Liveness Detection in Computer Vision: Transformer-based Self-Supervised Learning for Face Anti-Spoofing

0
Sign in to get full access
Overview
- This paper presents a novel approach to liveness detection in computer vision, using transformer-based self-supervised learning for face anti-spoofing.
- The researchers developed a transformer-based model that can detect whether a facial image is real or a spoofed/fake image, without the need for labeled training data.
- The model is trained in a self-supervised manner, learning to classify real vs. fake faces by leveraging the inherent structure and patterns in the data, rather than relying on manually annotated labels.
- This self-supervised learning approach is shown to outperform traditional supervised methods for face anti-spoofing, and has the potential to be more robust and adaptable to new data and scenarios.
Plain English Explanation
The paper describes a new way to detect whether a facial image is real or fake, using a type of machine learning model called a transformer. Transformers are a powerful type of neural network that can learn to recognize patterns and relationships in data, without needing to be explicitly told what those patterns are.
In this case, the researchers trained their transformer-based model to distinguish between real faces and fake or "spoofed" faces, which might be created using things like photos, video replays, or 3D masks. Importantly, the model was trained in a "self-supervised" way, meaning it learned these distinctions by analyzing the structure and patterns in the facial images themselves, rather than relying on human-provided labels of which images were real or fake.
This self-supervised approach is valuable because it can work with readily available facial images, without requiring the time-consuming and expensive process of manually labeling large datasets. The transformer model is able to pick up on the subtle differences between real and fake faces, and apply that knowledge to accurately classify new images.
The researchers show that their self-supervised transformer model outperforms traditional supervised methods for this face anti-spoofing task. This suggests the transformer-based approach could be more robust and adaptable to new types of facial data or spoofing techniques, compared to models that require extensive labeled training data.
Technical Explanation
The paper proposes a novel transformer-based self-supervised learning approach for face anti-spoofing. The researchers developed a transformer model that can distinguish between real and spoofed facial images, without needing labeled training data.
The model is trained in a self-supervised manner, where it learns to classify real vs. fake faces by analyzing the intrinsic structure and patterns in the facial images themselves. This is in contrast to traditional supervised approaches that rely on manually annotated datasets of real and spoofed faces.
The self-supervised training process involves the model learning to predict the relative position of one facial patch with respect to another, as well as predicting whether a given facial patch is real or fake. By solving these pretext tasks, the model is able to extract robust features that discriminate between genuine and spoofed faces.
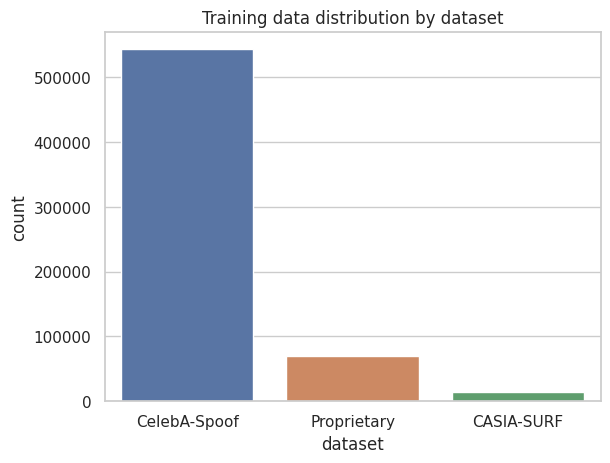
Experiments on standard face anti-spoofing benchmarks showed that the proposed self-supervised transformer model outperformed previous state-of-the-art supervised methods. The authors attribute this to the transformer's ability to capture fine-grained spatial and temporal cues that are indicative of liveness, without requiring explicitly labeled training data.
Critical Analysis
The paper presents a compelling approach to face anti-spoofing that leverages the power of transformer-based self-supervised learning. However, the authors do note some potential limitations and areas for further research:
-
The self-supervised training process, while effective, is computationally intensive and may require significant compute resources to scale up. Techniques to improve the efficiency of self-supervised training could help make the method more practical for real-world deployment.
-
The experiments were conducted on standard benchmark datasets, which may not fully capture the diversity and complexity of real-world facial spoofing attacks. Further evaluation on more diverse and challenging datasets would be valuable to assess the model's robustness.
-
While the self-supervised approach reduces the need for labeled training data, it still requires a substantial amount of unlabeled facial images for pre-training. Exploring ways to further reduce the data requirements, such as through few-shot or zero-shot learning, could expand the applicability of the method.
Overall, the paper presents an innovative and promising approach to face anti-spoofing that has the potential to be more adaptable and robust than traditional supervised methods. The self-supervised transformer-based model is an exciting development in the field of computer vision and liveness detection.
Conclusion
This paper introduces a novel transformer-based self-supervised learning approach for face anti-spoofing, which can effectively distinguish between real and spoofed facial images without the need for labeled training data. The key contributions of this work include:
- Development of a transformer model that can learn to classify real vs. fake faces by analyzing the inherent structure and patterns in the facial images themselves, through a self-supervised training process.
- Demonstration that the proposed self-supervised transformer model outperforms previous state-of-the-art supervised methods for face anti-spoofing on standard benchmarks.
- Potential for the self-supervised approach to be more robust and adaptable to new types of facial data and spoofing techniques, compared to models reliant on manually annotated training sets.
The paper's innovative use of transformers and self-supervised learning for the critical task of liveness detection has significant implications for improving the security and reliability of facial recognition systems. Further research to address the noted limitations and expand the capabilities of this approach could lead to important advancements in computer vision and anti-spoofing technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Liveness Detection in Computer Vision: Transformer-based Self-Supervised Learning for Face Anti-Spoofing
Arman Keresh, Pakizar Shamoi
Face recognition systems are increasingly used in biometric security for convenience and effectiveness. However, they remain vulnerable to spoofing attacks, where attackers use photos, videos, or masks to impersonate legitimate users. This research addresses these vulnerabilities by exploring the Vision Transformer (ViT) architecture, fine-tuned with the DINO framework. The DINO framework facilitates self-supervised learning, enabling the model to learn distinguishing features from unlabeled data. We compared the performance of the proposed fine-tuned ViT model using the DINO framework against a traditional CNN model, EfficientNet b2, on the face anti-spoofing task. Numerous tests on standard datasets show that the ViT model performs better than the CNN model in terms of accuracy and resistance to different spoofing methods. Additionally, we collected our own dataset from a biometric application to validate our findings further. This study highlights the superior performance of transformer-based architecture in identifying complex spoofing cues, leading to significant advancements in biometric security.
Read more6/21/2024
0
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
This paper investigates the effectiveness of self-supervised pre-trained vision transformers (ViTs) compared to supervised pre-trained ViTs and conventional neural networks (ConvNets) for detecting facial deepfake images and videos. It examines their potential for improved generalization and explainability, especially with limited training data. Despite the success of transformer architectures in various tasks, the deepfake detection community is hesitant to use large ViTs as feature extractors due to their perceived need for extensive data and suboptimal generalization with small datasets. This contrasts with ConvNets, which are already established as robust feature extractors. Additionally, training ViTs from scratch requires significant resources, limiting their use to large companies. Recent advancements in self-supervised learning (SSL) for ViTs, like masked autoencoders and DINOs, show adaptability across diverse tasks and semantic segmentation capabilities. By leveraging SSL ViTs for deepfake detection with modest data and partial fine-tuning, we find comparable adaptability to deepfake detection and explainability via the attention mechanism. Moreover, partial fine-tuning of ViTs is a resource-efficient option.
Read more8/12/2024
👀
0
A Timely Survey on Vision Transformer for Deepfake Detection
Zhikan Wang, Zhongyao Cheng, Jiajie Xiong, Xun Xu, Tianrui Li, Bharadwaj Veeravalli, Xulei Yang
In recent years, the rapid advancement of deepfake technology has revolutionized content creation, lowering forgery costs while elevating quality. However, this progress brings forth pressing concerns such as infringements on individual rights, national security threats, and risks to public safety. To counter these challenges, various detection methodologies have emerged, with Vision Transformer (ViT)-based approaches showcasing superior performance in generality and efficiency. This survey presents a timely overview of ViT-based deepfake detection models, categorized into standalone, sequential, and parallel architectures. Furthermore, it succinctly delineates the structure and characteristics of each model. By analyzing existing research and addressing future directions, this survey aims to equip researchers with a nuanced understanding of ViT's pivotal role in deepfake detection, serving as a valuable reference for both academic and practical pursuits in this domain.
Read more5/15/2024
🔎
0
Generalized Face Forgery Detection via Adaptive Learning for Pre-trained Vision Transformer
Anwei Luo, Rizhao Cai, Chenqi Kong, Yakun Ju, Xiangui Kang, Jiwu Huang, Alex C. Kot
With the rapid progress of generative models, the current challenge in face forgery detection is how to effectively detect realistic manipulated faces from different unseen domains. Though previous studies show that pre-trained Vision Transformer (ViT) based models can achieve some promising results after fully fine-tuning on the Deepfake dataset, their generalization performances are still unsatisfactory. One possible reason is that fully fine-tuned ViT-based models may disrupt the pre-trained features [1, 2] and overfit to some data-specific patterns [3]. To alleviate this issue, we present a textbf{F}orgery-aware textbf{A}daptive textbf{Vi}sion textbf{T}ransformer (FA-ViT) under the adaptive learning paradigm, where the parameters in the pre-trained ViT are kept fixed while the designed adaptive modules are optimized to capture forgery features. Specifically, a global adaptive module is designed to model long-range interactions among input tokens, which takes advantage of self-attention mechanism to mine global forgery clues. To further explore essential local forgery clues, a local adaptive module is proposed to expose local inconsistencies by enhancing the local contextual association. In addition, we introduce a fine-grained adaptive learning module that emphasizes the common compact representation of genuine faces through relationship learning in fine-grained pairs, driving these proposed adaptive modules to be aware of fine-grained forgery-aware information. Extensive experiments demonstrate that our FA-ViT achieves state-of-the-arts results in the cross-dataset evaluation, and enhances the robustness against unseen perturbations. Particularly, FA-ViT achieves 93.83% and 78.32% AUC scores on Celeb-DF and DFDC datasets in the cross-dataset evaluation. The code and trained model have been released at: https://github.com/LoveSiameseCat/FAViT.
Read more8/23/2024