Generalisation First, Memorisation Second? Memorisation Localisation for Natural Language Classification Tasks

0

Sign in to get full access
Overview
- Explores the interplay between generalization and memorization in natural language classification tasks
- Proposes a novel technique called "memorization localization" to analyze the memorization patterns of language models
- Provides empirical insights into the generalization and memorization dynamics of language models
Plain English Explanation
The paper investigates the balance between generalization and memorization in how language models perform on natural language classification tasks. The researchers introduce a new technique called "memorization localization" that allows them to analyze where and how language models are memorizing information, rather than just generalizing from the training data.
The key idea is that language models don't just learn general patterns from the data - they also memorize specific instances or examples. The paper aims to better understand this memorization process and how it interacts with a model's ability to generalize to new, unseen examples.
By applying their memorization localization approach, the researchers provide insights into the complex dynamics between generalization and memorization in state-of-the-art language models. This offers a more nuanced view of model capabilities and limitations, which could inform the development of more robust and reliable language AI systems.
Technical Explanation
The paper proposes a novel technique called "memorization localization" to analyze the memorization patterns of language models in natural language classification tasks. This approach goes beyond simply measuring overall model performance and instead seeks to identify which specific input regions or features a model has memorized.
The core idea is to generate "memorization maps" that highlight the input regions that a model has memorized, rather than generalized from. This is accomplished by carefully designed probing experiments that measure a model's confidence on specific input variants. By comparing the model's responses to original and perturbed inputs, the researchers can isolate the memorized components.
The authors apply this memorization localization technique to examine the generalization and memorization dynamics of state-of-the-art language models on a range of common natural language classification tasks. Their empirical analysis provides insights into how models balance generalization and memorization, and how this varies across different model architectures and training regimes.
The paper's findings suggest that while language models exhibit impressive generalization capabilities, they also rely heavily on memorization of specific training examples. The researchers demonstrate how this memorization can be localized and quantified, offering a more nuanced understanding of model strengths and weaknesses.
Critical Analysis
The paper makes a valuable contribution by introducing the novel concept of "memorization localization" and applying it to shed light on the interplay between generalization and memorization in language models. This provides a more fine-grained analysis of model capabilities than simply measuring overall task performance.
However, the authors acknowledge several limitations and caveats to their approach. For example, the proposed probing techniques rely on carefully constructed input perturbations, which may not fully capture the true complexity of how language models learn and reason. Additionally, the analysis is limited to a relatively narrow set of classification tasks, and it's unclear how the findings would generalize to other language understanding problems.
Furthermore, while the paper offers insights into the memorization patterns of language models, it doesn't provide a clear roadmap for how to leverage this understanding to improve model robustness or generalization. Additional research will be needed to translate these analytical techniques into practical model development strategies.
Conclusion
This paper presents a novel "memorization localization" approach to analyzing the interplay between generalization and memorization in natural language classification tasks. By going beyond simple performance metrics, the researchers are able to provide more nuanced insights into the strengths and limitations of state-of-the-art language models.
The findings suggest that while these models exhibit impressive generalization capabilities, they also heavily rely on memorization of specific training examples. This underscores the importance of developing a deeper understanding of how language models learn and reason, which could lead to the creation of more robust and reliable AI systems for natural language processing.
Overall, the paper offers a valuable contribution to the ongoing research on understanding the inner workings of language models, and it lays the groundwork for future investigations into the complex dynamics between generalization and memorization in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generalisation First, Memorisation Second? Memorisation Localisation for Natural Language Classification Tasks
Verna Dankers, Ivan Titov
Memorisation is a natural part of learning from real-world data: neural models pick up on atypical input-output combinations and store those training examples in their parameter space. That this happens is well-known, but how and where are questions that remain largely unanswered. Given a multi-layered neural model, where does memorisation occur in the millions of parameters? Related work reports conflicting findings: a dominant hypothesis based on image classification is that lower layers learn generalisable features and that deeper layers specialise and memorise. Work from NLP suggests this does not apply to language models, but has been mainly focused on memorisation of facts. We expand the scope of the localisation question to 12 natural language classification tasks and apply 4 memorisation localisation techniques. Our results indicate that memorisation is a gradual process rather than a localised one, establish that memorisation is task-dependent, and give nuance to the generalisation first, memorisation second hypothesis.
Read more8/12/2024
0
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Antonis Antoniades, Xinyi Wang, Yanai Elazar, Alfonso Amayuelas, Alon Albalak, Kexun Zhang, William Yang Wang
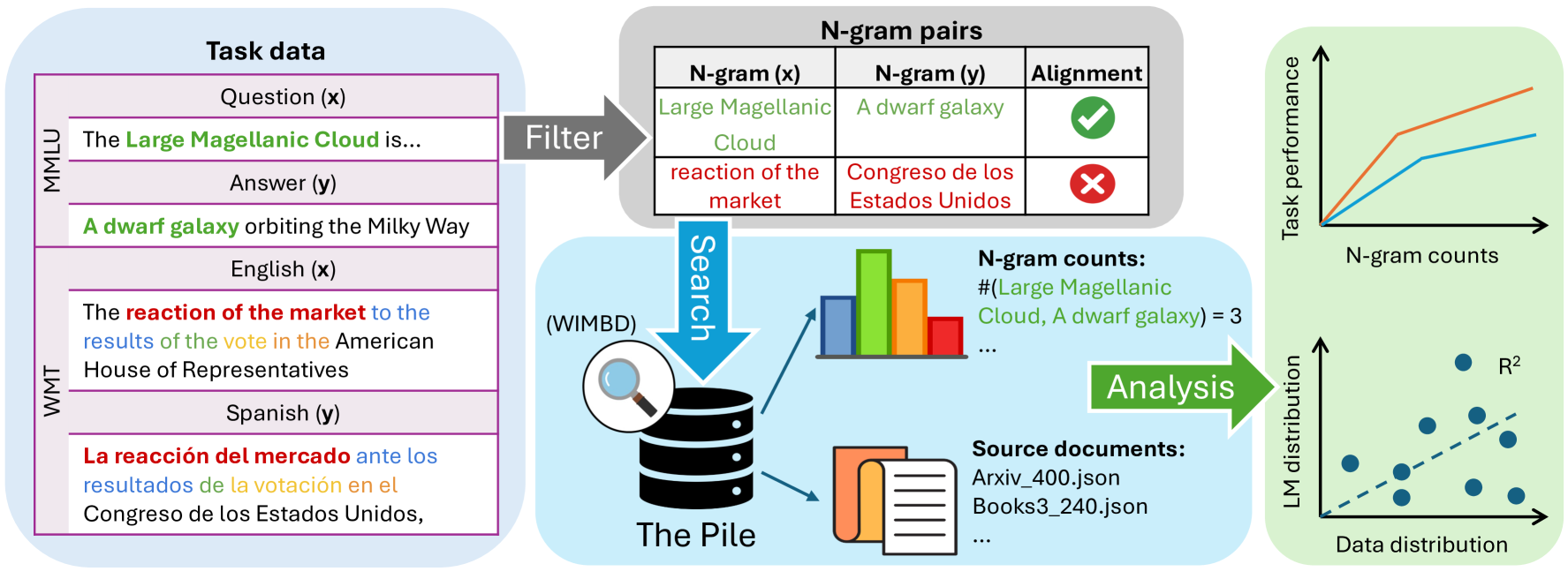
Despite the proven utility of large language models (LLMs) in real-world applications, there remains a lack of understanding regarding how they leverage their large-scale pretraining text corpora to achieve such capabilities. In this work, we investigate the interplay between generalization and memorization in pretrained LLMs at scale, through a comprehensive $n$-gram analysis of their training data. Our experiments focus on three general task types: translation, question-answering, and multiple-choice reasoning. With various sizes of open-source LLMs and their pretraining corpora, we observe that as the model size increases, the task-relevant $n$-gram pair data becomes increasingly important, leading to improved task performance, decreased memorization, stronger generalization, and emergent abilities. Our results support the hypothesis that LLMs' capabilities emerge from a delicate balance of memorization and generalization with sufficient task-related pretraining data, and point the way to larger-scale analyses that could further improve our understanding of these models.
Read more7/23/2024

0
Memorization in deep learning: A survey
Jiaheng Wei, Yanjun Zhang, Leo Yu Zhang, Ming Ding, Chao Chen, Kok-Leong Ong, Jun Zhang, Yang Xiang
Deep Learning (DL) powered by Deep Neural Networks (DNNs) has revolutionized various domains, yet understanding the intricacies of DNN decision-making and learning processes remains a significant challenge. Recent investigations have uncovered an interesting memorization phenomenon in which DNNs tend to memorize specific details from examples rather than learning general patterns, affecting model generalization, security, and privacy. This raises critical questions about the nature of generalization in DNNs and their susceptibility to security breaches. In this survey, we present a systematic framework to organize memorization definitions based on the generalization and security/privacy domains and summarize memorization evaluation methods at both the example and model levels. Through a comprehensive literature review, we explore DNN memorization behaviors and their impacts on security and privacy. We also introduce privacy vulnerabilities caused by memorization and the phenomenon of forgetting and explore its connection with memorization. Furthermore, we spotlight various applications leveraging memorization and forgetting mechanisms, including noisy label learning, privacy preservation, and model enhancement. This survey offers the first-in-kind understanding of memorization in DNNs, providing insights into its challenges and opportunities for enhancing AI development while addressing critical ethical concerns.
Read more6/7/2024

0
A Multi-Perspective Analysis of Memorization in Large Language Models
Bowen Chen, Namgi Han, Yusuke Miyao
Large Language Models (LLMs), trained on massive corpora with billions of parameters, show unprecedented performance in various fields. Though surprised by their excellent performances, researchers also noticed some special behaviors of those LLMs. One of those behaviors is memorization, in which LLMs can generate the same content used to train them. Though previous research has discussed memorization, the memorization of LLMs still lacks explanation, especially the cause of memorization and the dynamics of generating them. In this research, we comprehensively discussed memorization from various perspectives and extended the discussion scope to not only just the memorized content but also less and unmemorized content. Through various studies, we found that: (1) Through experiments, we revealed the relation of memorization between model size, continuation size, and context size. Further, we showed how unmemorized sentences transition to memorized sentences. (2) Through embedding analysis, we showed the distribution and decoding dynamics across model size in embedding space for sentences with different memorization scores. The n-gram statistics analysis presents d (3) An analysis over n-gram and entropy decoding dynamics discovered a boundary effect when the model starts to generate memorized sentences or unmemorized sentences. (4)We trained a Transformer model to predict the memorization of different models, showing that it is possible to predict memorizations by context.
Read more6/5/2024