Generalization Ability of Feature-based Performance Prediction Models: A Statistical Analysis across Benchmarks
2405.12259
0
0
🚀
Abstract
This study examines the generalization ability of algorithm performance prediction models across various benchmark suites. Comparing the statistical similarity between the problem collections with the accuracy of performance prediction models that are based on exploratory landscape analysis features, we observe that there is a positive correlation between these two measures. Specifically, when the high-dimensional feature value distributions between training and testing suites lack statistical significance, the model tends to generalize well, in the sense that the testing errors are in the same range as the training errors. Two experiments validate these findings: one involving the standard benchmark suites, the BBOB and CEC collections, and another using five collections of affine combinations of BBOB problem instances.
Create account to get full access
Overview
- This study examines how well algorithm performance prediction models can generalize across different benchmark suites.
- The researchers compare the statistical similarity between the problem collections with the accuracy of performance prediction models that use exploratory landscape analysis features.
- They find a positive correlation between these two measures - when the feature distributions between training and testing suites are statistically similar, the models tend to generalize well.
Plain English Explanation
The researchers in this study wanted to understand how well models that predict the performance of algorithms can work across different test sets, or "benchmark suites." They looked at the statistical properties of the problems in these benchmark suites and compared them to how accurately the prediction models performed.
Specifically, they found that when the high-dimensional feature values (like how "difficult" or "smooth" the problems are) have similar statistical distributions between the training and testing data, the prediction models tend to do well on the new test problems. In other words, if the training and testing problems are statistically similar, the models can generalize and make accurate predictions on the new problems.
This is an important finding because it suggests that the generalization abilities of these algorithm performance prediction models depend a lot on how statistically representative the training data is of the real-world problems the models will encounter. If the training and testing data come from very different distributions, the models may struggle to make accurate predictions on new problems.
Technical Explanation
The researchers conducted two main experiments to test their hypothesis. In the first experiment, they used standard benchmark suites like the BBOB and CEC collections. They calculated the statistical similarity between the feature value distributions of the training and testing problems, and compared this to the accuracy of performance prediction models trained on the training problems and evaluated on the testing problems.
In the second experiment, the researchers created a new set of benchmark problems by taking affine combinations of the BBOB problems. This allowed them to systematically control the statistical similarity between the training and testing data and observe its impact on model generalization.
Overall, the results from both experiments showed a positive correlation between the statistical similarity of the training and testing problems, and the ability of the performance prediction models to generalize. When the high-dimensional feature distributions were statistically similar, the models were able to make accurate predictions on the new testing problems.
Critical Analysis
The researchers acknowledge several limitations in their work. First, they only looked at a specific type of performance prediction model based on exploratory landscape analysis features. It's possible that other model architectures or feature representations may behave differently in terms of generalization.
Additionally, the researchers focused solely on the statistical similarity of the problem features, but did not consider other factors that could impact model generalization, such as the underlying problem structure or the specific algorithmic properties being predicted.
Further research is needed to fully understand the various factors that affect the generalization capabilities of algorithm performance prediction models, and to develop techniques for improving their robustness to distributional shifts in the data.
Conclusion
This study provides valuable insights into the generalization abilities of algorithm performance prediction models. The key finding is that these models tend to perform well on new problems when the statistical distributions of the high-dimensional problem features are similar between the training and testing data. This suggests that careful curation and representation of the training data is crucial for developing robust and generalizable models in this domain.
The implications of this research extend beyond just algorithm performance prediction, and could inform the development of more generalizable machine learning models across a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
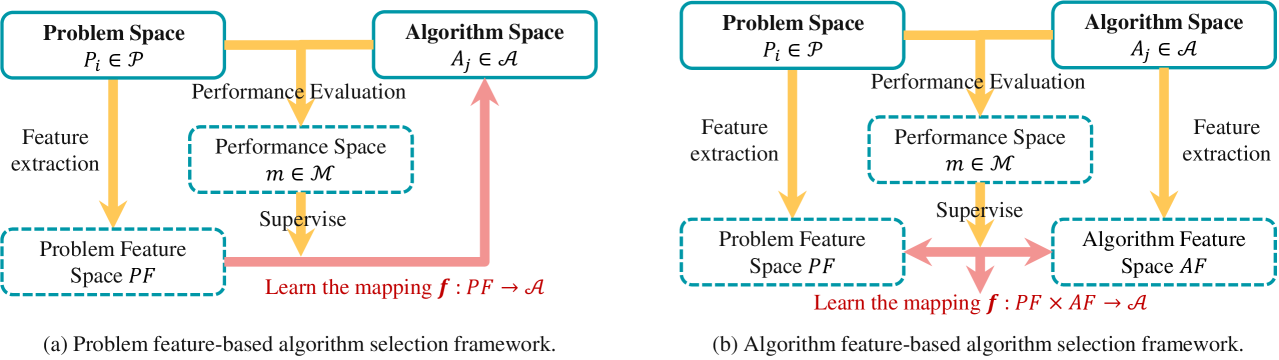
Unlock the Power of Algorithm Features: A Generalization Analysis for Algorithm Selection
Xingyu Wu, Yan Zhong, Jibin Wu, Yuxiao Huang, Sheng-hao Wu, Kay Chen Tan
0
0
In the algorithm selection research, the discussion surrounding algorithm features has been significantly overshadowed by the emphasis on problem features. Although a few empirical studies have yielded evidence regarding the effectiveness of algorithm features, the potential benefits of incorporating algorithm features into algorithm selection models and their suitability for different scenarios remain unclear. In this paper, we address this gap by proposing the first provable guarantee for algorithm selection based on algorithm features, taking a generalization perspective. We analyze the benefits and costs associated with algorithm features and investigate how the generalization error is affected by different factors. Specifically, we examine adaptive and predefined algorithm features under transductive and inductive learning paradigms, respectively, and derive upper bounds for the generalization error based on their model's Rademacher complexity. Our theoretical findings not only provide tight upper bounds, but also offer analytical insights into the impact of various factors, such as the training scale of problem instances and candidate algorithms, model parameters, feature values, and distributional differences between the training and test data. Notably, we demonstrate how models will benefit from algorithm features in complex scenarios involving many algorithms, and proves the positive correlation between generalization error bound and $chi^2$-divergence of distributions.
6/4/2024

Assessing Model Generalization in Vicinity
Yuchi Liu, Yifan Sun, Jingdong Wang, Liang Zheng
0
0
This paper evaluates the generalization ability of classification models on out-of-distribution test sets without depending on ground truth labels. Common approaches often calculate an unsupervised metric related to a specific model property, like confidence or invariance, which correlates with out-of-distribution accuracy. However, these metrics are typically computed for each test sample individually, leading to potential issues caused by spurious model responses, such as overly high or low confidence. To tackle this challenge, we propose incorporating responses from neighboring test samples into the correctness assessment of each individual sample. In essence, if a model consistently demonstrates high correctness scores for nearby samples, it increases the likelihood of correctly predicting the target sample, and vice versa. The resulting scores are then averaged across all test samples to provide a holistic indication of model accuracy. Developed under the vicinal risk formulation, this approach, named vicinal risk proxy (VRP), computes accuracy without relying on labels. We show that applying the VRP method to existing generalization indicators, such as average confidence and effective invariance, consistently improves over these baselines both methodologically and experimentally. This yields a stronger correlation with model accuracy, especially on challenging out-of-distribution test sets.
6/14/2024

On the Robustness of Global Feature Effect Explanations
Hubert Baniecki, Giuseppe Casalicchio, Bernd Bischl, Przemyslaw Biecek
0
0
We study the robustness of global post-hoc explanations for predictive models trained on tabular data. Effects of predictor features in black-box supervised learning are an essential diagnostic tool for model debugging and scientific discovery in applied sciences. However, how vulnerable they are to data and model perturbations remains an open research question. We introduce several theoretical bounds for evaluating the robustness of partial dependence plots and accumulated local effects. Our experimental results with synthetic and real-world datasets quantify the gap between the best and worst-case scenarios of (mis)interpreting machine learning predictions globally.
6/14/2024

Examining the robustness of LLM evaluation to the distributional assumptions of benchmarks
Melissa Ailem, Katerina Marazopoulou, Charlotte Siska, James Bono
0
0
Benchmarks have emerged as the central approach for evaluating Large Language Models (LLMs). The research community often relies on a model's average performance across the test prompts of a benchmark to evaluate the model's performance. This is consistent with the assumption that the test prompts within a benchmark represent a random sample from a real-world distribution of interest. We note that this is generally not the case; instead, we hold that the distribution of interest varies according to the specific use case. We find that (1) the correlation in model performance across test prompts is non-random, (2) accounting for correlations across test prompts can change model rankings on major benchmarks, (3) explanatory factors for these correlations include semantic similarity and common LLM failure points.
6/7/2024