InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
2308.04868
0
0
🤷
Abstract
Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces a new method called InstantAvatar that can quickly reconstruct full-head avatars from a few images
- Proposes a novel combination of a voxel-grid neural field representation and a surface renderer to speed up the reconstruction process
- Overcomes the instability of this naive combination by using a statistical model that learns a prior distribution over 3D head signed distance functions
Plain English Explanation
InstantAvatar is a new technique that can quickly create 3D models of people's heads from just a few photos. This is an important advance over previous methods, which could take minutes or even hours to reconstruct a single head.
The key innovation in InstantAvatar is its use of two different technologies working together. First, it uses a voxel-grid neural network to represent the 3D shape of the head. This allows the system to quickly generate an initial 3D model. Then, it uses a surface renderer to refine the details of the model and make it look more realistic.
However, simply combining these two technologies doesn't work very well - the optimization process becomes unstable and doesn't produce good results. To fix this, the researchers developed a statistical model that learns the common properties of 3D head shapes. This prior model helps guide the optimization process and ensures that the final 3D model is both accurate and valid.
By combining these various techniques, InstantAvatar can reconstruct full-head avatars in just a few seconds, while maintaining comparable accuracy to state-of-the-art methods that take much longer. This could enable new applications like instant virtual try-on of glasses, hats, or other accessories.
Technical Explanation
Recent work on full-head reconstruction has achieved impressive accuracy by optimizing a neural field representation of a scene through differentiable rendering. However, these techniques are computationally expensive, often taking minutes or hours to produce a result.
In this paper, the authors introduce InstantAvatar, a new method that can recover full-head avatars from just a few images (sometimes even a single image) in just a few seconds on standard hardware. To speed up the reconstruction process, InstantAvatar combines a voxel-grid neural field representation with a surface renderer.
Naively combining these two components, however, leads to unstable optimization that fails to converge to valid solutions. To address this, the authors present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid architecture. This prior model, along with other design choices, enables InstantAvatar to achieve 3D head reconstructions with accuracy comparable to state-of-the-art methods, but with a 100x speed-up.
Critical Analysis
The authors acknowledge that while InstantAvatar achieves a significant speed-up, there are some limitations to the approach. For example, the statistical head model may not generalize well to highly diverse head shapes, and the surface rendering component could introduce artifacts in the final output.
Additionally, the paper does not provide a thorough analysis of failure cases or edge cases where the method might struggle. It would be helpful to understand the types of inputs that are challenging for InstantAvatar and where further research is needed.
That said, the core idea of combining a neural field representation with a surface renderer, guided by a learned statistical prior, is a clever and promising approach. If the authors can address the remaining limitations, InstantAvatar could enable a wide range of new applications, from virtual try-on to real-time avatar creation.
Conclusion
The InstantAvatar method represents an important step forward in the field of 3D head reconstruction by dramatically reducing the computational cost while maintaining high accuracy. By cleverly combining a voxel-grid neural field, a surface renderer, and a learned statistical prior, the authors have created a system that can produce full-head avatars in just seconds.
This advance could unlock new applications in areas like virtual try-on, remote collaboration, and 3D-consistent diffusion from single images. As the authors continue to refine and expand the capabilities of InstantAvatar, it has the potential to significantly impact the way we create and interact with 3D digital avatars.
Related Papers
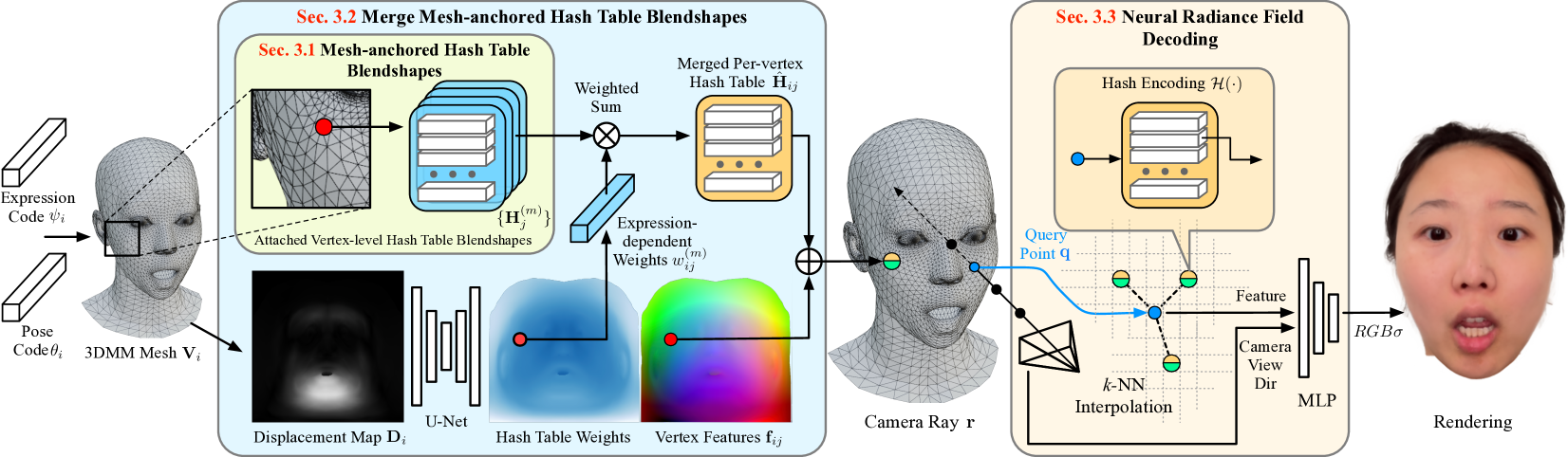
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Ziqian Bai, Feitong Tan, Sean Fanello, Rohit Pandey, Mingsong Dou, Shichen Liu, Ping Tan, Yinda Zhang
0
0
3D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
4/3/2024
📊
FlashAvatar: High-fidelity Head Avatar with Efficient Gaussian Embedding
Jun Xiang, Xuan Gao, Yudong Guo, Juyong Zhang
0
0
We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed. Project page: https://ustc3dv.github.io/FlashAvatar/
4/1/2024
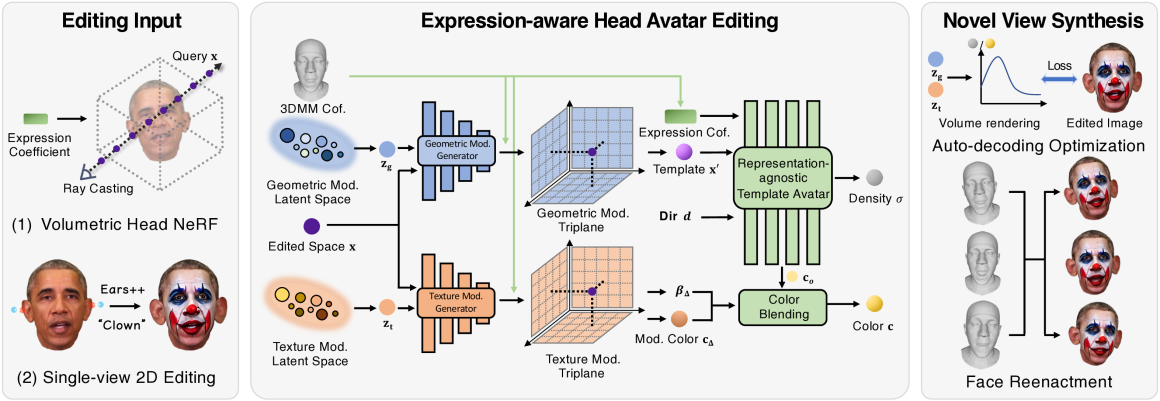
GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
Chong Bao, Yinda Zhang, Yuan Li, Xiyu Zhang, Bangbang Yang, Hujun Bao, Marc Pollefeys, Guofeng Zhang, Zhaopeng Cui
0
0
Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars. However, due to the diversity of frameworks, there is no practical method to support high-level applications like 3D head avatar editing across different representations. In this paper, we propose a generic avatar editing approach that can be universally applied to various 3DMM driving volumetric head avatars. To achieve this goal, we design a novel expression-aware modification generative model, which enables lift 2D editing from a single image to a consistent 3D modification field. To ensure the effectiveness of the generative modification process, we develop several techniques, including an expression-dependent modification distillation scheme to draw knowledge from the large-scale head avatar model and 2D facial texture editing tools, implicit latent space guidance to enhance model convergence, and a segmentation-based loss reweight strategy for fine-grained texture inversion. Extensive experiments demonstrate that our method delivers high-quality and consistent results across multiple expression and viewpoints. Project page: https://zju3dv.github.io/geneavatar/
4/3/2024

Learning Topology Uniformed Face Mesh by Volume Rendering for Multi-view Reconstruction
Yating Wang, Ran Yi, Ke Fan, Jinkun Hao, Jiangbo Lu, Lizhuang Ma
0
0
Face meshes in consistent topology serve as the foundation for many face-related applications, such as 3DMM constrained face reconstruction and expression retargeting. Traditional methods commonly acquire topology uniformed face meshes by two separate steps: multi-view stereo (MVS) to reconstruct shapes followed by non-rigid registration to align topology, but struggles with handling noise and non-lambertian surfaces. Recently neural volume rendering techniques have been rapidly evolved and shown great advantages in 3D reconstruction or novel view synthesis. Our goal is to leverage the superiority of neural volume rendering into multi-view reconstruction of face mesh with consistent topology. We propose a mesh volume rendering method that enables directly optimizing mesh geometry while preserving topology, and learning implicit features to model complex facial appearance from multi-view images. The key innovation lies in spreading sparse mesh features into the surrounding space to simulate radiance field required for volume rendering, which facilitates backpropagation of gradients from images to mesh geometry and implicit appearance features. Our proposed feature spreading module exhibits deformation invariance, enabling photorealistic rendering seamlessly after mesh editing. We conduct experiments on multi-view face image dataset to evaluate the reconstruction and implement an application for photorealistic rendering of animated face mesh.
4/9/2024