Evaluating LLMs at Evaluating Temporal Generalization
2405.08460
0
0
⛏️
Abstract
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
Create account to get full access
Overview
- The rapid advancement of Large Language Models (LLMs) has highlighted the need for evolving evaluation methodologies that can keep pace with improvements in language comprehension and information processing.
- Traditional static benchmarks fail to capture the continually changing information landscape, leading to a disparity between perceived and actual LLM effectiveness in real-world scenarios.
- The paper examines current LLMs in terms of temporal generalization and bias, revealing various temporal biases in both language likelihood and prognostic prediction.
- The authors propose an evaluation framework called FreshBench for dynamically generating benchmarks from the most recent real-world prognostication prediction.
Plain English Explanation
As Large Language Models (LLMs) continue to advance rapidly, the way we evaluate their performance needs to evolve as well. Traditional benchmarks, which are often static, don't keep up with the constantly changing information that these models are designed to process.
This means that the perceived effectiveness of LLMs may not match their actual performance in real-world situations. The paper looks at how LLMs behave over time, and finds that they can develop biases based on when the information they're trained on was collected. For example, an LLM trained on data from 2020 might make different predictions than one trained on data from 2022, even if they're otherwise similar.
To address this issue, the researchers propose a new evaluation framework called FreshBench. FreshBench uses the most up-to-date real-world data to generate constantly evolving benchmarks for testing LLMs. This helps ensure that the models are being evaluated based on their ability to adapt to changing information, rather than just their performance on static tests.
Technical Explanation
The paper examines the temporal generalization and bias of current Large Language Models (LLMs). The researchers find that various temporal biases emerge in both language likelihood and prognostic prediction tasks, indicating that LLMs may not be as temporally robust as previously assumed.
To address this issue, the authors propose FreshBench, an evaluation framework that dynamically generates benchmarks from the most recent real-world prognostication prediction data. This approach aims to capture the continually changing information landscape and better assess the models' adaptability over time.
The authors demonstrate the effectiveness of FreshBench through experiments on several popular LLMs, revealing significant temporal biases and performance degradation over time. This underscores the need for more robust and dynamic evaluation methodologies that can keep pace with the rapid advancements in language models.
Critical Analysis
The paper provides a valuable contribution to the ongoing discussion around the limitations of traditional LLM evaluation methodologies. The authors' identification of temporal biases in both language likelihood and prognostic prediction tasks is an important finding that highlights the need for more sophisticated evaluation approaches.
While the FreshBench framework is a promising solution, its long-term viability and scalability across different domains and tasks remain to be seen. Additionally, the paper does not address the potential challenges of implementing such a dynamic evaluation system in practice, such as the computational resources required or the difficulty of maintaining a constantly updated dataset.
Further research is needed to explore other approaches to temporal bias mitigation and to investigate the broader implications of these findings for the development and deployment of LLMs in real-world applications.
Conclusion
This paper underscores the urgent need for evolving evaluation methodologies that can keep pace with the rapid advancements in Large Language Models (LLMs). The identification of temporal biases in both language likelihood and prognostic prediction tasks highlights the limitations of traditional static benchmarks and the disparity between perceived and actual LLM effectiveness.
The authors' proposed FreshBench framework offers a promising approach to dynamically evaluating LLMs, but further research is needed to address the practical challenges of implementation and to explore other strategies for mitigating temporal biases. As the field of language models continues to evolve, it is crucial that evaluation methodologies keep pace to ensure the reliable and responsible development of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, Bryan Perozzi
0
0
Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
6/14/2024
New!STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Wenbin Li, Di Yao, Ruibo Zhao, Wenjie Chen, Zijie Xu, Chengxue Luo, Chang Gong, Quanliang Jing, Haining Tan, Jingping Bi
0
0
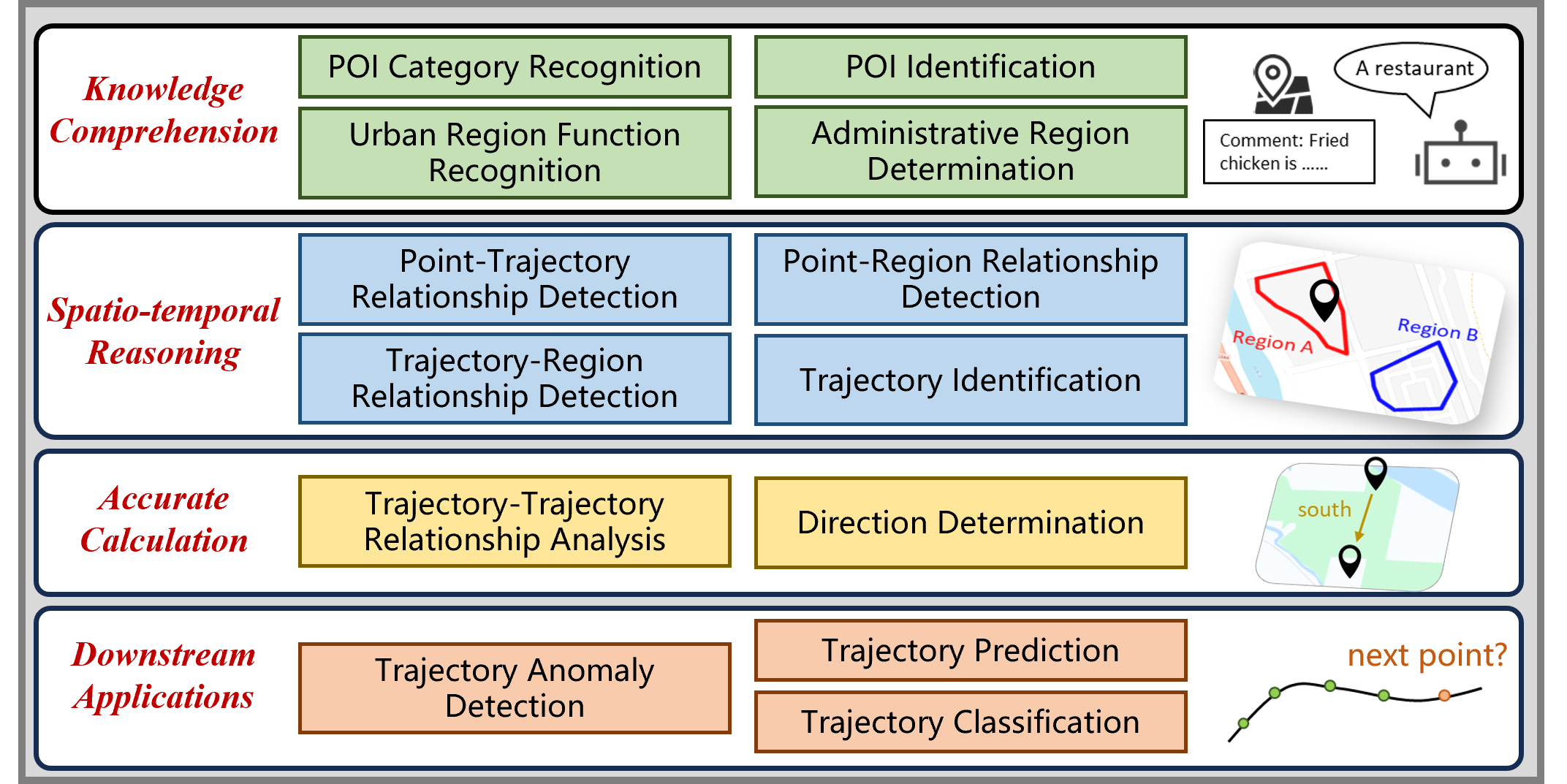
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
6/28/2024
Is Your LLM Outdated? Benchmarking LLMs & Alignment Algorithms for Time-Sensitive Knowledge
Seyed Mahed Mousavi, Simone Alghisi, Giuseppe Riccardi
0
0
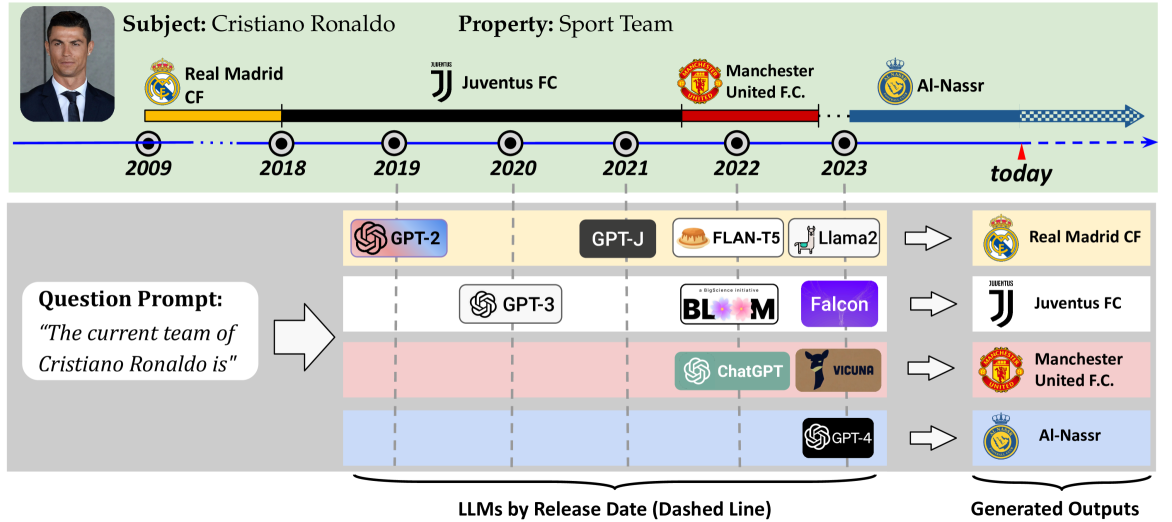
LLMs acquire knowledge from massive data snapshots collected at different timestamps. Their knowledge is then commonly evaluated using static benchmarks. However, factual knowledge is generally subject to time-sensitive changes, and static benchmarks cannot address those cases. We present an approach to dynamically evaluate the knowledge in LLMs and their time-sensitiveness against Wikidata, a publicly available up-to-date knowledge graph. We evaluate the time-sensitive knowledge in twenty-four private and open-source LLMs, as well as the effectiveness of four editing methods in updating the outdated facts. Our results show that 1) outdatedness is a critical problem across state-of-the-art LLMs; 2) LLMs output inconsistent answers when prompted with slight variations of the question prompt; and 3) the performance of the state-of-the-art knowledge editing algorithms is very limited, as they can not reduce the cases of outdatedness and output inconsistency.
6/13/2024
Evaluating the Generalization Ability of Quantized LLMs: Benchmark, Analysis, and Toolbox
Yijun Liu, Yuan Meng, Fang Wu, Shenhao Peng, Hang Yao, Chaoyu Guan, Chen Tang, Xinzhu Ma, Zhi Wang, Wenwu Zhu
0
0
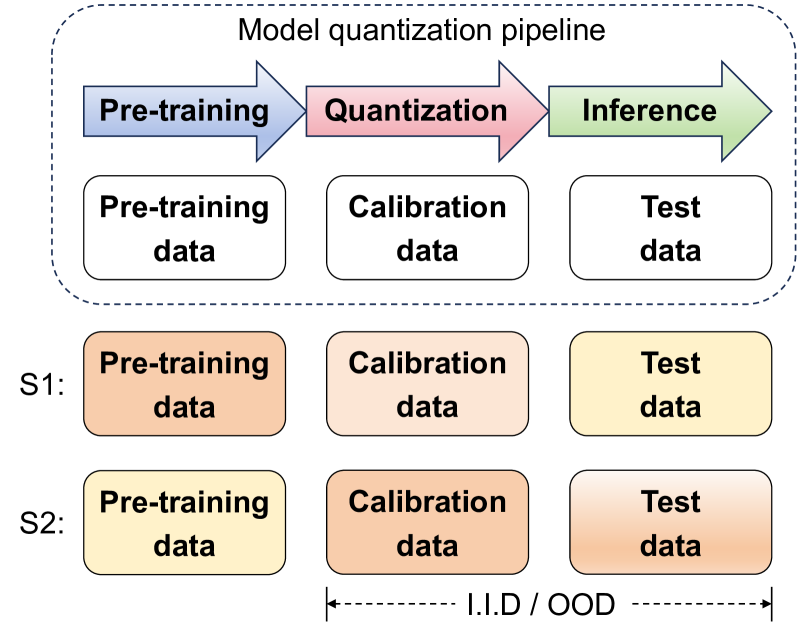
Large language models (LLMs) have exhibited exciting progress in multiple scenarios, while the huge computational demands hinder their deployments in lots of real-world applications. As an effective means to reduce memory footprint and inference cost, quantization also faces challenges in performance degradation at low bit-widths. Understanding the impact of quantization on LLM capabilities, especially the generalization ability, is crucial. However, the community's main focus remains on the algorithms and models of quantization, with insufficient attention given to whether the quantized models can retain the strong generalization abilities of LLMs. In this work, we fill this gap by providing a comprehensive benchmark suite for this research topic, including an evaluation system, detailed analyses, and a general toolbox. Specifically, based on the dominant pipeline in LLM quantization, we primarily explore the impact of calibration data distribution on the generalization of quantized LLMs and conduct the benchmark using more than 40 datasets within two main scenarios. Based on this benchmark, we conduct extensive experiments with two well-known LLMs (English and Chinese) and four quantization algorithms to investigate this topic in-depth, yielding several counter-intuitive and valuable findings, e.g., models quantized using a calibration set with the same distribution as the test data are not necessarily optimal. Besides, to facilitate future research, we also release a modular-designed toolbox, which decouples the overall pipeline into several separate components, e.g., base LLM module, dataset module, quantizer module, etc. and allows subsequent researchers to easily assemble their methods through a simple configuration. Our benchmark suite is publicly available at https://github.com/TsingmaoAI/MI-optimize
6/21/2024