PAC-Chernoff Bounds: Understanding Generalization in the Interpolation Regime
2306.10947
0
0
Abstract
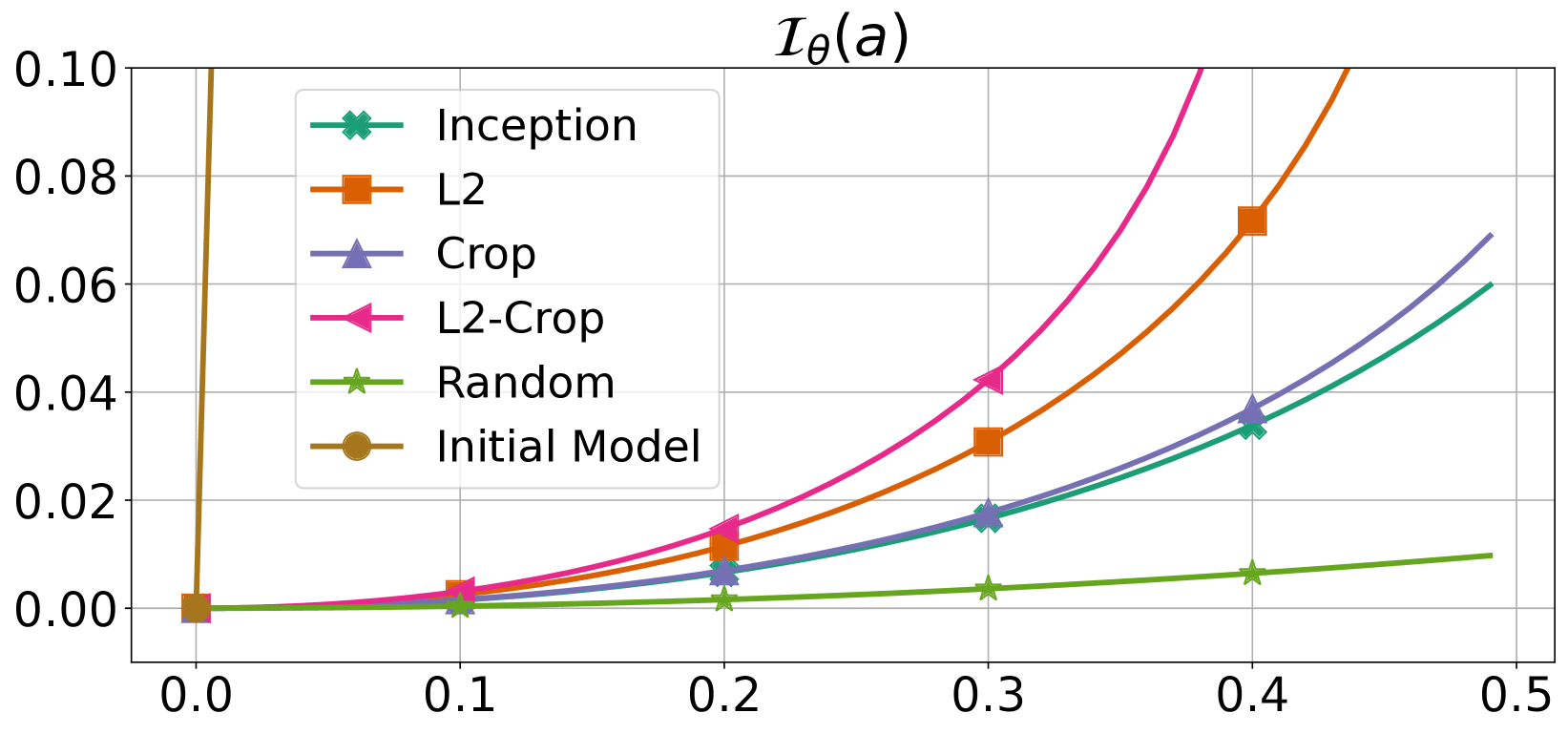
This paper introduces a distribution-dependent PAC-Chernoff bound that exhibits perfect tightness for interpolators, even within over-parameterized model classes. This bound, which relies on basic principles of Large Deviation Theory, defines a natural measure of the smoothness of a model, characterized by simple real-valued functions. Building upon this bound and the new concept of smoothness, we present an unified theoretical framework revealing why certain interpolators show an exceptional generalization, while others falter. We theoretically show how a wide spectrum of modern learning methodologies, encompassing techniques such as $ell_2$-norm, distance-from-initialization and input-gradient regularization, in combination with data augmentation, invariant architectures, and over-parameterization, collectively guide the optimizer toward smoother interpolators, which, according to our theoretical framework, are the ones exhibiting superior generalization performance. This study shows that distribution-dependent bounds serve as a powerful tool to understand the complex dynamics behind the generalization capabilities of over-parameterized interpolators.
Create account to get full access
Overview
- This paper investigates how well machine learning models can generalize, or perform on new data, in the "interpolation regime" where the model can perfectly fit the training data.
- The authors use a concept called the "rate function" to help understand this generalization behavior.
- They conduct experiments to explore how various factors like model complexity, data dimensionality, and optimization methods affect generalization in the interpolation regime.
Plain English Explanation
Machine learning models are often trained to "interpolate" - that is, to perfectly fit the training data they are given. However, the bigger question is how well these models will generalize, or perform on new data they haven't seen before. This paper explores this idea of generalization in the interpolation regime using a mathematical tool called the "rate function."
The rate function provides a way to quantify how quickly a model's performance degrades as you move away from the training data. The authors use this to investigate how factors like model complexity, the number of dimensions in the data, and the optimization method used during training impact a model's ability to generalize.
For example, they find that more complex models tend to generalize worse in the interpolation regime. This makes sense - a simpler model that just barely fits the training data may be more robust to new inputs. The dimensionality of the data is also key, with higher-dimensional datasets posing greater challenges for generalization.
By understanding these relationships between model properties, data characteristics, and generalization, the researchers hope to provide insights that can guide the development of machine learning systems that reliably perform well on new, unseen data. This is a crucial goal, as the true test of a model's usefulness is how it fares in the real world, not just on the data it was trained on.
Technical Explanation
The paper investigates generalization in the "interpolation regime" - the setting where a machine learning model can perfectly fit the training data it is given. The authors leverage the concept of the "rate function" to quantify and analyze this generalization behavior.
The rate function describes how quickly a model's performance degrades as you move away from the training data distribution. By analyzing the properties of the rate function, the researchers are able to gain insights into the factors that influence a model's ability to generalize in the interpolation regime.
Through a series of experiments, the authors explore how model complexity, data dimensionality, and optimization methods impact generalization. For instance, they find that more complex models tend to have worse generalization, as do datasets with higher dimensionality. The choice of optimization technique also plays a role, with some methods leading to better out-of-sample performance than others.
These findings contribute to a growing body of work on understanding generalization in machine learning, obtaining data-driven performance guarantees, and leveraging the interpolation regime for error bounds. The insights from this paper also relate to broader efforts to develop an information-theoretic framework for out-of-distribution generalization and understand the approximation and interpolation capabilities of deep neural networks.
Critical Analysis
The paper provides a valuable contribution to the ongoing research on understanding generalization in machine learning, particularly in the interpolation regime. The authors' use of the rate function as a tool for analysis is insightful and offers a novel perspective on this challenge.
One potential limitation of the work is the focus on relatively simple, synthetic datasets. While this allows the authors to isolate and study specific factors, it raises questions about how well the findings would translate to more complex, real-world problems. Further research exploring generalization in the interpolation regime on more realistic datasets would be a helpful next step.
Additionally, the paper does not delve deeply into the underlying reasons why model complexity, data dimensionality, and optimization methods impact generalization in the ways observed. A more thorough examination of the theoretical foundations and mechanisms behind these relationships could strengthen the insights and provide a firmer basis for practical applications.
Overall, this paper represents a valuable contribution to the field and serves as a springboard for future work exploring the nuances of generalization in machine learning. By continuing to develop a deeper understanding of these issues, researchers can work towards building more robust and reliable AI systems.
Conclusion
This paper investigates generalization in the "interpolation regime" of machine learning, where models are able to perfectly fit the training data. The authors use the concept of the "rate function" to quantify and analyze this generalization behavior, exploring how factors like model complexity, data dimensionality, and optimization methods impact a model's ability to perform well on new, unseen data.
The key findings include the observation that more complex models tend to generalize worse in the interpolation regime, and that higher-dimensional datasets pose greater challenges for generalization. These insights contribute to a growing body of research on understanding the factors that influence machine learning generalization, with important implications for the development of reliable and robust AI systems.
By continuing to deepen our understanding of these issues, the research community can work towards building machine learning models that not only excel on the data they are trained on, but also consistently perform well in real-world, out-of-sample scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
Uniform Generalization Bounds on Data-Dependent Hypothesis Sets via PAC-Bayesian Theory on Random Sets
Benjamin Dupuis, Paul Viallard, George Deligiannidis, Umut Simsekli
0
0
We propose data-dependent uniform generalization bounds by approaching the problem from a PAC-Bayesian perspective. We first apply the PAC-Bayesian framework on `random sets' in a rigorous way, where the training algorithm is assumed to output a data-dependent hypothesis set after observing the training data. This approach allows us to prove data-dependent bounds, which can be applicable in numerous contexts. To highlight the power of our approach, we consider two main applications. First, we propose a PAC-Bayesian formulation of the recently developed fractal-dimension-based generalization bounds. The derived results are shown to be tighter and they unify the existing results around one simple proof technique. Second, we prove uniform bounds over the trajectories of continuous Langevin dynamics and stochastic gradient Langevin dynamics. These results provide novel information about the generalization properties of noisy algorithms.
4/29/2024

A finite-sample generalization bound for stable LPV systems
Daniel Racz, Martin Gonzalez, Mihaly Petreczky, Andras Benczur, Balint Daroczy
0
0
One of the main theoretical challenges in learning dynamical systems from data is providing upper bounds on the generalization error, that is, the difference between the expected prediction error and the empirical prediction error measured on some finite sample. In machine learning, a popular class of such bounds are the so-called Probably Approximately Correct (PAC) bounds. In this paper, we derive a PAC bound for stable continuous-time linear parameter-varying (LPV) systems. Our bound depends on the H2 norm of the chosen class of the LPV systems, but does not depend on the time interval for which the signals are considered.
5/22/2024
🔄
More PAC-Bayes bounds: From bounded losses, to losses with general tail behaviors, to anytime validity
Borja Rodr'iguez-G'alvez, Ragnar Thobaben, Mikael Skoglund
0
0
In this paper, we present new high-probability PAC-Bayes bounds for different types of losses. Firstly, for losses with a bounded range, we recover a strengthened version of Catoni's bound that holds uniformly for all parameter values. This leads to new fast-rate and mixed-rate bounds that are interpretable and tighter than previous bounds in the literature. In particular, the fast-rate bound is equivalent to the Seeger--Langford bound. Secondly, for losses with more general tail behaviors, we introduce two new parameter-free bounds: a PAC-Bayes Chernoff analogue when the loss' cumulative generating function is bounded, and a bound when the loss' second moment is bounded. These two bounds are obtained using a new technique based on a discretization of the space of possible events for the ``in probability'' parameter optimization problem. This technique is both simpler and more general than previous approaches optimizing over a grid on the parameters' space. Finally, using a simple technique that is applicable to any existing bound, we extend all previous results to anytime-valid bounds.
6/5/2024

Generalization error of min-norm interpolators in transfer learning
Yanke Song, Sohom Bhattacharya, Pragya Sur
0
0
This paper establishes the generalization error of pooled min-$ell_2$-norm interpolation in transfer learning where data from diverse distributions are available. Min-norm interpolators emerge naturally as implicit regularized limits of modern machine learning algorithms. Previous work characterized their out-of-distribution risk when samples from the test distribution are unavailable during training. However, in many applications, a limited amount of test data may be available during training, yet properties of min-norm interpolation in this setting are not well-understood. We address this gap by characterizing the bias and variance of pooled min-$ell_2$-norm interpolation under covariate and model shifts. The pooled interpolator captures both early fusion and a form of intermediate fusion. Our results have several implications: under model shift, for low signal-to-noise ratio (SNR), adding data always hurts. For higher SNR, transfer learning helps as long as the shift-to-signal (SSR) ratio lies below a threshold that we characterize explicitly. By consistently estimating these ratios, we provide a data-driven method to determine: (i) when the pooled interpolator outperforms the target-based interpolator, and (ii) the optimal number of target samples that minimizes the generalization error. Under covariate shift, if the source sample size is small relative to the dimension, heterogeneity between between domains improves the risk, and vice versa. We establish a novel anisotropic local law to achieve these characterizations, which may be of independent interest in random matrix theory. We supplement our theoretical characterizations with comprehensive simulations that demonstrate the finite-sample efficacy of our results.
6/21/2024