Generalization error of min-norm interpolators in transfer learning
2406.13944
0
0

Abstract
This paper establishes the generalization error of pooled min-$ell_2$-norm interpolation in transfer learning where data from diverse distributions are available. Min-norm interpolators emerge naturally as implicit regularized limits of modern machine learning algorithms. Previous work characterized their out-of-distribution risk when samples from the test distribution are unavailable during training. However, in many applications, a limited amount of test data may be available during training, yet properties of min-norm interpolation in this setting are not well-understood. We address this gap by characterizing the bias and variance of pooled min-$ell_2$-norm interpolation under covariate and model shifts. The pooled interpolator captures both early fusion and a form of intermediate fusion. Our results have several implications: under model shift, for low signal-to-noise ratio (SNR), adding data always hurts. For higher SNR, transfer learning helps as long as the shift-to-signal (SSR) ratio lies below a threshold that we characterize explicitly. By consistently estimating these ratios, we provide a data-driven method to determine: (i) when the pooled interpolator outperforms the target-based interpolator, and (ii) the optimal number of target samples that minimizes the generalization error. Under covariate shift, if the source sample size is small relative to the dimension, heterogeneity between between domains improves the risk, and vice versa. We establish a novel anisotropic local law to achieve these characterizations, which may be of independent interest in random matrix theory. We supplement our theoretical characterizations with comprehensive simulations that demonstrate the finite-sample efficacy of our results.
Create account to get full access
Overview
- This paper investigates the generalization error of min-norm interpolators in the context of transfer learning.
- Min-norm interpolators are a class of machine learning models that try to fit the training data as closely as possible while minimizing the norm of the model parameters.
- The paper analyzes how the generalization error of min-norm interpolators scales with the number of training samples and the complexity of the task, with a focus on transfer learning scenarios.
Plain English Explanation
When training machine learning models, there is often a tradeoff between fitting the training data closely and having the model generalize well to new, unseen data. Min-norm interpolators are a type of model that tries to strike a balance by fitting the training data exactly, while keeping the overall complexity of the model (as measured by the norm of the parameters) as low as possible.
In the context of transfer learning, where a model trained on one task is used to solve a related but different task, the paper examines how the generalization error of min-norm interpolators scales. The researchers look at how factors like the number of training samples and the complexity of the target task affect the model's ability to generalize.
Technical Explanation
The paper analyzes the generalization error of min-norm interpolators in transfer learning scenarios. Specifically, the authors consider a setup where the model is first trained on a source task and then fine-tuned on a target task with a limited number of samples.
The key technical insights from the paper include:
- The generalization error of min-norm interpolators is shown to depend on the complexity of the target task, as measured by the Gaussian width of the function class. This relates to the concept of PAC-Chernoff bounds.
- The authors prove that the generalization error scales inversely with the number of training samples on the target task, similar to the behavior of standard regression models.
- The paper also investigates how the initialization of the model parameters from the source task affects the generalization performance on the target task. This connects to the phenomenon of non-uniform scaling of weights in deep networks.
- The analysis suggests that min-norm interpolators can exhibit favorable generalization properties in transfer learning scenarios, providing theoretical justification for their use in practice.
Critical Analysis
The paper provides a rigorous theoretical analysis of the generalization properties of min-norm interpolators in transfer learning. While the results are promising, there are a few potential limitations and areas for further research:
- The analysis assumes a specific setup with a limited number of training samples on the target task, which may not capture all the nuances of real-world transfer learning problems.
- The paper focuses on linear models, and it's unclear how the insights would extend to more complex, nonlinear architectures like deep neural networks.
- The theoretical analysis relies on certain simplifying assumptions, such as Gaussian noise and specific properties of the function classes, which may not always hold in practice.
Further research could explore the generalization of min-norm interpolators in more diverse transfer learning scenarios, including the use of modern neural network architectures and datasets. Empirical validation of the theoretical insights would also be valuable to assess the practical relevance of the findings.
Conclusion
This paper provides a rigorous theoretical analysis of the generalization properties of min-norm interpolators in the context of transfer learning. The key insights suggest that min-norm interpolators can exhibit favorable generalization behavior, with the generalization error scaling inversely with the number of training samples and depending on the complexity of the target task.
These findings have the potential to inform the design and use of min-norm interpolators in practical transfer learning applications, where the ability to generalize well from limited data is often crucial. While the analysis relies on certain simplifying assumptions, the paper contributes to our understanding of the underlying mechanisms governing the generalization of this class of machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
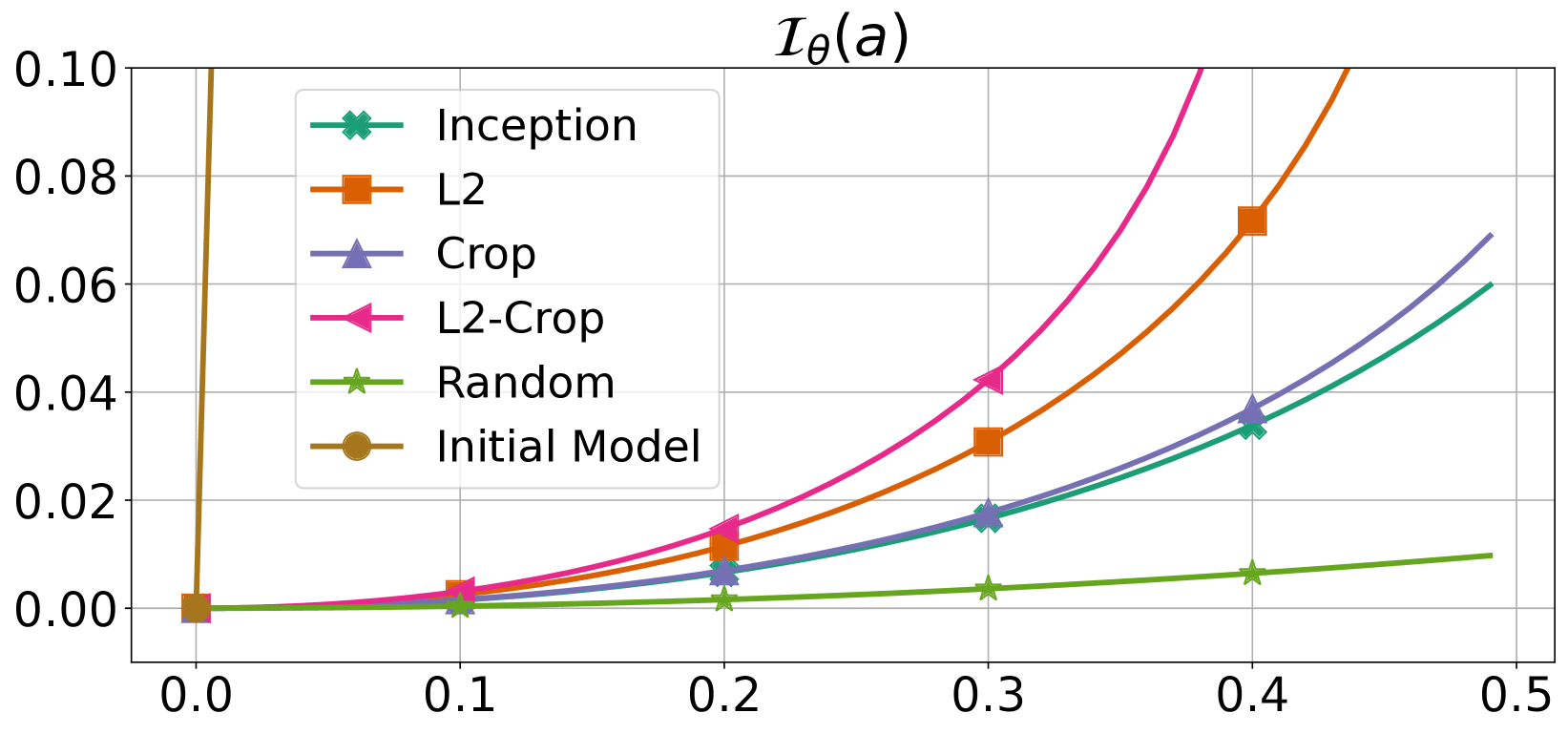
PAC-Chernoff Bounds: Understanding Generalization in the Interpolation Regime
Andr'es R. Masegosa, Luis A. Ortega
0
0
This paper introduces a distribution-dependent PAC-Chernoff bound that exhibits perfect tightness for interpolators, even within over-parameterized model classes. This bound, which relies on basic principles of Large Deviation Theory, defines a natural measure of the smoothness of a model, characterized by simple real-valued functions. Building upon this bound and the new concept of smoothness, we present an unified theoretical framework revealing why certain interpolators show an exceptional generalization, while others falter. We theoretically show how a wide spectrum of modern learning methodologies, encompassing techniques such as $ell_2$-norm, distance-from-initialization and input-gradient regularization, in combination with data augmentation, invariant architectures, and over-parameterization, collectively guide the optimizer toward smoother interpolators, which, according to our theoretical framework, are the ones exhibiting superior generalization performance. This study shows that distribution-dependent bounds serve as a powerful tool to understand the complex dynamics behind the generalization capabilities of over-parameterized interpolators.
4/30/2024
👨🏫
Fine-grained analysis of non-parametric estimation for pairwise learning
Junyu Zhou, Shuo Huang, Han Feng, Puyu Wang, Ding-Xuan Zhou
0
0
In this paper, we are concerned with the generalization performance of non-parametric estimation for pairwise learning. Most of the existing work requires the hypothesis space to be convex or a VC-class, and the loss to be convex. However, these restrictive assumptions limit the applicability of the results in studying many popular methods, especially kernel methods and neural networks. We significantly relax these restrictive assumptions and establish a sharp oracle inequality of the empirical minimizer with a general hypothesis space for the Lipschitz continuous pairwise losses. Our results can be used to handle a wide range of pairwise learning problems including ranking, AUC maximization, pairwise regression, and metric and similarity learning. As an application, we apply our general results to study pairwise least squares regression and derive an excess generalization bound that matches the minimax lower bound for pointwise least squares regression up to a logrithmic term. The key novelty here is to construct a structured deep ReLU neural network as an approximation of the true predictor and design the targeted hypothesis space consisting of the structured networks with controllable complexity. This successful application demonstrates that the obtained general results indeed help us to explore the generalization performance on a variety of problems that cannot be handled by existing approaches.
6/24/2024
🏅
Algebraic and Statistical Properties of the Ordinary Least Squares Interpolator
Dennis Shen, Dogyoon Song, Peng Ding, Jasjeet S. Sekhon
0
0
Deep learning research has uncovered the phenomenon of benign overfitting for overparameterized statistical models, which has drawn significant theoretical interest in recent years. Given its simplicity and practicality, the ordinary least squares (OLS) interpolator has become essential to gain foundational insights into this phenomenon. While properties of OLS are well established in classical, underparameterized settings, its behavior in high-dimensional, overparameterized regimes is less explored (unlike for ridge or lasso regression) though significant progress has been made of late. We contribute to this growing literature by providing fundamental algebraic and statistical results for the minimum $ell_2$-norm OLS interpolator. In particular, we provide algebraic equivalents of (i) the leave-$k$-out residual formula, (ii) Cochran's formula, and (iii) the Frisch-Waugh-Lovell theorem in the overparameterized regime. These results aid in understanding the OLS interpolator's ability to generalize and have substantive implications for causal inference. Under the Gauss-Markov model, we present statistical results such as an extension of the Gauss-Markov theorem and an analysis of variance estimation under homoskedastic errors for the overparameterized regime. To substantiate our theoretical contributions, we conduct simulations that further explore the stochastic properties of the OLS interpolator.
5/31/2024

How Uniform Random Weights Induce Non-uniform Bias: Typical Interpolating Neural Networks Generalize with Narrow Teachers
Gon Buzaglo, Itamar Harel, Mor Shpigel Nacson, Alon Brutzkus, Nathan Srebro, Daniel Soudry
0
0
Background. A main theoretical puzzle is why over-parameterized Neural Networks (NNs) generalize well when trained to zero loss (i.e., so they interpolate the data). Usually, the NN is trained with Stochastic Gradient Descent (SGD) or one of its variants. However, recent empirical work examined the generalization of a random NN that interpolates the data: the NN was sampled from a seemingly uniform prior over the parameters, conditioned on that the NN perfectly classifies the training set. Interestingly, such a NN sample typically generalized as well as SGD-trained NNs. Contributions. We prove that such a random NN interpolator typically generalizes well if there exists an underlying narrow ``teacher NN'' that agrees with the labels. Specifically, we show that such a `flat' prior over the NN parameterization induces a rich prior over the NN functions, due to the redundancy in the NN structure. In particular, this creates a bias towards simpler functions, which require less relevant parameters to represent -- enabling learning with a sample complexity approximately proportional to the complexity of the teacher (roughly, the number of non-redundant parameters), rather than the student's.
6/11/2024