General bounds on the quality of Bayesian coresets
2405.11780
0
0

Abstract
Bayesian coresets speed up posterior inference in the large-scale data regime by approximating the full-data log-likelihood function with a surrogate log-likelihood based on a small, weighted subset of the data. But while Bayesian coresets and methods for construction are applicable in a wide range of models, existing theoretical analysis of the posterior inferential error incurred by coreset approximations only apply in restrictive settings -- i.e., exponential family models, or models with strong log-concavity and smoothness assumptions. This work presents general upper and lower bounds on the Kullback-Leibler (KL) divergence of coreset approximations that reflect the full range of applicability of Bayesian coresets. The lower bounds require only mild model assumptions typical of Bayesian asymptotic analyses, while the upper bounds require the log-likelihood functions to satisfy a generalized subexponentiality criterion that is weaker than conditions used in earlier work. The lower bounds are applied to obtain fundamental limitations on the quality of coreset approximations, and to provide a theoretical explanation for the previously-observed poor empirical performance of importance sampling-based construction methods. The upper bounds are used to analyze the performance of recent subsample-optimize methods. The flexibility of the theory is demonstrated in validation experiments involving multimodal, unidentifiable, heavy-tailed Bayesian posterior distributions.
Create account to get full access
Overview
- This paper presents general bounds on the quality of Bayesian coresets, which are small weighted subsets of data that can be used to approximate Bayesian posteriors.
- The authors derive lower bounds on the approximation error of Bayesian coresets, showing that the error cannot be made arbitrarily small for certain problem settings.
- The results have implications for Bayesian pseudo-coresets via contrastive divergence, diffusion-based generative models and their error bounds, and other areas where Bayesian coresets are used.
Plain English Explanation
Bayesian coresets are a way to summarize a large dataset into a smaller, weighted subset. This can be useful when working with big datasets, as it allows you to do Bayesian analysis on a much smaller amount of data.
The authors of this paper show that there are fundamental limits on how well these Bayesian coresets can approximate the true Bayesian posterior distribution. No matter how the coresets are constructed, there will always be some error compared to the full dataset. This means that the coresets can never perfectly capture all the information in the original data.
This has important implications for other areas of machine learning, like Bayesian pseudo-coresets and diffusion-based generative models. Researchers working in these fields need to be aware of the inherent limitations of Bayesian coresets and plan accordingly.
Technical Explanation
The paper derives lower bounds on the approximation error of Bayesian coresets. Specifically, the authors show that the Kullback-Leibler (KL) divergence between the true Bayesian posterior and the posterior based on a Bayesian coreset cannot be made arbitrarily small.
This is proved by constructing a family of problem instances where the KL divergence is bounded away from zero, regardless of the size of the Bayesian coreset. The key insight is that for certain data distributions and model classes, the information lost by compressing the dataset into a coreset is fundamental and cannot be overcome.
The results have implications for other areas of Bayesian inference, such as settling time vs. accuracy tradeoffs in clustering big data and PAC-Bayes bounds. Researchers in these fields often rely on Bayesian coresets, and the lower bounds established in this paper suggest that there are inherent limitations to the quality of approximation that can be achieved.
Critical Analysis
The paper provides a rigorous theoretical analysis of Bayesian coresets, but it is limited to specific problem settings and model classes. The authors acknowledge that their lower bounds may not apply in all scenarios, and that the construction of the problematic problem instances may not reflect real-world data and models.
Additionally, the paper does not address potential ways to mitigate the approximation error, such as using more sophisticated coreset construction algorithms or combining coresets with other techniques like particle gradient descent extensions. Exploring these avenues could lead to improved practical performance of Bayesian coresets, even if the theoretical limits cannot be overcome.
Overall, the paper provides valuable insights into the fundamental limitations of Bayesian coresets, but further research is needed to fully understand their capabilities and limitations in diverse real-world applications.
Conclusion
This paper establishes general lower bounds on the quality of Bayesian coresets, showing that the approximation error cannot be made arbitrarily small for certain problem settings. These results have important implications for the use of Bayesian coresets in machine learning and Bayesian inference, as researchers need to be aware of the inherent limitations of this technique.
While the theoretical analysis is rigorous, the applicability of the results to real-world scenarios remains an open question. Exploring new coreset construction algorithms, combining coresets with other techniques, and testing on diverse datasets could lead to improved practical performance and a better understanding of the tradeoffs involved in using Bayesian coresets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Bayesian Pseudo-Coresets via Contrastive Divergence
Piyush Tiwary, Kumar Shubham, Vivek V. Kashyap, Prathosh A. P
0
0
Bayesian methods provide an elegant framework for estimating parameter posteriors and quantification of uncertainty associated with probabilistic models. However, they often suffer from slow inference times. To address this challenge, Bayesian Pseudo-Coresets (BPC) have emerged as a promising solution. BPC methods aim to create a small synthetic dataset, known as pseudo-coresets, that approximates the posterior inference achieved with the original dataset. This approximation is achieved by optimizing a divergence measure between the true posterior and the pseudo-coreset posterior. Various divergence measures have been proposed for constructing pseudo-coresets, with forward Kullback-Leibler (KL) divergence being the most successful. However, using forward KL divergence necessitates sampling from the pseudo-coreset posterior, often accomplished through approximate Gaussian variational distributions. Alternatively, one could employ Markov Chain Monte Carlo (MCMC) methods for sampling, but this becomes challenging in high-dimensional parameter spaces due to slow mixing. In this study, we introduce a novel approach for constructing pseudo-coresets by utilizing contrastive divergence. Importantly, optimizing contrastive divergence eliminates the need for approximations in the pseudo-coreset construction process. Furthermore, it enables the use of finite-step MCMC methods, alleviating the requirement for extensive mixing to reach a stationary distribution. To validate our method's effectiveness, we conduct extensive experiments on multiple datasets, demonstrating its superiority over existing BPC techniques.
5/10/2024
🗣️
On diffusion-based generative models and their error bounds: The log-concave case with full convergence estimates
Stefano Bruno, Ying Zhang, Dong-Young Lim, Omer Deniz Akyildiz, Sotirios Sabanis
0
0
We provide full theoretical guarantees for the convergence behaviour of diffusion-based generative models under the assumption of strongly log-concave data distributions while our approximating class of functions used for score estimation is made of Lipschitz continuous functions. We demonstrate via a motivating example, sampling from a Gaussian distribution with unknown mean, the powerfulness of our approach. In this case, explicit estimates are provided for the associated optimization problem, i.e. score approximation, while these are combined with the corresponding sampling estimates. As a result, we obtain the best known upper bound estimates in terms of key quantities of interest, such as the dimension and rates of convergence, for the Wasserstein-2 distance between the data distribution (Gaussian with unknown mean) and our sampling algorithm. Beyond the motivating example and in order to allow for the use of a diverse range of stochastic optimizers, we present our results using an $L^2$-accurate score estimation assumption, which crucially is formed under an expectation with respect to the stochastic optimizer and our novel auxiliary process that uses only known information. This approach yields the best known convergence rate for our sampling algorithm.
4/23/2024
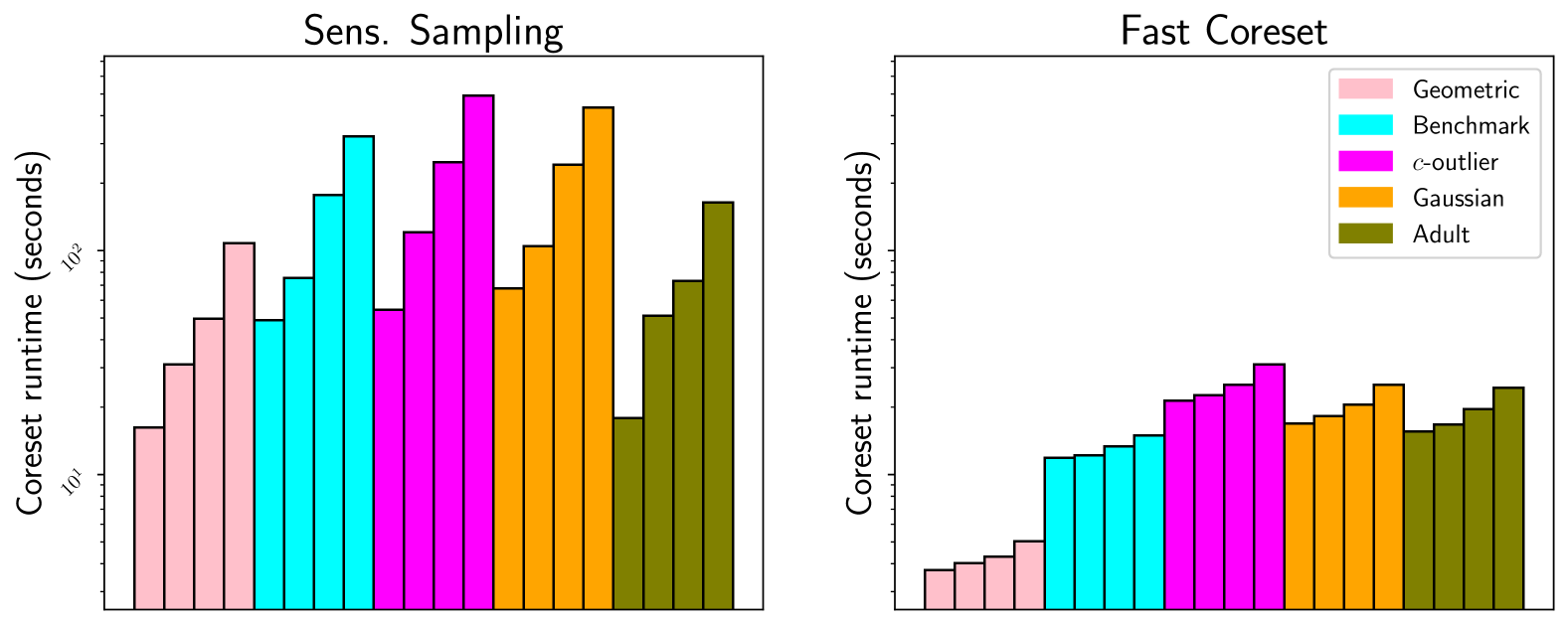
Settling Time vs. Accuracy Tradeoffs for Clustering Big Data
Andrew Draganov, David Saulpic, Chris Schwiegelshohn
0
0
We study the theoretical and practical runtime limits of k-means and k-median clustering on large datasets. Since effectively all clustering methods are slower than the time it takes to read the dataset, the fastest approach is to quickly compress the data and perform the clustering on the compressed representation. Unfortunately, there is no universal best choice for compressing the number of points - while random sampling runs in sublinear time and coresets provide theoretical guarantees, the former does not enforce accuracy while the latter is too slow as the numbers of points and clusters grow. Indeed, it has been conjectured that any sensitivity-based coreset construction requires super-linear time in the dataset size. We examine this relationship by first showing that there does exist an algorithm that obtains coresets via sensitivity sampling in effectively linear time - within log-factors of the time it takes to read the data. Any approach that significantly improves on this must then resort to practical heuristics, leading us to consider the spectrum of sampling strategies across both real and artificial datasets in the static and streaming settings. Through this, we show the conditions in which coresets are necessary for preserving cluster validity as well as the settings in which faster, cruder sampling strategies are sufficient. As a result, we provide a comprehensive theoretical and practical blueprint for effective clustering regardless of data size. Our code is publicly available and has scripts to recreate the experiments.
4/3/2024
📶
Generalized Laplace Approximation
Yinsong Chen, Samson S. Yu, Zhong Li, Chee Peng Lim
0
0
In recent years, the inconsistency in Bayesian deep learning has garnered increasing attention. Tempered or generalized posterior distributions often offer a direct and effective solution to this issue. However, understanding the underlying causes and evaluating the effectiveness of generalized posteriors remain active areas of research. In this study, we introduce a unified theoretical framework to attribute Bayesian inconsistency to model misspecification and inadequate priors. We interpret the generalization of the posterior with a temperature factor as a correction for misspecified models through adjustments to the joint probability model, and the recalibration of priors by redistributing probability mass on models within the hypothesis space using data samples. Additionally, we highlight a distinctive feature of Laplace approximation, which ensures that the generalized normalizing constant can be treated as invariant, unlike the typical scenario in general Bayesian learning where this constant varies with model parameters post-generalization. Building on this insight, we propose the generalized Laplace approximation, which involves a simple adjustment to the computation of the Hessian matrix of the regularized loss function. This method offers a flexible and scalable framework for obtaining high-quality posterior distributions. We assess the performance and properties of the generalized Laplace approximation on state-of-the-art neural networks and real-world datasets.
5/27/2024