Generalized Categories Discovery for Long-tailed Recognition

0
Sign in to get full access
Overview
- The paper addresses the problem of long-tailed recognition, where there are many rare categories with few training examples
- It proposes a method for generalized categories discovery, which can find new categories beyond the original training set
- The key ideas include class prior estimation, contrastive mean shift, and leveraging large language models
Plain English Explanation
The researchers are working on a problem in machine learning called "long-tailed recognition." This refers to datasets where there are many rare categories with only a few examples to train on, and a small number of common categories with lots of training data.
Their method tries to address this by discovering new categories beyond the original set used for training. The key steps are:
- Estimating the class priors - figuring out how common or rare each category is in the overall dataset.
- Using contrastive mean shift - a technique to find distinct clusters of data points that could represent new categories.
- Leveraging large language models - using powerful AI models trained on vast amounts of text data to help recognize and classify the new categories.
The goal is to build machine learning systems that can discover and recognize a much broader set of categories, going beyond the limitations of the original training data.
Technical Explanation
The paper proposes a method for generalized categories discovery to address the challenge of long-tailed recognition. This involves three main components:
-
Class Prior Estimation: The researchers develop a technique to estimate the prior probability (i.e. relative frequency) of each category in the dataset. This helps the system understand which categories are rare vs common.
-
Contrastive Mean Shift: This is an unsupervised clustering algorithm that can identify distinct groups of data points, which may correspond to new categories beyond the original training set.
-
Leveraging Large Language Models: The paper explores using large pre-trained language models, like BERT, to help recognize and classify the new category prototypes discovered through contrastive mean shift. This allows the model to leverage rich semantic knowledge.
The key insight is that by combining these three components - class priors, contrastive clustering, and language model integration - the system can go beyond the limitations of the original training data and discover a more diverse and comprehensive set of categories.
Critical Analysis
The paper offers a promising approach to the important problem of long-tailed recognition. However, a few potential limitations or areas for further work are worth noting:
- The class prior estimation and contrastive mean shift techniques, while novel, may not always perfectly capture the true underlying category structure, especially for highly complex real-world datasets.
- Relying on large language models introduces additional complexity and computational requirements. It's unclear how this approach would scale to extremely large-scale datasets and categories.
- The paper does not extensively explore the robustness of the method to noisy or adversarial data, which is an important practical consideration for real-world deployment.
Further research could examine these issues and work towards making the generalized categories discovery process more reliable, efficient, and secure.
Conclusion
This paper presents an innovative approach to addressing the long-tailed recognition problem in machine learning. By combining class prior estimation, contrastive clustering, and language model integration, the method can discover new categories beyond the original training set.
While there are some potential limitations to address, the core ideas offer a promising direction for building more comprehensive and flexible visual recognition systems. As machine learning continues to be applied to increasingly complex real-world domains, techniques like this will be crucial for expanding the capabilities of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generalized Categories Discovery for Long-tailed Recognition
Ziyun Li, Christoph Meinel, Haojin Yang
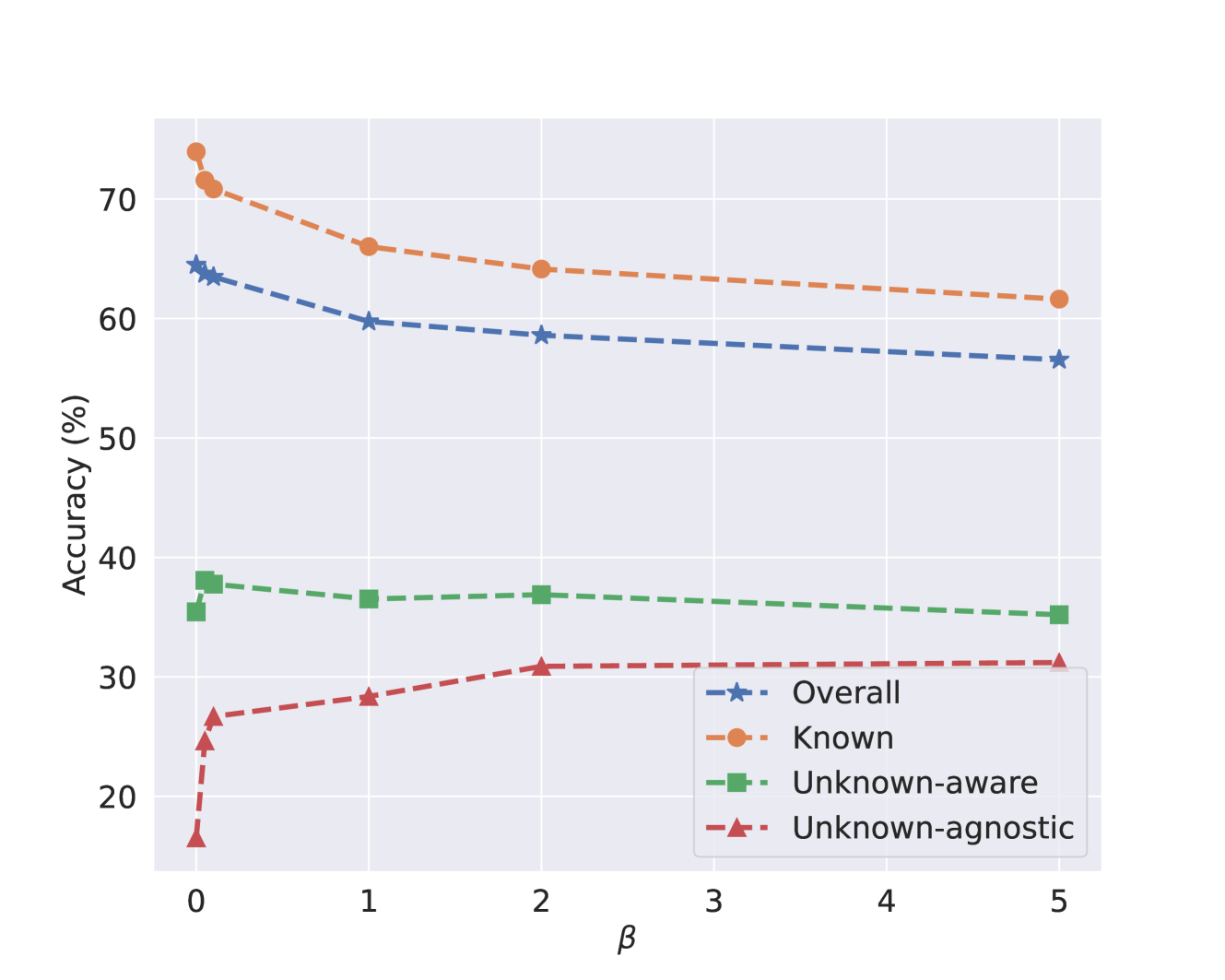
Generalized Class Discovery (GCD) plays a pivotal role in discerning both known and unknown categories from unlabeled datasets by harnessing the insights derived from a labeled set comprising recognized classes. A significant limitation in prevailing GCD methods is their presumption of an equitably distributed category occurrence in unlabeled data. Contrary to this assumption, visual classes in natural environments typically exhibit a long-tailed distribution, with known or prevalent categories surfacing more frequently than their rarer counterparts. Our research endeavors to bridge this disconnect by focusing on the long-tailed Generalized Category Discovery (Long-tailed GCD) paradigm, which echoes the innate imbalances of real-world unlabeled datasets. In response to the unique challenges posed by Long-tailed GCD, we present a robust methodology anchored in two strategic regularizations: (i) a reweighting mechanism that bolsters the prominence of less-represented, tail-end categories, and (ii) a class prior constraint that aligns with the anticipated class distribution. Comprehensive experiments reveal that our proposed method surpasses previous state-of-the-art GCD methods by achieving an improvement of approximately 6 - 9% on ImageNet100 and competitive performance on CIFAR100.
Read more8/27/2024
0
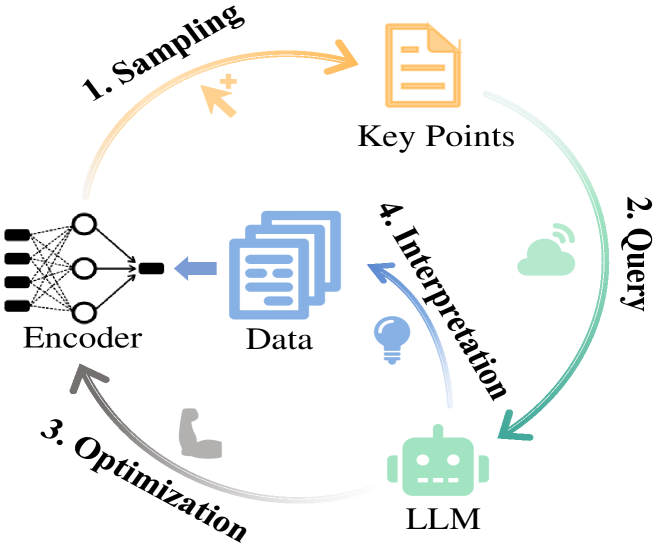
Generalized Category Discovery with Large Language Models in the Loop
Wenbin An, Wenkai Shi, Feng Tian, Haonan Lin, QianYing Wang, Yaqiang Wu, Mingxiang Cai, Luyan Wang, Yan Chen, Haiping Zhu, Ping Chen
Generalized Category Discovery (GCD) is a crucial task that aims to recognize both known and novel categories from a set of unlabeled data by utilizing a few labeled data with only known categories. Due to the lack of supervision and category information, current methods usually perform poorly on novel categories and struggle to reveal semantic meanings of the discovered clusters, which limits their applications in the real world. To mitigate the above issues, we propose Loop, an end-to-end active-learning framework that introduces Large Language Models (LLMs) into the training loop, which can boost model performance and generate category names without relying on any human efforts. Specifically, we first propose Local Inconsistent Sampling (LIS) to select samples that have a higher probability of falling to wrong clusters, based on neighborhood prediction consistency and entropy of cluster assignment probabilities. Then we propose a Scalable Query strategy to allow LLMs to choose true neighbors of the selected samples from multiple candidate samples. Based on the feedback from LLMs, we perform Refined Neighborhood Contrastive Learning (RNCL) to pull samples and their neighbors closer to learn clustering-friendly representations. Finally, we select representative samples from clusters corresponding to novel categories to allow LLMs to generate category names for them. Extensive experiments on three benchmark datasets show that Loop outperforms SOTA models by a large margin and generates accurate category names for the discovered clusters. Code and data are available at https://github.com/Lackel/LOOP.
Read more5/28/2024
0
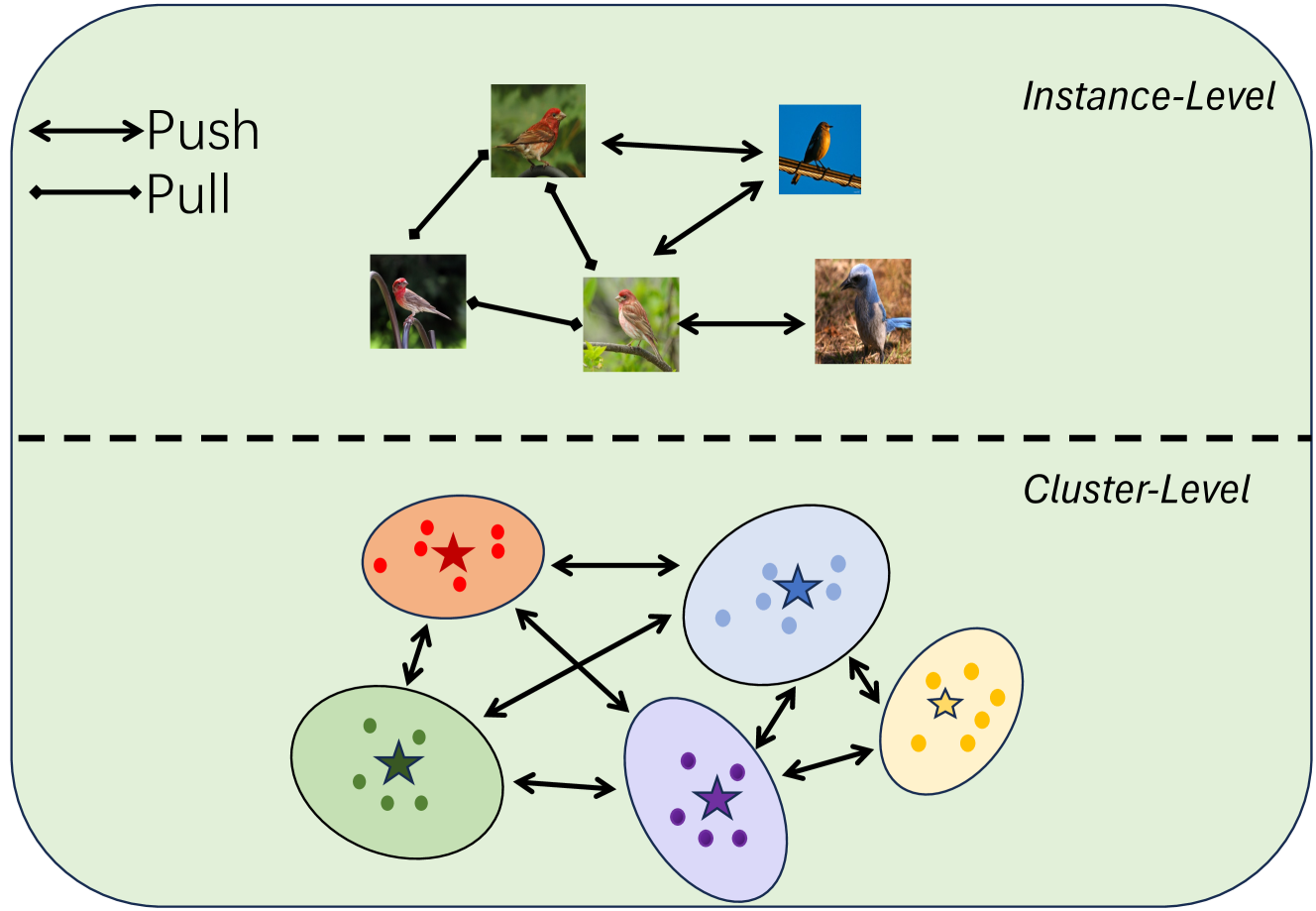
Contextuality Helps Representation Learning for Generalized Category Discovery
Tingzhang Luo, Mingxuan Du, Jiatao Shi, Xinxiang Chen, Bingchen Zhao, Shaoguang Huang
This paper introduces a novel approach to Generalized Category Discovery (GCD) by leveraging the concept of contextuality to enhance the identification and classification of categories in unlabeled datasets. Drawing inspiration from human cognition's ability to recognize objects within their context, we propose a dual-context based method. Our model integrates two levels of contextuality: instance-level, where nearest-neighbor contexts are utilized for contrastive learning, and cluster-level, employing prototypical contrastive learning based on category prototypes. The integration of the contextual information effectively improves the feature learning and thereby the classification accuracy of all categories, which better deals with the real-world datasets. Different from the traditional semi-supervised and novel category discovery techniques, our model focuses on a more realistic and challenging scenario where both known and novel categories are present in the unlabeled data. Extensive experimental results on several benchmark data sets demonstrate that the proposed model outperforms the state-of-the-art. Code is available at: https://github.com/Clarence-CV/Contexuality-GCD
Read more7/30/2024

0
LTGC: Long-tail Recognition via Leveraging LLMs-driven Generated Content
Qihao Zhao, Yalun Dai, Hao Li, Wei Hu, Fan Zhang, Jun Liu
Long-tail recognition is challenging because it requires the model to learn good representations from tail categories and address imbalances across all categories. In this paper, we propose a novel generative and fine-tuning framework, LTGC, to handle long-tail recognition via leveraging generated content. Firstly, inspired by the rich implicit knowledge in large-scale models (e.g., large language models, LLMs), LTGC leverages the power of these models to parse and reason over the original tail data to produce diverse tail-class content. We then propose several novel designs for LTGC to ensure the quality of the generated data and to efficiently fine-tune the model using both the generated and original data. The visualization demonstrates the effectiveness of the generation module in LTGC, which produces accurate and diverse tail data. Additionally, the experimental results demonstrate that our LTGC outperforms existing state-of-the-art methods on popular long-tailed benchmarks.
Read more5/28/2024