Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models
2402.15938
0
0
Abstract
Recent statements about the impressive capabilities of large language models (LLMs) are usually supported by evaluating on open-access benchmarks. Considering the vast size and wide-ranging sources of LLMs' training data, it could explicitly or implicitly include test data, leading to LLMs being more susceptible to data contamination. However, due to the opacity of training data, the black-box access of models, and the rapid growth of synthetic training data, detecting and mitigating data contamination for LLMs faces significant challenges. In this paper, we propose CDD, which stands for Contamination Detection via output Distribution for LLMs. CDD necessitates only the sampled texts to detect data contamination, by identifying the peakedness of LLM's output distribution. To mitigate the impact of data contamination in evaluation, we also present TED: Trustworthy Evaluation via output Distribution, based on the correction of LLM's output distribution. To facilitate this study, we introduce two benchmarks, i.e., DetCon and ComiEval, for data contamination detection and contamination mitigation evaluation tasks. Extensive experimental results show that CDD achieves the average relative improvements of 21.8%-30.2% over other contamination detection approaches in terms of Accuracy, F1 Score, and AUC metrics, and can effectively detect implicit contamination. TED substantially mitigates performance improvements up to 66.9% attributed to data contamination across various contamination setups. In real-world applications, we reveal that ChatGPT exhibits a high potential to suffer from data contamination on HumanEval benchmark.
Create account to get full access
Overview
- This paper explores the impact of data contamination on the evaluation of large language models (LLMs), and proposes methods to ensure trustworthy and unbiased evaluation.
- The authors identify issues with current benchmarking practices, including the potential for models to memorize and reproduce training data rather than truly generalizing.
- They introduce a framework for detecting and mitigating data contamination, and demonstrate its effectiveness through experiments on popular LLM benchmarks.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. These models are trained on vast amounts of online data, which can sometimes lead to issues. One key problem is "data contamination" - where the model memorizes specific examples from the training data rather than learning general patterns.
This can lead to an inaccurate evaluation of the model's true capabilities. For example, if a model is tested on a sentence that was identical to something in its training data, it may perform well not because it has truly learned the underlying concepts, but simply because it has memorized that specific example.
The researchers in this paper propose a framework to detect and address this issue. They introduce methods to identify when a model is relying on memorization rather than generalization, and ways to design more robust benchmarks that don't allow this kind of data contamination.
By implementing these techniques, the researchers were able to get a more accurate and trustworthy assessment of how well these large language models can truly understand and generate natural language, beyond just recalling specific training examples.
This is an important step towards building AI systems that reliably generalize their knowledge, rather than simply memorizing data. It helps ensure the models are evaluated fairly and can be deployed safely in real-world applications.
Technical Explanation
The paper begins by highlighting the growing concern around data contamination in LLM evaluation. The authors explain how current benchmarking practices may incentivize models to simply memorize training data rather than learning generalizable skills.
To address this, the researchers introduce a framework called COHERENCE (Contamination-based Honest Evaluation of Large laNguage modEls). COHERENCE combines several techniques to detect and mitigate data contamination:
- Nearest Neighbor Retrieval: This method identifies instances in the test set that are too similar to the model's training data, indicating potential memorization.
- Contrastive Evaluation: The authors propose evaluating models not just on their ability to generate specific outputs, but also on their ability to discriminate between relevant and irrelevant responses.
- Out-of-Distribution Generalization: The framework also tests how well models can apply their knowledge to data that is distinctly different from their training distribution.
The paper then presents experiments applying COHERENCE to popular LLM benchmarks like GLUE and SuperGLUE. The results show that standard evaluation protocols can significantly overestimate model performance due to data contamination, while the COHERENCE framework provides a more robust and reliable assessment.
Critical Analysis
The paper makes a compelling case for the importance of addressing data contamination in LLM evaluation. The authors provide a thorough analysis of the issues with current benchmarking practices and a well-designed framework to mitigate these problems.
One potential limitation is that the COHERENCE approach relies on the availability of high-quality training and test data that is free of contamination. In practice, it may be challenging to obtain such datasets, especially for emerging AI applications.
Additionally, the paper focuses primarily on evaluating the models' ability to generate text. While this is a crucial capability, it may be worth exploring how data contamination could also impact other important tasks, such as question answering or commonsense reasoning.
Overall, this research represents an important step towards more trustworthy and unbiased evaluation of large language models. By highlighting the risks of data contamination and proposing solutions, the authors contribute to the ongoing effort to develop AI systems that truly generalize their knowledge rather than simply memorizing training data.
Conclusion
This paper presents a significant advancement in the field of LLM evaluation. By identifying the problem of data contamination and developing the COHERENCE framework to address it, the researchers have made a valuable contribution to ensuring the trustworthiness and reliability of these powerful AI systems.
The techniques introduced in this work could have far-reaching implications, helping to guide the development of LLMs that can consistently generalize their knowledge and be deployed safely in real-world applications. As the field of AI continues to evolve, this research serves as a important reminder of the need for rigorous and unbiased evaluation methods to support the responsible advancement of the technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Data Contamination Can Cross Language Barriers
Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, Jingbo Shang
0
0
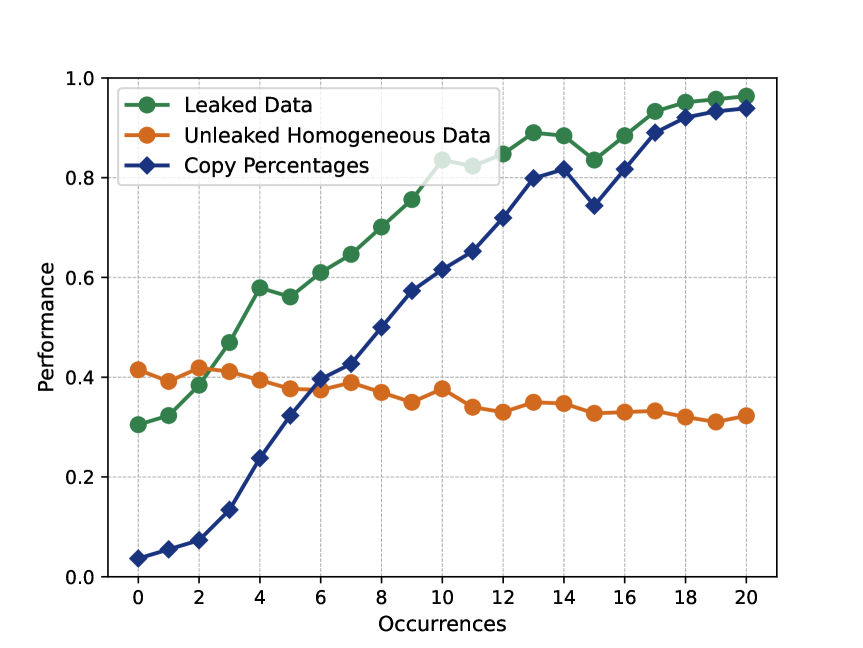
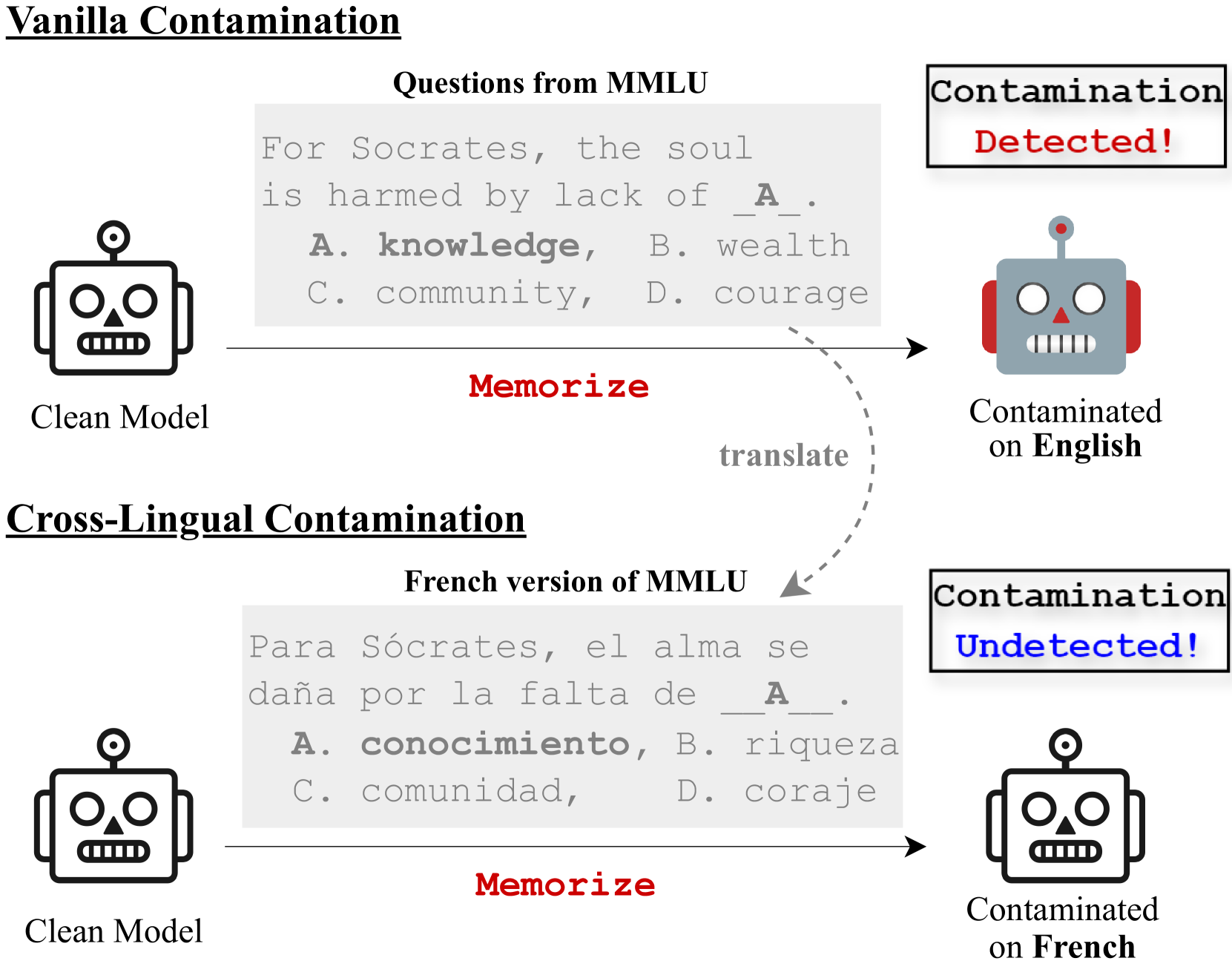
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from url{https://github.com/ShangDataLab/Deep-Contam}.
6/21/2024
Benchmark Data Contamination of Large Language Models: A Survey
Cheng Xu, Shuhao Guan, Derek Greene, M-Tahar Kechadi
0
0
The rapid development of Large Language Models (LLMs) like GPT-4, Claude-3, and Gemini has transformed the field of natural language processing. However, it has also resulted in a significant issue known as Benchmark Data Contamination (BDC). This occurs when language models inadvertently incorporate evaluation benchmark information from their training data, leading to inaccurate or unreliable performance during the evaluation phase of the process. This paper reviews the complex challenge of BDC in LLM evaluation and explores alternative assessment methods to mitigate the risks associated with traditional benchmarks. The paper also examines challenges and future directions in mitigating BDC risks, highlighting the complexity of the issue and the need for innovative solutions to ensure the reliability of LLM evaluation in real-world applications.
6/7/2024

DICE: Detecting In-distribution Contamination in LLM's Fine-tuning Phase for Math Reasoning
Shangqing Tu, Kejian Zhu, Yushi Bai, Zijun Yao, Lei Hou, Juanzi Li
0
0
The advancement of large language models (LLMs) relies on evaluation using public benchmarks, but data contamination can lead to overestimated performance. Previous researches focus on detecting contamination by determining whether the model has seen the exact same data during training. In this work, we argue that even training on data similar to benchmark data inflates performance on in-distribution tasks without improving overall capacity, which we called In-distribution contamination. To effectively detect in-distribution contamination, we propose DICE, a novel method that leverages the internal states of LLMs to locate-then-detect the contamination. DICE first identifies the most sensitive layer to contamination, then trains a classifier based on the internal states of that layer. Experiments reveal DICE's high accuracy in detecting in-distribution contamination across various LLMs and math reasoning datasets. We also show the generalization capability of the trained DICE detector, which is able to detect contamination across multiple benchmarks with similar distributions. Additionally, we find that the DICE detection scores are positively correlated with the performance of ten LLMs fine-tuned by either us or other organizations on four math reasoning datasets (with $R^2$ values between 0.6 and 0.75). This indicates that the in-distribution contamination problem potentially lead to an overestimation of the true capabilities of many existing models. The code and data are available at https://github.com/THU-KEG/DICE.
6/7/2024
📊
Investigating Data Contamination in Modern Benchmarks for Large Language Models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, Arman Cohan
0
0
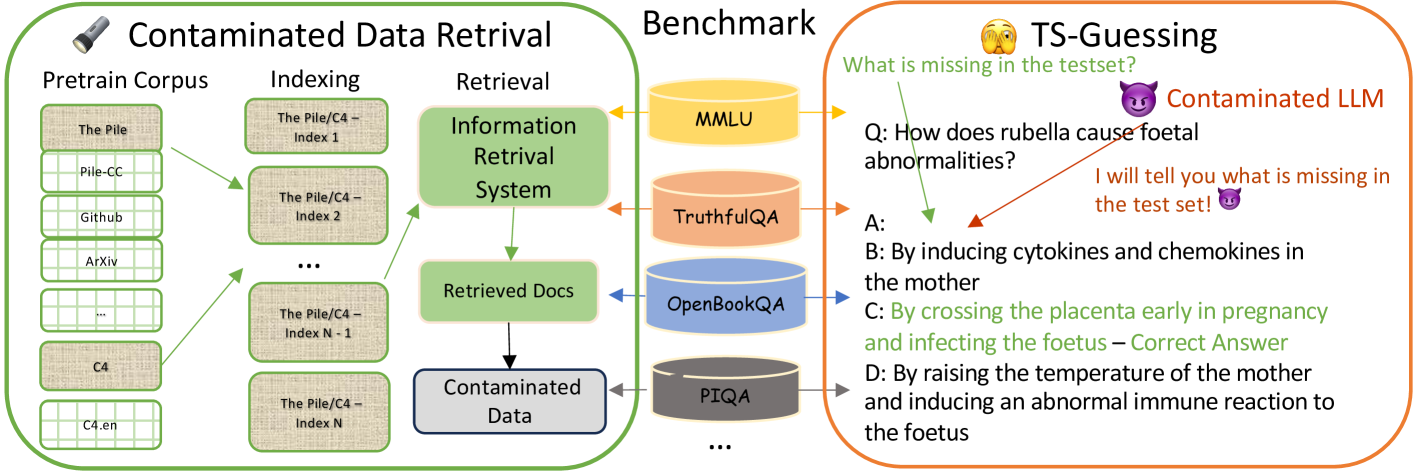
Recent observations have underscored a disparity between the inflated benchmark scores and the actual performance of LLMs, raising concerns about potential contamination of evaluation benchmarks. This issue is especially critical for closed-source models and certain open-source models where training data transparency is lacking. In this paper we study data contamination by proposing two methods tailored for both open-source and proprietary LLMs. We first introduce a retrieval-based system to explore potential overlaps between evaluation benchmarks and pretraining corpora. We further present a novel investigation protocol named textbf{T}estset textbf{S}lot Guessing (textit{TS-Guessing}), applicable to both open and proprietary models. This approach entails masking a wrong answer in a multiple-choice question and prompting the model to fill in the gap. Additionally, it involves obscuring an unlikely word in an evaluation example and asking the model to produce it. We find that certain commercial LLMs could surprisingly guess the missing option in various test sets. Specifically, in the TruthfulQA benchmark, we find that LLMs exhibit notable performance improvement when provided with additional metadata in the benchmark. Further, in the MMLU benchmark, ChatGPT and GPT-4 demonstrated an exact match rate of 52% and 57%, respectively, in guessing the missing options in benchmark test data. We hope these results underscore the need for more robust evaluation methodologies and benchmarks in the field.
4/5/2024