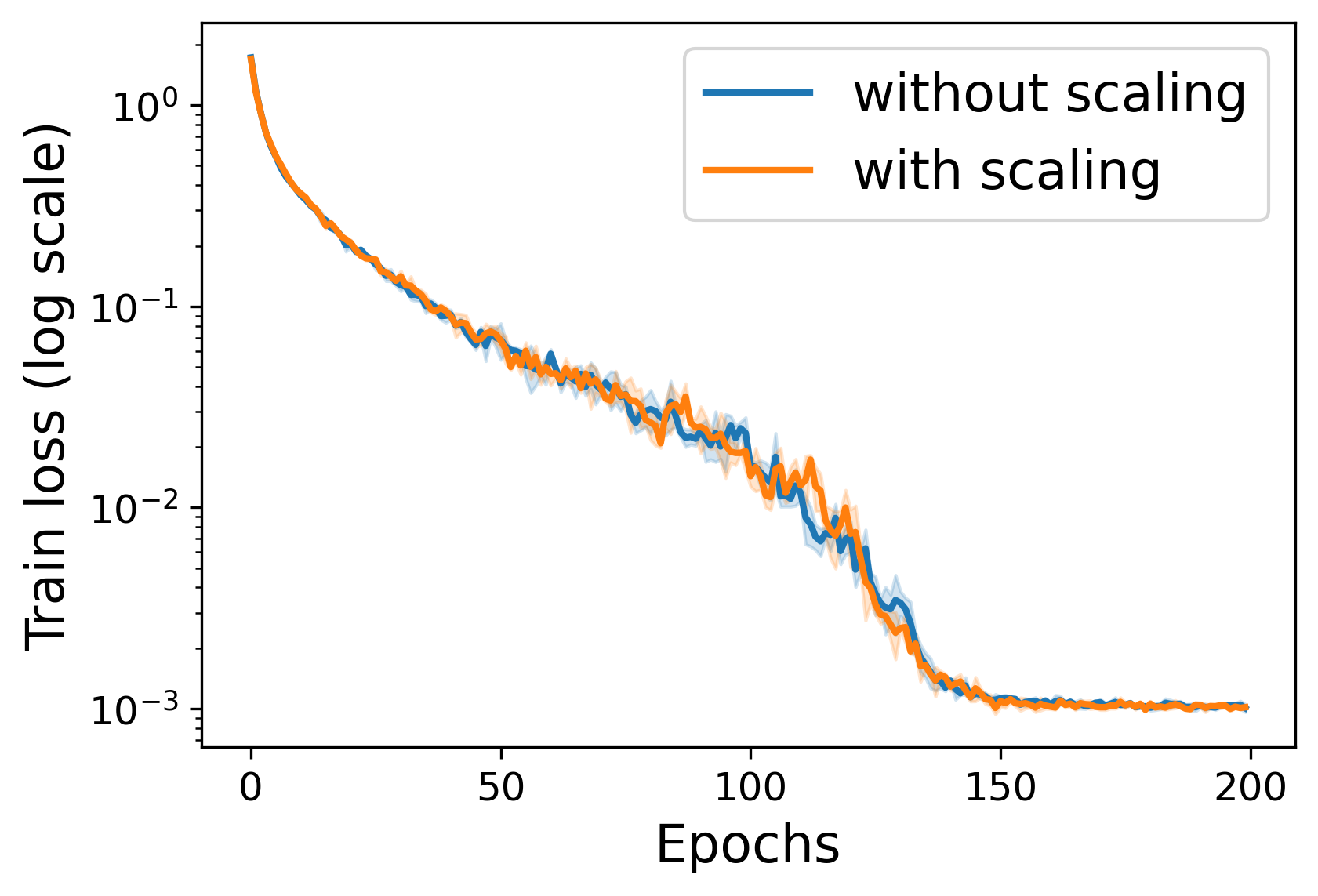
Random Scaling and Momentum for Non-smooth Non-convex Optimization
Qinzi Zhang, Ashok Cutkosky
0
0
Training neural networks requires optimizing a loss function that may be highly irregular, and in particular neither convex nor smooth. Popular training algorithms are based on stochastic gradient descent with momentum (SGDM), for which classical analysis applies only if the loss is either convex or smooth. We show that a very small modification to SGDM closes this gap: simply scale the update at each time point by an exponentially distributed random scalar. The resulting algorithm achieves optimal convergence guarantees. Intriguingly, this result is not derived by a specific analysis of SGDM: instead, it falls naturally out of a more general framework for converting online convex optimization algorithms to non-convex optimization algorithms.
5/17/2024
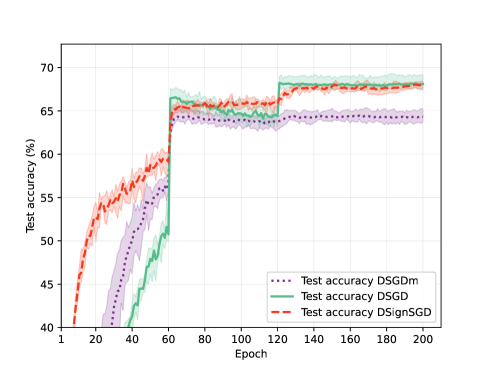
Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
Siyuan Zhang, Nachuan Xiao, Xin Liu
0
0
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework to analyze the global convergence of decentralized stochastic subgradient-based methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework covers a wide range of existing efficient decentralized subgradient-based methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGD-M). In addition, we introduce the sign map to regularize the update directions in DSGD-M, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient-based methods with convergence guarantees in the training of nonsmooth neural networks.
6/28/2024