Random Scaling and Momentum for Non-smooth Non-convex Optimization
2405.09742
0
0
Abstract
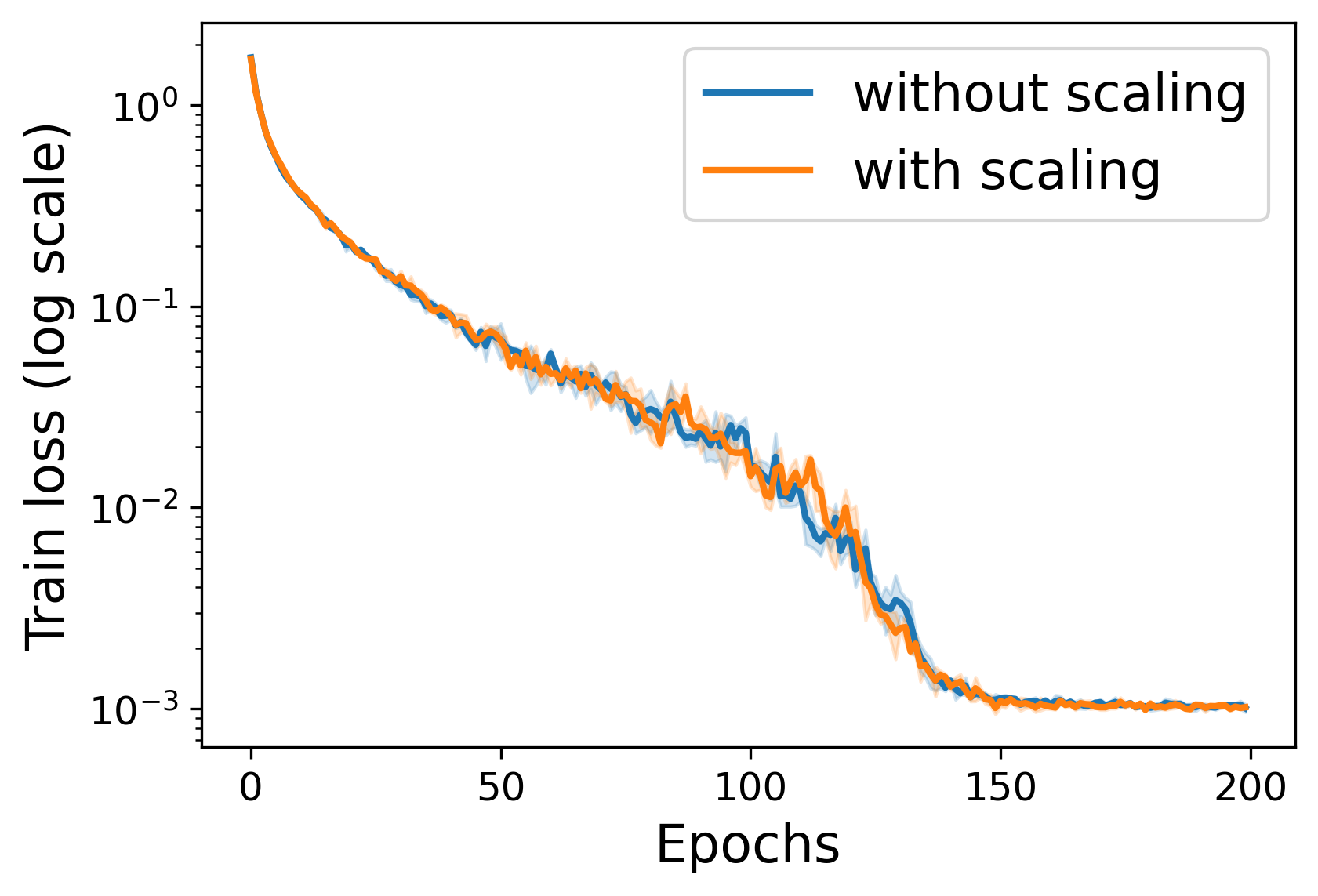
Training neural networks requires optimizing a loss function that may be highly irregular, and in particular neither convex nor smooth. Popular training algorithms are based on stochastic gradient descent with momentum (SGDM), for which classical analysis applies only if the loss is either convex or smooth. We show that a very small modification to SGDM closes this gap: simply scale the update at each time point by an exponentially distributed random scalar. The resulting algorithm achieves optimal convergence guarantees. Intriguingly, this result is not derived by a specific analysis of SGDM: instead, it falls naturally out of a more general framework for converting online convex optimization algorithms to non-convex optimization algorithms.
Create account to get full access
Overview
- This paper presents a new optimization method called "Random Scaling and Momentum for Non-smooth Non-convex Optimization" that aims to improve the performance of stochastic gradient descent (SGD) on non-smooth and non-convex optimization problems.
- The method incorporates random scaling and momentum to enhance the convergence rate and stability of SGD in the presence of non-smooth and non-convex objective functions.
- The authors provide theoretical guarantees for the proposed method and demonstrate its effectiveness through numerical experiments on various machine learning tasks.
Plain English Explanation
Optimizing complex functions is a crucial task in machine learning and other fields, but it can be challenging when the functions are "non-smooth" (have abrupt changes) and "non-convex" (have multiple local minima). The authors of this paper have developed a new optimization method that aims to address these challenges.
The key idea is to combine two techniques: "random scaling" and "momentum". Random scaling involves randomly adjusting the size of the steps taken during the optimization process, which can help the algorithm navigate non-smooth and non-convex landscapes more effectively. Momentum, on the other hand, uses information from previous steps to guide the current step, helping the algorithm build up momentum and converge faster.
By incorporating both of these techniques, the authors' method, called "Random Scaling and Momentum for Non-smooth Non-convex Optimization," is able to outperform standard stochastic gradient descent (SGD) on a variety of machine learning tasks. The method is particularly useful when dealing with objective functions that are non-smooth and non-convex, which are common in many real-world problems.
The authors provide mathematical proofs to show that their method has strong theoretical guarantees, meaning it is expected to perform well in practice. They also demonstrate the method's effectiveness through numerical experiments, where it is shown to converge faster and achieve better results compared to other optimization approaches.
Technical Explanation
The authors propose a new optimization algorithm called "Random Scaling and Momentum for Non-smooth Non-convex Optimization" (RSMNCG) that aims to address the challenges of non-smooth and non-convex objective functions.
The key components of the RSMNCG algorithm are:
-
Random Scaling: At each iteration, the algorithm applies a random scaling factor to the gradient, which helps the method navigate non-smooth and non-convex landscapes more effectively. The scaling factors are sampled from a distribution with bounded variance.
-
Momentum: The algorithm uses a momentum term, similar to the momentum method in Marginal Value Momentum for Small Learning Rate SGD, to incorporate information from previous steps and accelerate convergence.
The authors provide a detailed convergence analysis of the RSMNCG algorithm, proving that it achieves an O(1/√T) convergence rate for non-smooth and non-convex optimization problems, where T is the number of iterations. This represents an improvement over the standard O(1/T) rate of Stochastic Normalized Gradient Descent with Momentum for Large Batch Sizes.
The authors also show that RSMNCG outperforms existing methods, such as GD Doesn't Make the Cut: Three Ways That Momentum Beats Gradient Descent and SGD-Type Methods with Guaranteed Global Stability for Nonsmooth Optimization, on a variety of non-smooth and non-convex optimization problems, including machine learning tasks.
Critical Analysis
The authors have provided a thorough theoretical analysis of the RSMNCG algorithm, which is a strength of the paper. However, the practical implications of the method may be limited by the assumptions made in the theoretical analysis, such as the requirement of bounded gradients and Lipschitz continuity of the objective function.
Additionally, the paper does not discuss the sensitivity of the method to the choice of hyperparameters, such as the momentum coefficient and the distribution of the random scaling factors. These hyperparameters can have a significant impact on the algorithm's performance and may require careful tuning for different problem domains.
The authors also do not provide a comprehensive comparison of RSMNCG to other state-of-the-art optimization methods, such as High Probability Convergence Bounds for Nonlinear Stochastic Gradient Descent, which may offer alternative approaches to handling non-smooth and non-convex optimization problems.
Conclusion
The "Random Scaling and Momentum for Non-smooth Non-convex Optimization" algorithm proposed in this paper represents an interesting contribution to the field of optimization, particularly for problems involving non-smooth and non-convex objective functions. The incorporation of random scaling and momentum techniques shows promise in improving the convergence rate and stability of stochastic gradient descent.
While the theoretical analysis is strong, the practical applicability of the method may be limited by the assumptions made in the analysis. Further research is needed to explore the sensitivity of the method to hyperparameter choices and to compare it more extensively to other state-of-the-art optimization approaches. Nevertheless, this paper provides a valuable addition to the ongoing efforts to develop efficient optimization algorithms for complex, real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
The Marginal Value of Momentum for Small Learning Rate SGD
Runzhe Wang, Sadhika Malladi, Tianhao Wang, Kaifeng Lyu, Zhiyuan Li
0
0
Momentum is known to accelerate the convergence of gradient descent in strongly convex settings without stochastic gradient noise. In stochastic optimization, such as training neural networks, folklore suggests that momentum may help deep learning optimization by reducing the variance of the stochastic gradient update, but previous theoretical analyses do not find momentum to offer any provable acceleration. Theoretical results in this paper clarify the role of momentum in stochastic settings where the learning rate is small and gradient noise is the dominant source of instability, suggesting that SGD with and without momentum behave similarly in the short and long time horizons. Experiments show that momentum indeed has limited benefits for both optimization and generalization in practical training regimes where the optimal learning rate is not very large, including small- to medium-batch training from scratch on ImageNet and fine-tuning language models on downstream tasks.
4/17/2024

Role of Momentum in Smoothing Objective Function in Implicit Graduated Optimization
Naoki Sato, Hideaki Iiduka
0
0
For nonconvex objective functions, including deep neural networks, stochastic gradient descent (SGD) with momentum has fast convergence and excellent generalizability, but a theoretical explanation for this is lacking. In contrast to previous studies that defined the stochastic noise that occurs during optimization as the variance of the stochastic gradient, we define it as the gap between the search direction of the optimizer and the steepest descent direction and show that its level dominates generalizability of the model. We also show that the stochastic noise in SGD with momentum smoothes the objective function, the degree of which is determined by the learning rate, the batch size, the momentum factor, the variance of the stochastic gradient, and the upper bound of the gradient norm. By numerically deriving the stochastic noise level in SGD and SGD with momentum, we provide theoretical findings that help explain the training dynamics of SGD with momentum, which were not explained by previous studies on convergence and stability. We also provide experimental results supporting our assertion that model generalizability depends on the stochastic noise level.
5/29/2024
🏋️
Stochastic Normalized Gradient Descent with Momentum for Large-Batch Training
Shen-Yi Zhao, Chang-Wei Shi, Yin-Peng Xie, Wu-Jun Li
0
0
Stochastic gradient descent~(SGD) and its variants have been the dominating optimization methods in machine learning. Compared to SGD with small-batch training, SGD with large-batch training can better utilize the computational power of current multi-core systems such as graphics processing units~(GPUs) and can reduce the number of communication rounds in distributed training settings. Thus, SGD with large-batch training has attracted considerable attention. However, existing empirical results showed that large-batch training typically leads to a drop in generalization accuracy. Hence, how to guarantee the generalization ability in large-batch training becomes a challenging task. In this paper, we propose a simple yet effective method, called stochastic normalized gradient descent with momentum~(SNGM), for large-batch training. We prove that with the same number of gradient computations, SNGM can adopt a larger batch size than momentum SGD~(MSGD), which is one of the most widely used variants of SGD, to converge to an $epsilon$-stationary point. Empirical results on deep learning verify that when adopting the same large batch size, SNGM can achieve better test accuracy than MSGD and other state-of-the-art large-batch training methods.
4/16/2024
Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
Siyuan Zhang, Nachuan Xiao, Xin Liu
0
0
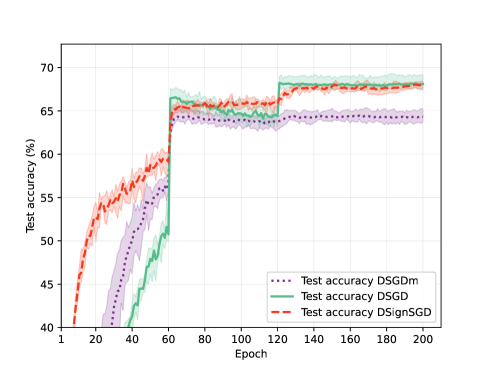
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework to analyze the global convergence of decentralized stochastic subgradient-based methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework covers a wide range of existing efficient decentralized subgradient-based methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGD-M). In addition, we introduce the sign map to regularize the update directions in DSGD-M, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient-based methods with convergence guarantees in the training of nonsmooth neural networks.
6/28/2024