Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data

0
Sign in to get full access
Overview
- This paper investigates the ability of large language models (LLMs) to memorize and recall factual information.
- The researchers conducted experiments to understand how LLMs acquire and store knowledge, and how this knowledge can be accessed and used.
- The findings provide insights into the inner workings of LLMs and have implications for the development of more capable and trustworthy AI systems.
Plain English Explanation
The paper explores how large language models are able to memorize and recall factual information. Large language models are AI systems that can understand and generate human-like text. The researchers wanted to understand how these models acquire and store knowledge, and how they can access and use this knowledge.
The researchers designed experiments to test the models' ability to remember and retrieve specific facts. They found that LLMs can indeed memorize a significant amount of information, but the way they store and access this knowledge is not always straightforward. The models can sometimes recall facts accurately, but they can also make mistakes or exhibit biases in how they use the information.
Understanding the memory and knowledge capabilities of LLMs is important for developing more capable and trustworthy AI systems. The findings from this research can help inform the design and deployment of LLMs in a wide range of applications, from language processing to question-answering and beyond.
Technical Explanation
The paper investigates the ability of large language models (LLMs) to memorize and recall factual information. The researchers conducted a series of experiments to understand how LLMs acquire and store knowledge, and how this knowledge can be accessed and used.
The experiment design involved training LLMs on large text corpora and then testing their ability to recall specific facts. The researchers used a variety of techniques, including probing the models' internal representations and analyzing their outputs, to gain insights into the models' knowledge acquisition and retrieval processes.
The results showed that LLMs can indeed memorize a significant amount of factual information, but the way they store and access this knowledge is not always straightforward. The models were able to accurately recall many facts, but they also exhibited biases and made mistakes in their knowledge retrieval. The researchers found that the models' performance was influenced by factors such as the nature of the training data, the model architecture, and the specific task or prompt used.
The insights from this research have important implications for the development of more capable and trustworthy AI systems. Understanding the memory and knowledge capabilities of LLMs can inform the design of AI architectures that can more reliably and transparently access and utilize the information they have learned. This, in turn, can lead to the development of AI systems that are better equipped to tackle a wide range of real-world problems.
Critical Analysis
The paper provides a thorough and well-designed investigation into the memory and knowledge capabilities of large language models. The researchers' use of a variety of experimental techniques, including probing the models' internal representations and analyzing their outputs, is particularly commendable as it allows for a more comprehensive understanding of how these models acquire and store information.
One potential limitation of the study is the reliance on a limited set of training corpora and test datasets. While the researchers made efforts to ensure the diversity of the data, it is possible that the findings may not be fully generalizable to other domains or applications. Additionally, the paper does not delve deeply into the potential societal implications of the observed biases and limitations in the models' knowledge retrieval, an area that warrants further exploration.
Another area for further research could be the development of techniques to better understand and mitigate the potential risks associated with the memorization and retrieval of factual information by large language models. As these models become more widely adopted, it will be crucial to ensure that the knowledge they possess is accurate, up-to-date, and appropriately contextualized.
Overall, this paper makes a valuable contribution to the ongoing efforts to understand the inner workings of large language models and their implications for the development of more capable and trustworthy AI systems. The findings provide a solid foundation for future research in this important and rapidly evolving field.
Conclusion
This paper presents a detailed investigation into the ability of large language models to memorize and recall factual information. The researchers conducted a series of experiments to understand how LLMs acquire and store knowledge, and how this knowledge can be accessed and used.
The findings reveal that LLMs can indeed memorize a significant amount of information, but the way they store and retrieve this knowledge is not always straightforward. The models can accurately recall many facts, but they also exhibit biases and make mistakes in their knowledge retrieval.
These insights have important implications for the development of more capable and trustworthy AI systems. By understanding the memory and knowledge capabilities of LLMs, researchers can work towards designing AI architectures that can more reliably and transparently access and utilize the information they have learned. This, in turn, can lead to the development of AI systems that are better equipped to tackle a wide range of real-world problems.
The paper also highlights the need for further research into the potential risks and societal implications of the memorization and retrieval of factual information by large language models. As these models become more widely adopted, it will be crucial to ensure that the knowledge they possess is accurate, up-to-date, and appropriately contextualized.
Overall, this study makes a valuable contribution to the ongoing efforts to understand the inner workings of large language models and their potential impact on the development of more capable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Antonis Antoniades, Xinyi Wang, Yanai Elazar, Alfonso Amayuelas, Alon Albalak, Kexun Zhang, William Yang Wang
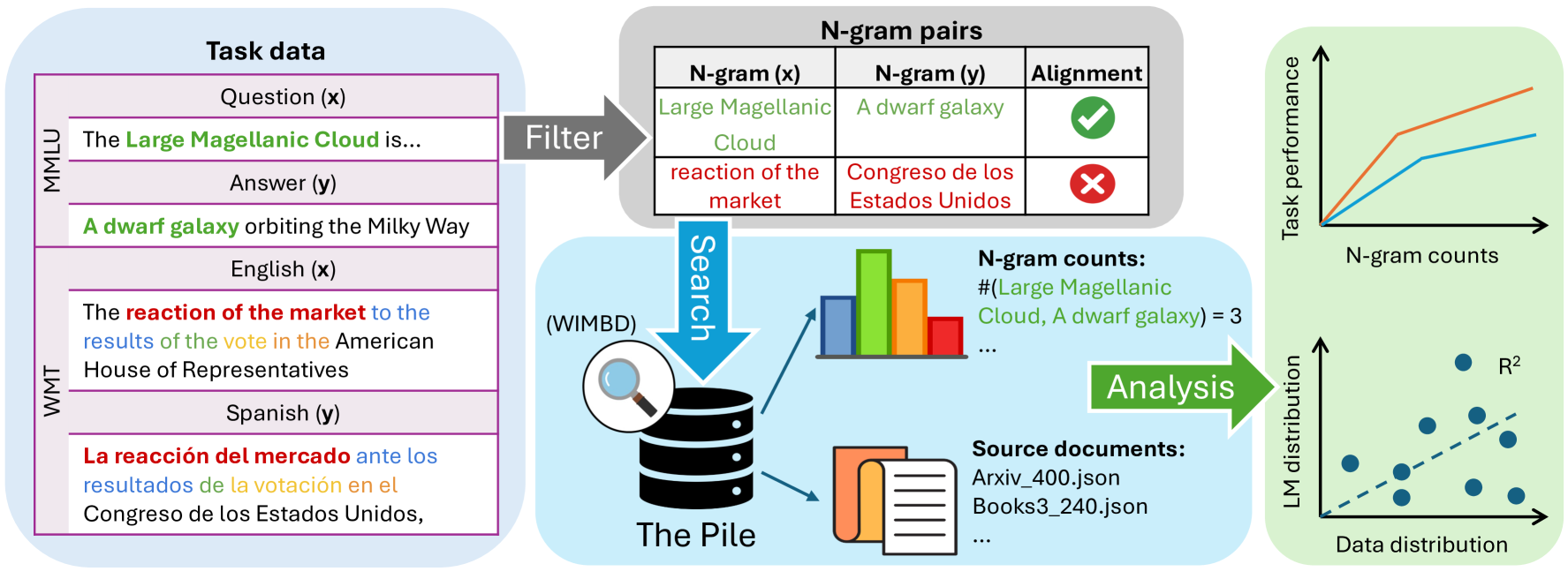
Despite the proven utility of large language models (LLMs) in real-world applications, there remains a lack of understanding regarding how they leverage their large-scale pretraining text corpora to achieve such capabilities. In this work, we investigate the interplay between generalization and memorization in pretrained LLMs at scale, through a comprehensive $n$-gram analysis of their training data. Our experiments focus on three general task types: translation, question-answering, and multiple-choice reasoning. With various sizes of open-source LLMs and their pretraining corpora, we observe that as the model size increases, the task-relevant $n$-gram pair data becomes increasingly important, leading to improved task performance, decreased memorization, stronger generalization, and emergent abilities. Our results support the hypothesis that LLMs' capabilities emerge from a delicate balance of memorization and generalization with sufficient task-related pretraining data, and point the way to larger-scale analyses that could further improve our understanding of these models.
Read more7/23/2024

0
A Multi-Perspective Analysis of Memorization in Large Language Models
Bowen Chen, Namgi Han, Yusuke Miyao
Large Language Models (LLMs), trained on massive corpora with billions of parameters, show unprecedented performance in various fields. Though surprised by their excellent performances, researchers also noticed some special behaviors of those LLMs. One of those behaviors is memorization, in which LLMs can generate the same content used to train them. Though previous research has discussed memorization, the memorization of LLMs still lacks explanation, especially the cause of memorization and the dynamics of generating them. In this research, we comprehensively discussed memorization from various perspectives and extended the discussion scope to not only just the memorized content but also less and unmemorized content. Through various studies, we found that: (1) Through experiments, we revealed the relation of memorization between model size, continuation size, and context size. Further, we showed how unmemorized sentences transition to memorized sentences. (2) Through embedding analysis, we showed the distribution and decoding dynamics across model size in embedding space for sentences with different memorization scores. The n-gram statistics analysis presents d (3) An analysis over n-gram and entropy decoding dynamics discovered a boundary effect when the model starts to generate memorized sentences or unmemorized sentences. (4)We trained a Transformer model to predict the memorization of different models, showing that it is possible to predict memorizations by context.
Read more6/5/2024

0
Generalisation First, Memorisation Second? Memorisation Localisation for Natural Language Classification Tasks
Verna Dankers, Ivan Titov
Memorisation is a natural part of learning from real-world data: neural models pick up on atypical input-output combinations and store those training examples in their parameter space. That this happens is well-known, but how and where are questions that remain largely unanswered. Given a multi-layered neural model, where does memorisation occur in the millions of parameters? Related work reports conflicting findings: a dominant hypothesis based on image classification is that lower layers learn generalisable features and that deeper layers specialise and memorise. Work from NLP suggests this does not apply to language models, but has been mainly focused on memorisation of facts. We expand the scope of the localisation question to 12 natural language classification tasks and apply 4 memorisation localisation techniques. Our results indicate that memorisation is a gradual process rather than a localised one, establish that memorisation is task-dependent, and give nuance to the generalisation first, memorisation second hypothesis.
Read more8/12/2024

0
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment
Kun Luo, Minghao Qin, Zheng Liu, Shitao Xiao, Jun Zhao, Kang Liu
Pretrained language models like BERT and T5 serve as crucial backbone encoders for dense retrieval. However, these models often exhibit limited generalization capabilities and face challenges in improving in domain accuracy. Recent research has explored using large language models (LLMs) as retrievers, achieving SOTA performance across various tasks. Despite these advancements, the specific benefits of LLMs over traditional retrievers and the impact of different LLM configurations, such as parameter sizes, pretraining duration, and alignment processes on retrieval tasks remain unclear. In this work, we conduct a comprehensive empirical study on a wide range of retrieval tasks, including in domain accuracy, data efficiency, zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. We evaluate over 15 different backbone LLMs and non LLMs. Our findings reveal that larger models and extensive pretraining consistently enhance in domain accuracy and data efficiency. Additionally, larger models demonstrate significant potential in zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. These results underscore the advantages of LLMs as versatile and effective backbone encoders in dense retrieval, providing valuable insights for future research and development in this field.
Read more8/26/2024