GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
2404.02152
0
0
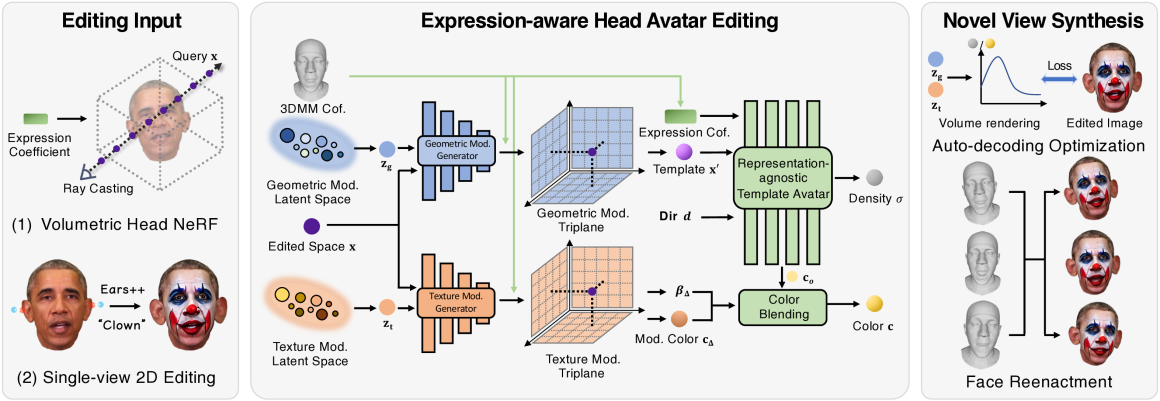
Abstract
Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars. However, due to the diversity of frameworks, there is no practical method to support high-level applications like 3D head avatar editing across different representations. In this paper, we propose a generic avatar editing approach that can be universally applied to various 3DMM driving volumetric head avatars. To achieve this goal, we design a novel expression-aware modification generative model, which enables lift 2D editing from a single image to a consistent 3D modification field. To ensure the effectiveness of the generative modification process, we develop several techniques, including an expression-dependent modification distillation scheme to draw knowledge from the large-scale head avatar model and 2D facial texture editing tools, implicit latent space guidance to enhance model convergence, and a segmentation-based loss reweight strategy for fine-grained texture inversion. Extensive experiments demonstrate that our method delivers high-quality and consistent results across multiple expression and viewpoints. Project page: https://zju3dv.github.io/geneavatar/
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents GeneAvatar, a method for editing volumetric head avatars from a single input image while preserving the subject's identity and enabling realistic expression changes.
- GeneAvatar uses a neural network to extract an identity-preserving 3D head representation from a single image, and then applies an expression-based deformation to generate the final edited avatar.
- The approach allows for fine-grained control over the avatar's expressions, enabling applications in virtual reality, games, and video conferencing.
Plain English Explanation
GeneAvatar is a system that can take a single photo of a person's head and use it to create a 3D animated avatar that can be customized with different facial expressions. The key idea is that the system first extracts a 3D representation of the person's head that captures their unique identity, and then it can modify the expression of that 3D model to create new poses and emotions.
Imagine you want to create an avatar that looks like you for use in a virtual reality game or video chat. Traditionally, this would require specialized 3D modeling skills and equipment to capture a full 3D scan of your head. GeneAvatar makes this process much simpler - you just provide a single photo, and the system can automatically generate a 3D avatar that looks like you.
Moreover, GeneAvatar allows you to dynamically change the facial expression of the avatar, so you can make it smile, frown, or make other emotional expressions. This enables more natural and expressive interactions in virtual environments. The key innovation is that GeneAvatar can do this while still preserving the core identity and likeness of the original person in the photo.
Technical Explanation
The core of the GeneAvatar approach is a neural network that can extract a 3D head representation from a single 2D input image. This 3D representation encodes the subject's unique identity, facial structure, and other defining characteristics. The network is trained on a large dataset of 3D head scans and corresponding 2D images.
To edit the avatar's expression, GeneAvatar applies a deformation field to the 3D head model. This deformation is predicted by another neural network that takes the original 3D head representation and a target expression as input. By learning the mapping between expression changes and the corresponding 3D deformations, the system can generate new posed versions of the avatar.
Key technical innovations include the use of a disentangled 3D representation to separately capture identity and expression, as well as novel training strategies to ensure the generated avatars maintain photorealism and identity consistency. Extensive experiments demonstrate GeneAvatar's ability to create high-quality, editable avatars from single input images across a wide range of subjects and expressions.
Critical Analysis
The paper provides a compelling technical approach for avatar editing from single images, with strong results showcased across diverse test cases. However, some potential limitations and areas for further research are worth noting:
The system currently operates on isolated head models, without accounting for the rest of the face or body. Extending the approach to handle full 3D face and body representations could further enhance realism and usability. Additionally, the training dataset and evaluation primarily focused on Caucasian subjects, so the generalization to more diverse populations requires further investigation.
While the expression editing capabilities are impressive, the system is currently limited to a predefined set of expressions. Enabling more open-ended, freeform expression control could broaden the creative possibilities for avatar customization. Robustness to challenging lighting conditions, occlusions, and noisy input images are other areas that could benefit from additional research.
Overall, GeneAvatar represents an important step forward in democratizing 3D avatar creation and editing. With further advancements, such systems could have significant implications for virtual communication, gaming, and other emerging applications at the intersection of computer graphics and computer vision.
Conclusion
The GeneAvatar system presented in this paper introduces a novel approach for generating and editing 3D head avatars from a single input image. By extracting a disentangled 3D representation that captures both a subject's identity and their ability to make different facial expressions, GeneAvatar enables a high degree of customization and control over the resulting avatars.
This work has the potential to significantly simplify the creation of photorealistic 3D avatars, making them more accessible for a wide range of applications in virtual reality, videoconferencing, games, and beyond. While the current system has some limitations, the core technical innovations and promising results suggest that further advancements in this direction could lead to transformative improvements in how we represent ourselves in digital environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
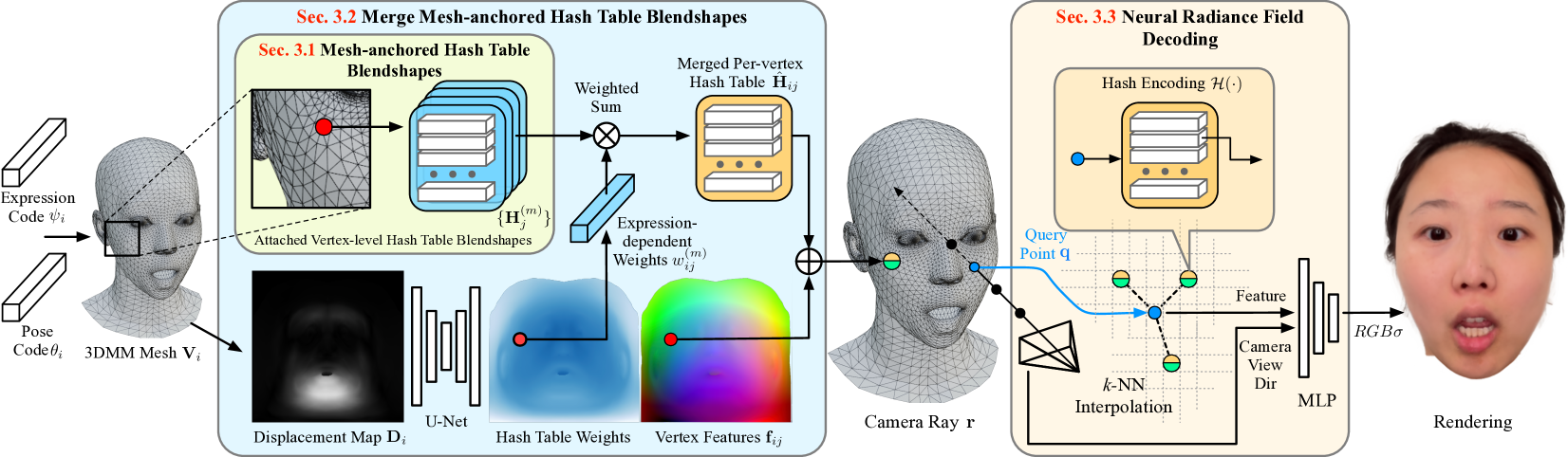
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Ziqian Bai, Feitong Tan, Sean Fanello, Rohit Pandey, Mingsong Dou, Shichen Liu, Ping Tan, Yinda Zhang
0
0
3D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
4/3/2024
🤷
InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
Antonio Canela, Pol Caselles, Ibrar Malik, Eduard Ramon, Jaime Garc'ia, Jordi S'anchez-Riera, Gil Triginer, Francesc Moreno-Noguer
0
0
Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.
4/8/2024
🤿
3D Gaussian Blendshapes for Head Avatar Animation
Shengjie Ma, Yanlin Weng, Tianjia Shao, Kun Zhou
0
0
We introduce 3D Gaussian blendshapes for modeling photorealistic head avatars. Taking a monocular video as input, we learn a base head model of neutral expression, along with a group of expression blendshapes, each of which corresponds to a basis expression in classical parametric face models. Both the neutral model and expression blendshapes are represented as 3D Gaussians, which contain a few properties to depict the avatar appearance. The avatar model of an arbitrary expression can be effectively generated by combining the neutral model and expression blendshapes through linear blending of Gaussians with the expression coefficients. High-fidelity head avatar animations can be synthesized in real time using Gaussian splatting. Compared to state-of-the-art methods, our Gaussian blendshape representation better captures high-frequency details exhibited in input video, and achieves superior rendering performance.
5/3/2024

MeGA: Hybrid Mesh-Gaussian Head Avatar for High-Fidelity Rendering and Head Editing
Cong Wang, Di Kang, He-Yi Sun, Shen-Han Qian, Zi-Xuan Wang, Linchao Bao, Song-Hai Zhang
0
0
Creating high-fidelity head avatars from multi-view videos is a core issue for many AR/VR applications. However, existing methods usually struggle to obtain high-quality renderings for all different head components simultaneously since they use one single representation to model components with drastically different characteristics (e.g., skin vs. hair). In this paper, we propose a Hybrid Mesh-Gaussian Head Avatar (MeGA) that models different head components with more suitable representations. Specifically, we select an enhanced FLAME mesh as our facial representation and predict a UV displacement map to provide per-vertex offsets for improved personalized geometric details. To achieve photorealistic renderings, we obtain facial colors using deferred neural rendering and disentangle neural textures into three meaningful parts. For hair modeling, we first build a static canonical hair using 3D Gaussian Splatting. A rigid transformation and an MLP-based deformation field are further applied to handle complex dynamic expressions. Combined with our occlusion-aware blending, MeGA generates higher-fidelity renderings for the whole head and naturally supports more downstream tasks. Experiments on the NeRSemble dataset demonstrate the effectiveness of our designs, outperforming previous state-of-the-art methods and supporting various editing functionalities, including hairstyle alteration and texture editing.
5/1/2024