Generalized Laplace Approximation

0
📶
Sign in to get full access
Overview
- Inconsistencies in Bayesian deep learning have become a growing concern
- Generalized or tempered posterior distributions can help address this issue
- Understanding the underlying causes and effectiveness of generalized posteriors is an active area of research
- This study introduces a unified theoretical framework to attribute Bayesian inconsistency to model misspecification and inadequate priors
- The paper proposes the generalized Laplace approximation as a flexible and scalable method for obtaining high-quality posterior distributions
Plain English Explanation
Bayesian deep learning, a technique that combines Bayesian principles with deep neural networks, has been struggling with a problem called "inconsistency." This means that the model's predictions can sometimes be unstable or unreliable, even when the training data doesn't change.
Researchers have found that using tempered or generalized posterior distributions can help fix this issue. However, understanding why this works and how effective it is has been an ongoing area of study.
In this paper, the authors introduce a new way of thinking about the problem. They argue that the inconsistency in Bayesian deep learning is caused by two main issues: the model being too simplistic (model misspecification) and the assumptions made about the data (inadequate priors).
The authors explain that generalized posterior distributions act as a "correction" for these problems. By adjusting the model's joint probability and recalibrating the priors based on the data, the generalized approach can produce more reliable predictions.
The paper also highlights a specific feature of a technique called "Laplace approximation," which allows the generalized normalizing constant (a mathematical value used in the calculations) to be treated as constant, unlike in typical Bayesian learning.
Building on this insight, the authors propose a new method called the "generalized Laplace approximation." This approach involves a simple adjustment to how the Hessian matrix (a mathematical construct) is computed, resulting in a flexible and scalable way to obtain high-quality posterior distributions.
The researchers test this new method on state-of-the-art neural networks and real-world datasets, and find that it performs well.
Technical Explanation
The paper introduces a unified theoretical framework to attribute the problem of Bayesian inconsistency to two key factors: model misspecification and inadequate priors.
The authors interpret the generalization of the posterior distribution with a temperature factor as a way to "correct" for misspecified models. This is done by adjusting the joint probability model and recalibrating the priors based on the data samples, as seen in Bayesian inference for consistent predictions in overparameterized nonlinear regression.
A distinctive feature of Laplace approximation is highlighted - the generalized normalizing constant can be treated as invariant, unlike the typical scenario in general Bayesian learning where this constant varies with model parameters post-generalization. This insight is leveraged to propose the generalized Laplace approximation, which involves a simple adjustment to the computation of the Hessian matrix of the regularized loss function.
The authors evaluate the performance and properties of the generalized Laplace approximation on state-of-the-art neural networks and real-world datasets. This builds on previous work on scalable Bayesian inference in the era of deep learning, improved sampling via learned diffusions, and Riemannian Laplace approximation with the Fisher metric.
Critical Analysis
The paper provides a comprehensive theoretical framework for understanding the sources of Bayesian inconsistency in deep learning and proposes a practical solution in the form of the generalized Laplace approximation. However, some caveats and areas for further research are worth considering.
The authors acknowledge that understanding the underlying causes of Bayesian inconsistency and the effectiveness of generalized posteriors remain active areas of research. While the proposed framework offers insights, there may be additional factors contributing to the problem that are not fully captured.
Additionally, the performance evaluation of the generalized Laplace approximation, while promising, is limited to specific neural network architectures and datasets. Further testing on a wider range of models and real-world applications would help validate the method's broader applicability and robustness.
The paper also does not directly address the potential computational overhead or scalability challenges that may arise when applying the generalized Laplace approximation to large-scale deep learning models. Exploring ways to improve the efficiency of the method would be an important area for future research, as discussed in parameter uncertainties in imperfect surrogate models with low noise.
Overall, the theoretical insights and the proposed generalized Laplace approximation method represent a significant contribution to the field of Bayesian deep learning. However, continued research and validation will be necessary to fully understand and address the problem of Bayesian inconsistency.
Conclusion
This study introduces a unified theoretical framework to attribute the problem of Bayesian inconsistency in deep learning to model misspecification and inadequate priors. The authors interpret the generalization of the posterior distribution as a way to correct these issues and propose the generalized Laplace approximation as a flexible and scalable method for obtaining high-quality posterior distributions.
The insights and the proposed solution presented in this paper have the potential to advance the field of Bayesian deep learning, leading to more reliable and consistent predictions. However, further research is needed to fully understand the underlying causes of Bayesian inconsistency and to validate the effectiveness of the generalized Laplace approximation across a wider range of models and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Generalized Laplace Approximation
Yinsong Chen, Samson S. Yu, Zhong Li, Chee Peng Lim
In recent years, the inconsistency in Bayesian deep learning has garnered increasing attention. Tempered or generalized posterior distributions often offer a direct and effective solution to this issue. However, understanding the underlying causes and evaluating the effectiveness of generalized posteriors remain active areas of research. In this study, we introduce a unified theoretical framework to attribute Bayesian inconsistency to model misspecification and inadequate priors. We interpret the generalization of the posterior with a temperature factor as a correction for misspecified models through adjustments to the joint probability model, and the recalibration of priors by redistributing probability mass on models within the hypothesis space using data samples. Additionally, we highlight a distinctive feature of Laplace approximation, which ensures that the generalized normalizing constant can be treated as invariant, unlike the typical scenario in general Bayesian learning where this constant varies with model parameters post-generalization. Building on this insight, we propose the generalized Laplace approximation, which involves a simple adjustment to the computation of the Hessian matrix of the regularized loss function. This method offers a flexible and scalable framework for obtaining high-quality posterior distributions. We assess the performance and properties of the generalized Laplace approximation on state-of-the-art neural networks and real-world datasets.
Read more5/27/2024
🤿
0
Efficient Bayesian Updates for Deep Learning via Laplace Approximations
Denis Huseljic, Marek Herde, Lukas Rauch, Paul Hahn, Zhixin Huang, Daniel Kottke, Stephan Vogt, Bernhard Sick
Since training deep neural networks takes significant computational resources, extending the training dataset with new data is difficult, as it typically requires complete retraining. Moreover, specific applications do not allow costly retraining due to time or computational constraints. We address this issue by proposing a novel Bayesian update method for deep neural networks by using a last-layer Laplace approximation. Concretely, we leverage second-order optimization techniques on the Gaussian posterior distribution of a Laplace approximation, computing the inverse Hessian matrix in closed form. This way, our method allows for fast and effective updates upon the arrival of new data in a stationary setting. A large-scale evaluation study across different data modalities confirms that our updates are a fast and competitive alternative to costly retraining. Furthermore, we demonstrate its applicability in a deep active learning scenario by using our update to improve existing selection strategies.
Read more7/15/2024
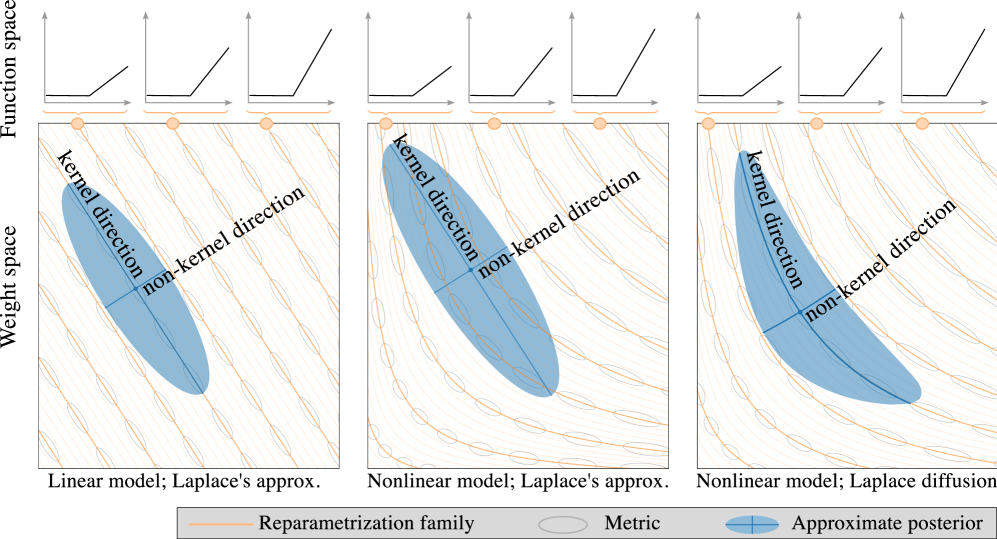
0
Reparameterization invariance in approximate Bayesian inference
Hrittik Roy, Marco Miani, Carl Henrik Ek, Philipp Hennig, Marvin Pfortner, Lukas Tatzel, S{o}ren Hauberg
Current approximate posteriors in Bayesian neural networks (BNNs) exhibit a crucial limitation: they fail to maintain invariance under reparameterization, i.e. BNNs assign different posterior densities to different parametrizations of identical functions. This creates a fundamental flaw in the application of Bayesian principles as it breaks the correspondence between uncertainty over the parameters with uncertainty over the parametrized function. In this paper, we investigate this issue in the context of the increasingly popular linearized Laplace approximation. Specifically, it has been observed that linearized predictives alleviate the common underfitting problems of the Laplace approximation. We develop a new geometric view of reparametrizations from which we explain the success of linearization. Moreover, we demonstrate that these reparameterization invariance properties can be extended to the original neural network predictive using a Riemannian diffusion process giving a straightforward algorithm for approximate posterior sampling, which empirically improves posterior fit.
Read more6/6/2024

0
FSP-Laplace: Function-Space Priors for the Laplace Approximation in Bayesian Deep Learning
Tristan Cinquin, Marvin Pfortner, Vincent Fortuin, Philipp Hennig, Robert Bamler
Laplace approximations are popular techniques for endowing deep networks with epistemic uncertainty estimates as they can be applied without altering the predictions of the neural network, and they scale to large models and datasets. While the choice of prior strongly affects the resulting posterior distribution, computational tractability and lack of interpretability of weight space typically limit the Laplace approximation to isotropic Gaussian priors, which are known to cause pathological behavior as depth increases. As a remedy, we directly place a prior on function space. More precisely, since Lebesgue densities do not exist on infinite-dimensional function spaces, we have to recast training as finding the so-called weak mode of the posterior measure under a Gaussian process (GP) prior restricted to the space of functions representable by the neural network. Through the GP prior, one can express structured and interpretable inductive biases, such as regularity or periodicity, directly in function space, while still exploiting the implicit inductive biases that allow deep networks to generalize. After model linearization, the training objective induces a negative log-posterior density to which we apply a Laplace approximation, leveraging highly scalable methods from matrix-free linear algebra. Our method provides improved results where prior knowledge is abundant, e.g., in many scientific inference tasks. At the same time, it stays competitive for black-box regression and classification tasks where neural networks typically excel.
Read more7/19/2024