Investigating Data Contamination in Modern Benchmarks for Large Language Models
2311.09783
0
0
📊
Abstract
Recent observations have underscored a disparity between the inflated benchmark scores and the actual performance of LLMs, raising concerns about potential contamination of evaluation benchmarks. This issue is especially critical for closed-source models and certain open-source models where training data transparency is lacking. In this paper we study data contamination by proposing two methods tailored for both open-source and proprietary LLMs. We first introduce a retrieval-based system to explore potential overlaps between evaluation benchmarks and pretraining corpora. We further present a novel investigation protocol named textbf{T}estset textbf{S}lot Guessing (textit{TS-Guessing}), applicable to both open and proprietary models. This approach entails masking a wrong answer in a multiple-choice question and prompting the model to fill in the gap. Additionally, it involves obscuring an unlikely word in an evaluation example and asking the model to produce it. We find that certain commercial LLMs could surprisingly guess the missing option in various test sets. Specifically, in the TruthfulQA benchmark, we find that LLMs exhibit notable performance improvement when provided with additional metadata in the benchmark. Further, in the MMLU benchmark, ChatGPT and GPT-4 demonstrated an exact match rate of 52% and 57%, respectively, in guessing the missing options in benchmark test data. We hope these results underscore the need for more robust evaluation methodologies and benchmarks in the field.
Create account to get full access
Overview
- The paper discusses a concerning disparity between the high benchmark scores of large language models (LLMs) and their actual real-world performance.
- This issue is particularly problematic for closed-source models and certain open-source models where the training data is not transparent.
- The authors propose two methods to investigate data contamination in both open-source and proprietary LLMs.
Plain English Explanation
The paper examines a problem with how we measure the capabilities of large language models. Benchmark tests often show these models performing extremely well, but in reality, they don't always live up to those inflated scores.
This is especially concerning for closed-source models and some open-source models where we don't know exactly what data was used to train them. The authors suspect the training data may have "contaminated" the evaluation benchmarks, making the models appear more capable than they really are.
To investigate this issue, the researchers propose two new methods. The first is a retrieval-based system that looks for overlaps between the benchmark data and the original training data. The second approach, called "Testset Slot Guessing" (TS-Guessing), involves masking parts of the benchmark questions and seeing if the models can correctly fill in the missing information.
When they applied these techniques, the authors found that some commercial LLMs were surprisingly good at guessing the right answers, even when key details were obscured. This suggests the models may have simply memorized the benchmark data rather than truly understanding the concepts.
Technical Explanation
The paper begins by highlighting the discrepancy between the high benchmark scores of large language models (LLMs) and their actual real-world performance. This issue is particularly acute for closed-source models and certain open-source models where the training data transparency is lacking.
To address this problem, the authors propose two complementary methods. First, they introduce a retrieval-based system to explore potential overlaps between evaluation benchmarks and the LLMs' pretraining corpora. This approach aims to uncover instances where the models may have simply memorized the benchmark data rather than developing genuine understanding.
Additionally, the researchers present a novel investigation protocol called "Testset Slot Guessing" (TS-Guessing). This technique involves masking a wrong answer in a multiple-choice question and prompting the model to fill in the gap. It also entails obscuring an unlikely word in an evaluation example and asking the model to produce it. By observing how well the models perform on these modified tasks, the authors hope to gain insights into the extent of data contamination.
The results of their experiments are quite striking. The authors find that certain commercial LLMs are surprisingly adept at guessing the missing options in various test sets. For example, in the TruthfulQA benchmark, the models exhibit notable performance improvements when provided with additional metadata. Similarly, in the MMLU benchmark, ChatGPT and GPT-4 demonstrated an exact match rate of 52% and 57%, respectively, in guessing the missing options in the test data.
Critical Analysis
While the authors' findings are certainly thought-provoking, it's important to consider some potential limitations and areas for further research. The paper acknowledges that the TS-Guessing technique may not be applicable to all types of benchmarks and that additional validation is required to establish its reliability.
Furthermore, the paper does not delve into the specific mechanisms by which data contamination may occur, nor does it provide a comprehensive taxonomy of the various ways in which benchmark scores can be inflated. Further research may be needed to better understand the root causes of this phenomenon and develop more robust evaluation methodologies.
Additionally, the paper's focus on closed-source and certain open-source models raises questions about the generalizability of the findings. It would be valuable to investigate the extent of data contamination across a broader range of LLM architectures and training approaches, including those with more transparent data sources.
Conclusion
The paper highlights a concerning issue in the field of large language models: the disparity between inflated benchmark scores and actual real-world performance. The authors propose two innovative methods to investigate data contamination, which reveal startling insights about the ability of certain commercial LLMs to guess missing information in benchmark tests.
These findings underscore the need for more robust and reliable evaluation methodologies, as well as greater transparency in the training data and processes used to develop LLMs. By addressing these challenges, the research community can work towards building trustworthy and accountable language models that truly meet the needs of users and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
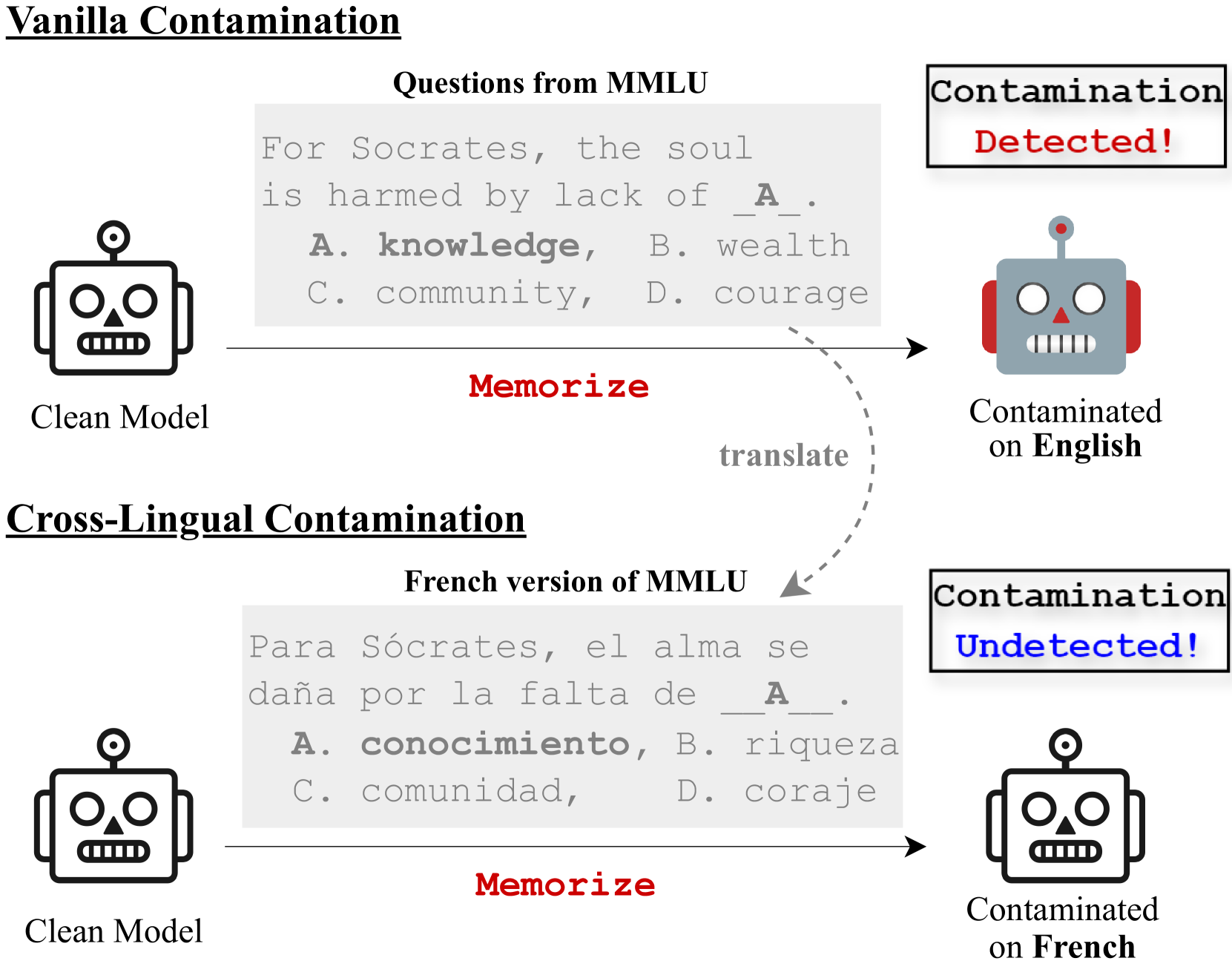
Data Contamination Can Cross Language Barriers
Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, Jingbo Shang
0
0
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from url{https://github.com/ShangDataLab/Deep-Contam}.
6/21/2024
Benchmark Data Contamination of Large Language Models: A Survey
Cheng Xu, Shuhao Guan, Derek Greene, M-Tahar Kechadi
0
0
The rapid development of Large Language Models (LLMs) like GPT-4, Claude-3, and Gemini has transformed the field of natural language processing. However, it has also resulted in a significant issue known as Benchmark Data Contamination (BDC). This occurs when language models inadvertently incorporate evaluation benchmark information from their training data, leading to inaccurate or unreliable performance during the evaluation phase of the process. This paper reviews the complex challenge of BDC in LLM evaluation and explores alternative assessment methods to mitigate the risks associated with traditional benchmarks. The paper also examines challenges and future directions in mitigating BDC risks, highlighting the complexity of the issue and the need for innovative solutions to ensure the reliability of LLM evaluation in real-world applications.
6/7/2024
💬
Benchmarking Benchmark Leakage in Large Language Models
Ruijie Xu, Zengzhi Wang, Run-Ze Fan, Pengfei Liu
0
0
Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion of supervised data in contemporary Large Language Models (LLMs). This issue skews benchmark effectiveness and fosters potentially unfair comparisons, impeding the field's healthy development. To address this, we introduce a detection pipeline utilizing Perplexity and N-gram accuracy, two simple and scalable metrics that gauge a model's prediction precision on benchmark, to identify potential data leakages. By analyzing 31 LLMs under the context of mathematical reasoning, we reveal substantial instances of training even test set misuse, resulting in potentially unfair comparisons. These findings prompt us to offer several recommendations regarding model documentation, benchmark setup, and future evaluations. Notably, we propose the Benchmark Transparency Card to encourage clear documentation of benchmark utilization, promoting transparency and healthy developments of LLMs. we have made our leaderboard, pipeline implementation, and model predictions publicly available, fostering future research.
4/30/2024
Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models
Yihong Dong, Xue Jiang, Huanyu Liu, Zhi Jin, Bin Gu, Mengfei Yang, Ge Li
0
0
Recent statements about the impressive capabilities of large language models (LLMs) are usually supported by evaluating on open-access benchmarks. Considering the vast size and wide-ranging sources of LLMs' training data, it could explicitly or implicitly include test data, leading to LLMs being more susceptible to data contamination. However, due to the opacity of training data, the black-box access of models, and the rapid growth of synthetic training data, detecting and mitigating data contamination for LLMs faces significant challenges. In this paper, we propose CDD, which stands for Contamination Detection via output Distribution for LLMs. CDD necessitates only the sampled texts to detect data contamination, by identifying the peakedness of LLM's output distribution. To mitigate the impact of data contamination in evaluation, we also present TED: Trustworthy Evaluation via output Distribution, based on the correction of LLM's output distribution. To facilitate this study, we introduce two benchmarks, i.e., DetCon and ComiEval, for data contamination detection and contamination mitigation evaluation tasks. Extensive experimental results show that CDD achieves the average relative improvements of 21.8%-30.2% over other contamination detection approaches in terms of Accuracy, F1 Score, and AUC metrics, and can effectively detect implicit contamination. TED substantially mitigates performance improvements up to 66.9% attributed to data contamination across various contamination setups. In real-world applications, we reveal that ChatGPT exhibits a high potential to suffer from data contamination on HumanEval benchmark.
6/3/2024