Generalized Face Forgery Detection via Adaptive Learning for Pre-trained Vision Transformer

0
🔎
Sign in to get full access
Overview
- Face forgery detection is a crucial challenge as generative models can create realistic manipulated faces.
- Previous Vision Transformer (ViT) based models showed promise but had issues with generalization.
- The presented Forgery-aware Adaptive Vision Transformer (FA-ViT) aims to address these limitations through an adaptive learning approach.
Plain English Explanation
The rapid progress of generative models has led to the increasing challenge of detecting realistic manipulated faces (also known as deepfakes). While previous Vision Transformer (ViT) based models have shown some promising results, their ability to perform well on different, unseen datasets (generalization) is still not satisfactory.
The researchers propose a new model called the Forgery-aware Adaptive Vision Transformer (FA-ViT) to address this issue. Instead of fully fine-tuning the pre-trained ViT, which can disrupt the original features and potentially overfit to specific dataset patterns, FA-ViT keeps the pre-trained ViT parameters fixed and adds adaptive modules to capture forgery-related features.
The key ideas of FA-ViT are:
- A global adaptive module that uses self-attention to identify global forgery clues.
- A local adaptive module that enhances the detection of local inconsistencies related to forgeries.
- A fine-grained adaptive learning module that emphasizes the representation of genuine faces to improve the model's awareness of forgery-related information.
By using this adaptive approach, the researchers were able to significantly improve the model's performance on cross-dataset evaluations, where it achieved state-of-the-art results. The FA-ViT model also showed increased robustness against unseen perturbations.
Technical Explanation
The researchers present the Forgery-aware Adaptive Vision Transformer (FA-ViT), which builds upon pre-trained Vision Transformer (ViT) models to address the limitations of previous fully fine-tuned ViT-based approaches for face forgery detection.
The key components of FA-ViT are:
-
Global Adaptive Module: This module leverages the self-attention mechanism of ViT to capture long-range interactions among input tokens, allowing the model to identify global forgery clues.
-
Local Adaptive Module: This module is designed to expose local inconsistencies by enhancing the local contextual association, enabling the detection of essential local forgery features.
-
Fine-grained Adaptive Learning Module: This module emphasizes the common compact representation of genuine faces through relationship learning in fine-grained pairs. This helps the adaptive modules to be more aware of fine-grained forgery-related information.
The researchers conducted extensive experiments to evaluate the performance of FA-ViT. The results demonstrate that their approach achieves state-of-the-art performance in cross-dataset evaluations, with AUC scores of 93.83% on the Celeb-DF dataset and 78.32% on the DFDC dataset. Additionally, FA-ViT showed increased robustness against unseen perturbations.
Critical Analysis
The researchers have addressed an important challenge in the field of face forgery detection, where the generalization of Vision Transformer (ViT) based models to different unseen domains has been a limitation. The adaptive learning approach used in FA-ViT appears to be a promising solution, as it allows the model to capture forgery-specific features without disrupting the pre-trained ViT features.
However, the paper does not provide much information about the computational and memory requirements of the proposed FA-ViT model compared to the fully fine-tuned ViT approaches. It would be valuable to understand the trade-offs in terms of model complexity and inference time, as this can be an important consideration for real-world deployment.
Additionally, the paper focuses on evaluating the model's performance on existing datasets, but it would be interesting to see how FA-ViT would perform on more challenging and diverse datasets that may emerge in the future as generative models continue to advance.
Conclusion
The Forgery-aware Adaptive Vision Transformer (FA-ViT) presents a novel approach to address the generalization challenges of Vision Transformer (ViT) based models for face forgery detection. By keeping the pre-trained ViT parameters fixed and introducing adaptive modules to capture forgery-related features, the researchers have achieved state-of-the-art results in cross-dataset evaluations and improved robustness against unseen perturbations.
This work demonstrates the potential of adaptive learning techniques to leverage the strengths of pre-trained models while overcoming their limitations, particularly in the context of detecting increasingly realistic manipulated faces (deepfakes). The insights from this research may inspire further advancements in face forgery detection and contribute to the ongoing efforts to address the challenges posed by the rapid progress of generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Generalized Face Forgery Detection via Adaptive Learning for Pre-trained Vision Transformer
Anwei Luo, Rizhao Cai, Chenqi Kong, Yakun Ju, Xiangui Kang, Jiwu Huang, Alex C. Kot
With the rapid progress of generative models, the current challenge in face forgery detection is how to effectively detect realistic manipulated faces from different unseen domains. Though previous studies show that pre-trained Vision Transformer (ViT) based models can achieve some promising results after fully fine-tuning on the Deepfake dataset, their generalization performances are still unsatisfactory. One possible reason is that fully fine-tuned ViT-based models may disrupt the pre-trained features [1, 2] and overfit to some data-specific patterns [3]. To alleviate this issue, we present a textbf{F}orgery-aware textbf{A}daptive textbf{Vi}sion textbf{T}ransformer (FA-ViT) under the adaptive learning paradigm, where the parameters in the pre-trained ViT are kept fixed while the designed adaptive modules are optimized to capture forgery features. Specifically, a global adaptive module is designed to model long-range interactions among input tokens, which takes advantage of self-attention mechanism to mine global forgery clues. To further explore essential local forgery clues, a local adaptive module is proposed to expose local inconsistencies by enhancing the local contextual association. In addition, we introduce a fine-grained adaptive learning module that emphasizes the common compact representation of genuine faces through relationship learning in fine-grained pairs, driving these proposed adaptive modules to be aware of fine-grained forgery-aware information. Extensive experiments demonstrate that our FA-ViT achieves state-of-the-arts results in the cross-dataset evaluation, and enhances the robustness against unseen perturbations. Particularly, FA-ViT achieves 93.83% and 78.32% AUC scores on Celeb-DF and DFDC datasets in the cross-dataset evaluation. The code and trained model have been released at: https://github.com/LoveSiameseCat/FAViT.
Read more8/23/2024

0
MoE-FFD: Mixture of Experts for Generalized and Parameter-Efficient Face Forgery Detection
Chenqi Kong, Anwei Luo, Peijun Bao, Yi Yu, Haoliang Li, Zengwei Zheng, Shiqi Wang, Alex C. Kot
Deepfakes have recently raised significant trust issues and security concerns among the public. Compared to CNN face forgery detectors, ViT-based methods take advantage of the expressivity of transformers, achieving superior detection performance. However, these approaches still exhibit the following limitations: (1) Fully fine-tuning ViT-based models from ImageNet weights demands substantial computational and storage resources; (2) ViT-based methods struggle to capture local forgery clues, leading to model bias; (3) These methods limit their scope on only one or few face forgery features, resulting in limited generalizability. To tackle these challenges, this work introduces Mixture-of-Experts modules for Face Forgery Detection (MoE-FFD), a generalized yet parameter-efficient ViT-based approach. MoE-FFD only updates lightweight Low-Rank Adaptation (LoRA) and Adapter layers while keeping the ViT backbone frozen, thereby achieving parameter-efficient training. Moreover, MoE-FFD leverages the expressivity of transformers and local priors of CNNs to simultaneously extract global and local forgery clues. Additionally, novel MoE modules are designed to scale the model's capacity and smartly select optimal forgery experts, further enhancing forgery detection performance. Our proposed learning scheme can be seamlessly adapted to various transformer backbones in a plug-and-play manner. Extensive experimental results demonstrate that the proposed method achieves state-of-the-art face forgery detection performance with significantly reduced parameter overhead. The code is released at: https://github.com/LoveSiameseCat/MoE-FFD.
Read more6/11/2024
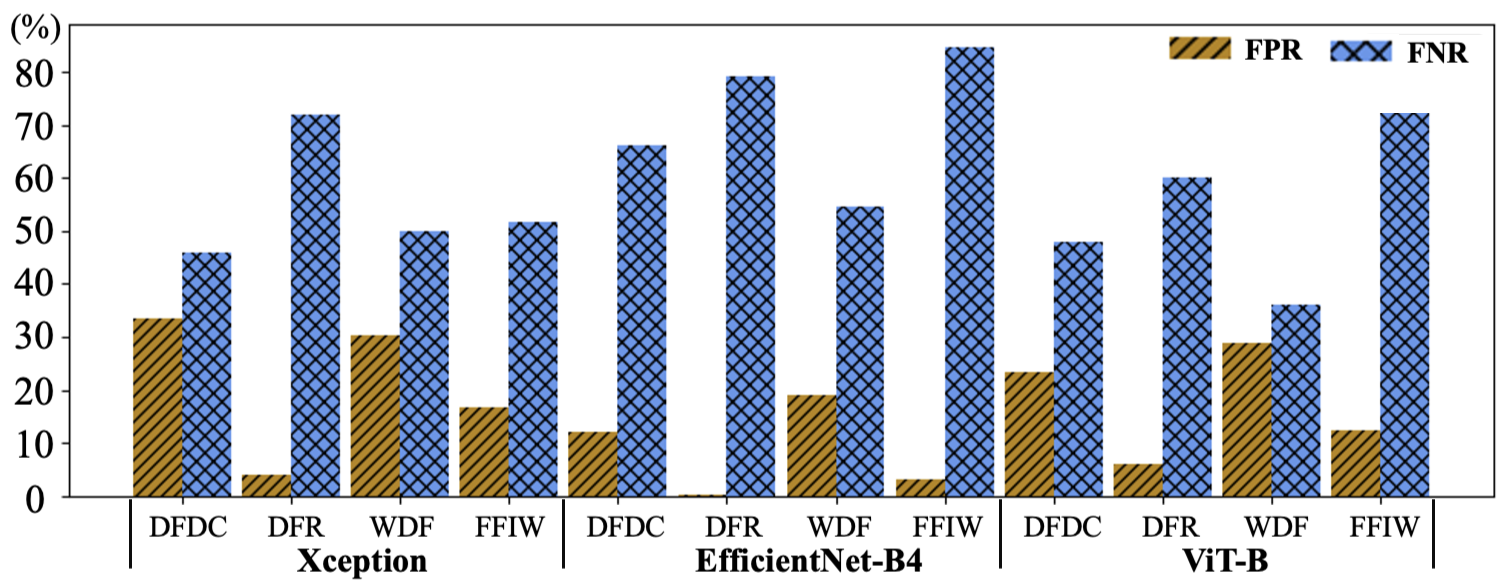
0
Open-Set Deepfake Detection: A Parameter-Efficient Adaptation Method with Forgery Style Mixture
Chenqi Kong, Anwei Luo, Peijun Bao, Haoliang Li, Renjie Wan, Zengwei Zheng, Anderson Rocha, Alex C. Kot
Open-set face forgery detection poses significant security threats and presents substantial challenges for existing detection models. These detectors primarily have two limitations: they cannot generalize across unknown forgery domains and inefficiently adapt to new data. To address these issues, we introduce an approach that is both general and parameter-efficient for face forgery detection. It builds on the assumption that different forgery source domains exhibit distinct style statistics. Previous methods typically require fully fine-tuning pre-trained networks, consuming substantial time and computational resources. In turn, we design a forgery-style mixture formulation that augments the diversity of forgery source domains, enhancing the model's generalizability across unseen domains. Drawing on recent advancements in vision transformers (ViT) for face forgery detection, we develop a parameter-efficient ViT-based detection model that includes lightweight forgery feature extraction modules and enables the model to extract global and local forgery clues simultaneously. We only optimize the inserted lightweight modules during training, maintaining the original ViT structure with its pre-trained ImageNet weights. This training strategy effectively preserves the informative pre-trained knowledge while flexibly adapting the model to the task of Deepfake detection. Extensive experimental results demonstrate that the designed model achieves state-of-the-art generalizability with significantly reduced trainable parameters, representing an important step toward open-set Deepfake detection in the wild.
Read more8/26/2024
0
Liveness Detection in Computer Vision: Transformer-based Self-Supervised Learning for Face Anti-Spoofing
Arman Keresh, Pakizar Shamoi
Face recognition systems are increasingly used in biometric security for convenience and effectiveness. However, they remain vulnerable to spoofing attacks, where attackers use photos, videos, or masks to impersonate legitimate users. This research addresses these vulnerabilities by exploring the Vision Transformer (ViT) architecture, fine-tuned with the DINO framework. The DINO framework facilitates self-supervised learning, enabling the model to learn distinguishing features from unlabeled data. We compared the performance of the proposed fine-tuned ViT model using the DINO framework against a traditional CNN model, EfficientNet b2, on the face anti-spoofing task. Numerous tests on standard datasets show that the ViT model performs better than the CNN model in terms of accuracy and resistance to different spoofing methods. Additionally, we collected our own dataset from a biometric application to validate our findings further. This study highlights the superior performance of transformer-based architecture in identifying complex spoofing cues, leading to significant advancements in biometric security.
Read more6/21/2024