Contextuality Helps Representation Learning for Generalized Category Discovery

0
Sign in to get full access
Overview
- Presents a novel approach called Contextual Representation Learning (CRL) for generalized category discovery
- Leverages contextual information to improve representation learning and enable discovery of new categories beyond the initial training set
- Conducts extensive experiments on several datasets to demonstrate the effectiveness of CRL
Plain English Explanation
The paper introduces a new method called Contextual Representation Learning (CRL) that aims to improve the ability of machine learning models to discover new categories of objects beyond the initial set used for training. Typically, machine learning models are trained on a fixed set of categories and struggle to recognize objects that don't belong to those known categories.
CRL addresses this limitation by incorporating contextual information during the representation learning process. The key idea is that the surrounding context of an object can provide valuable cues about its category, even if the object itself is novel or unfamiliar. By explicitly modeling these contextual relationships, the CRL method is able to learn more robust and generalizable representations that enable the discovery of new object categories.
The paper demonstrates the effectiveness of CRL through experiments on several benchmark datasets. The results show that CRL outperforms previous approaches in terms of discovering new categories, while also maintaining strong performance on the original training categories. This suggests that incorporating contextual information can be a powerful strategy for enabling machines to better understand and adapt to the rich diversity of the real world.
Technical Explanation
The paper introduces a novel representation learning method called Contextual Representation Learning (CRL) that leverages contextual information to improve generalized category discovery. The key innovation is the incorporation of contextual cues during the representation learning process, which allows the model to learn more robust and generalizable representations.
At a high level, the CRL approach works as follows:
- Contextual feature extraction: The model extracts features not only from the target object, but also from its surrounding context. This captures information about the object's relationship to its environment.
- Contrastive learning: The model is trained using a contrastive objective that encourages the learned representations to be similar for objects from the same category, and dissimilar for objects from different categories. Crucially, this process considers both the target object and its context.
- Category discovery: During inference, the learned representations are used to cluster the data into categories, including both the original training categories and any new categories that emerge.
The paper evaluates CRL on several benchmark datasets for generalized category discovery, including COCO, ImageNet, and iNaturalist. The results demonstrate that CRL outperforms previous state-of-the-art methods in terms of discovering new categories while also maintaining strong performance on the original training categories.
The key insight is that by modeling the contextual relationships between objects, the CRL method is able to learn more versatile and generalizable representations that are better equipped to handle novel categories. This represents an important step towards building machine learning systems that can truly adapt to the open-ended and diverse nature of the real world.
Critical Analysis
The paper presents a well-designed and thorough study of the CRL approach, with extensive experiments and comparisons to state-of-the-art methods. The key strength of the work is the explicit incorporation of contextual information, which appears to be a valuable signal for enabling generalized category discovery.
However, the paper also acknowledges several limitations and areas for future work:
- The experiments are still conducted on relatively constrained datasets, and further evaluation on more diverse, real-world data would be valuable.
- The model architecture and training procedure could potentially be further optimized to improve performance and efficiency.
- The underlying mechanisms by which contextual information aids generalization are not fully explained, and a deeper theoretical understanding could lead to additional insights.
Furthermore, one could question whether the emphasis on discovering new categories is the most appropriate or important goal for real-world applications. In many cases, it may be more valuable for a system to accurately detect and classify known categories, rather than constantly seeking to identify new ones.
Overall, the paper represents an important step forward in addressing the challenge of generalized category discovery. The CRL approach demonstrates the power of leveraging contextual information, and the insights from this work could inspire further innovations in this active area of research.
Conclusion
This paper introduces a novel representation learning method called Contextual Representation Learning (CRL) that leverages contextual information to enable more effective generalized category discovery. Through extensive experiments, the authors demonstrate that CRL outperforms previous state-of-the-art approaches on several benchmark datasets.
The key contribution of this work is the insight that contextual cues can be a valuable signal for learning robust and generalizable representations, which in turn facilitates the identification of new object categories beyond the initial training set. This represents an important step towards building machine learning systems that can truly adapt to the rich complexity of the real world.
While the paper acknowledges several limitations and areas for future work, the CRL approach represents a promising direction for advancing the field of generalized category discovery. The incorporation of contextual information could inspire further innovations and lead to more versatile and capable machine learning models in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contextuality Helps Representation Learning for Generalized Category Discovery
Tingzhang Luo, Mingxuan Du, Jiatao Shi, Xinxiang Chen, Bingchen Zhao, Shaoguang Huang
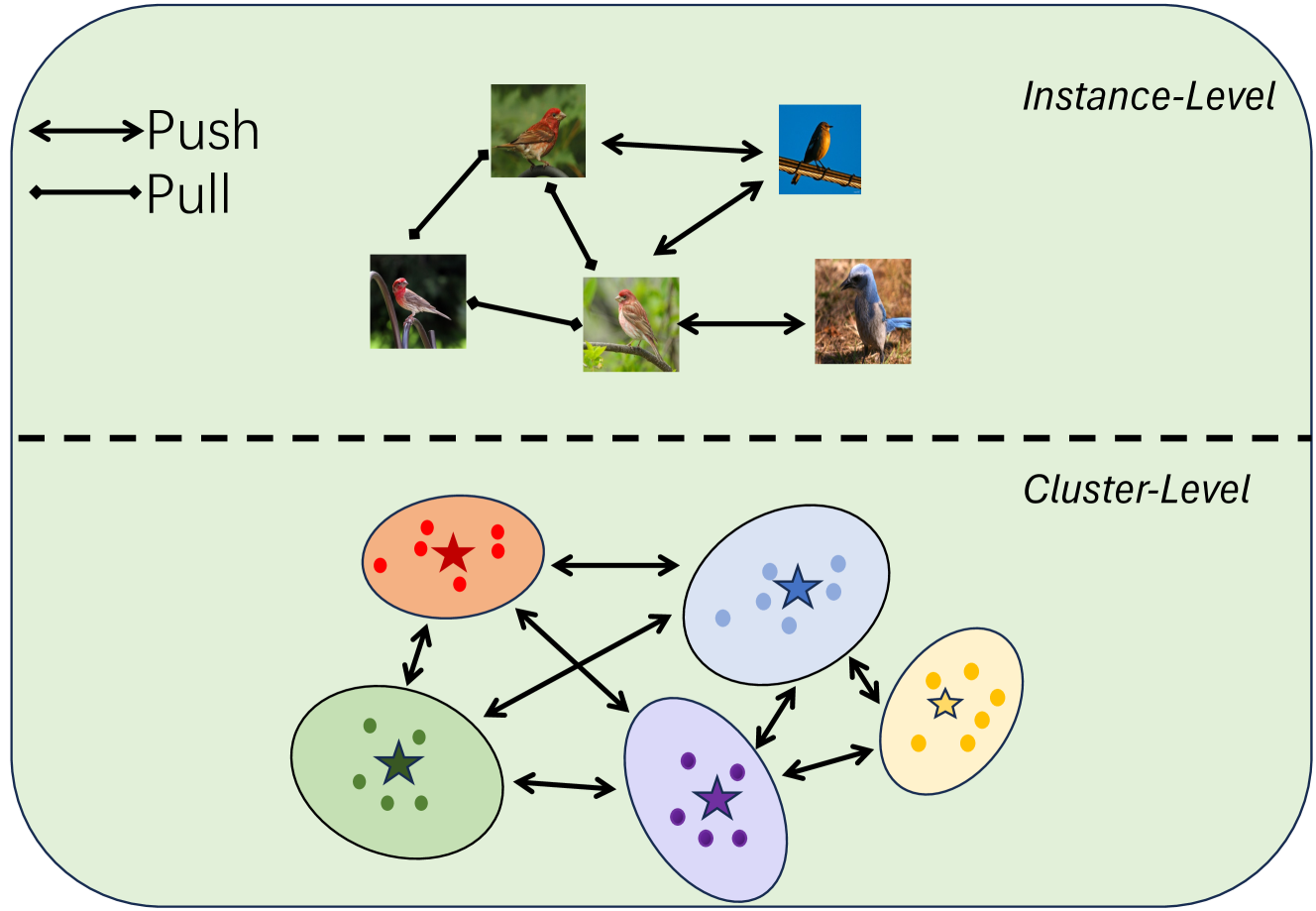
This paper introduces a novel approach to Generalized Category Discovery (GCD) by leveraging the concept of contextuality to enhance the identification and classification of categories in unlabeled datasets. Drawing inspiration from human cognition's ability to recognize objects within their context, we propose a dual-context based method. Our model integrates two levels of contextuality: instance-level, where nearest-neighbor contexts are utilized for contrastive learning, and cluster-level, employing prototypical contrastive learning based on category prototypes. The integration of the contextual information effectively improves the feature learning and thereby the classification accuracy of all categories, which better deals with the real-world datasets. Different from the traditional semi-supervised and novel category discovery techniques, our model focuses on a more realistic and challenging scenario where both known and novel categories are present in the unlabeled data. Extensive experimental results on several benchmark data sets demonstrate that the proposed model outperforms the state-of-the-art. Code is available at: https://github.com/Clarence-CV/Contexuality-GCD
Read more7/30/2024
0
Generalized Categories Discovery for Long-tailed Recognition
Ziyun Li, Christoph Meinel, Haojin Yang
Generalized Class Discovery (GCD) plays a pivotal role in discerning both known and unknown categories from unlabeled datasets by harnessing the insights derived from a labeled set comprising recognized classes. A significant limitation in prevailing GCD methods is their presumption of an equitably distributed category occurrence in unlabeled data. Contrary to this assumption, visual classes in natural environments typically exhibit a long-tailed distribution, with known or prevalent categories surfacing more frequently than their rarer counterparts. Our research endeavors to bridge this disconnect by focusing on the long-tailed Generalized Category Discovery (Long-tailed GCD) paradigm, which echoes the innate imbalances of real-world unlabeled datasets. In response to the unique challenges posed by Long-tailed GCD, we present a robust methodology anchored in two strategic regularizations: (i) a reweighting mechanism that bolsters the prominence of less-represented, tail-end categories, and (ii) a class prior constraint that aligns with the anticipated class distribution. Comprehensive experiments reveal that our proposed method surpasses previous state-of-the-art GCD methods by achieving an improvement of approximately 6 - 9% on ImageNet100 and competitive performance on CIFAR100.
Read more8/27/2024

0
Contrastive Mean-Shift Learning for Generalized Category Discovery
Sua Choi, Dahyun Kang, Minsu Cho
We address the problem of generalized category discovery (GCD) that aims to partition a partially labeled collection of images; only a small part of the collection is labeled and the total number of target classes is unknown. To address this generalized image clustering problem, we revisit the mean-shift algorithm, i.e., a classic, powerful technique for mode seeking, and incorporate it into a contrastive learning framework. The proposed method, dubbed Contrastive Mean-Shift (CMS) learning, trains an image encoder to produce representations with better clustering properties by an iterative process of mean shift and contrastive update. Experiments demonstrate that our method, both in settings with and without the total number of clusters being known, achieves state-of-the-art performance on six public GCD benchmarks without bells and whistles.
Read more4/16/2024
0
Generalized Category Discovery with Large Language Models in the Loop
Wenbin An, Wenkai Shi, Feng Tian, Haonan Lin, QianYing Wang, Yaqiang Wu, Mingxiang Cai, Luyan Wang, Yan Chen, Haiping Zhu, Ping Chen
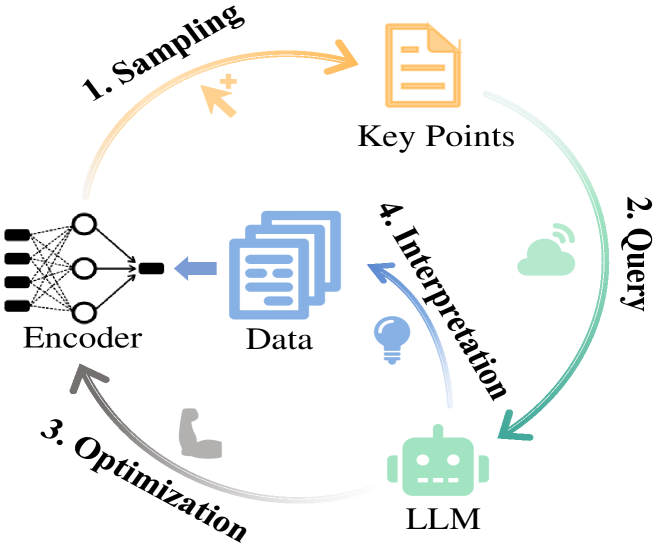
Generalized Category Discovery (GCD) is a crucial task that aims to recognize both known and novel categories from a set of unlabeled data by utilizing a few labeled data with only known categories. Due to the lack of supervision and category information, current methods usually perform poorly on novel categories and struggle to reveal semantic meanings of the discovered clusters, which limits their applications in the real world. To mitigate the above issues, we propose Loop, an end-to-end active-learning framework that introduces Large Language Models (LLMs) into the training loop, which can boost model performance and generate category names without relying on any human efforts. Specifically, we first propose Local Inconsistent Sampling (LIS) to select samples that have a higher probability of falling to wrong clusters, based on neighborhood prediction consistency and entropy of cluster assignment probabilities. Then we propose a Scalable Query strategy to allow LLMs to choose true neighbors of the selected samples from multiple candidate samples. Based on the feedback from LLMs, we perform Refined Neighborhood Contrastive Learning (RNCL) to pull samples and their neighbors closer to learn clustering-friendly representations. Finally, we select representative samples from clusters corresponding to novel categories to allow LLMs to generate category names for them. Extensive experiments on three benchmark datasets show that Loop outperforms SOTA models by a large margin and generates accurate category names for the discovered clusters. Code and data are available at https://github.com/Lackel/LOOP.
Read more5/28/2024