Generalizing Conversational Dense Retrieval via LLM-Cognition Data Augmentation

0
📊
Sign in to get full access
Overview
- This paper proposes a framework called ConvAug to improve conversational dense retrieval models.
- Existing models struggle to generalize to diverse real-world conversations due to data sparsity.
- ConvAug generates multi-level augmented conversations to capture the varied nature of conversational contexts.
- It uses a cognition-aware process to mitigate issues like false positives and hallucinations during generation.
- A difficulty-adaptive sample filter selects challenging samples to expand the model's learning space.
- Contrastive learning is then used to train a better conversational context encoder.
Plain English Explanation
The paper focuses on improving conversational dense retrieval models, which are used to find relevant information in conversations.
Existing models often have trouble handling the wide variety of ways conversations can unfold in the real world. This is because they are trained on a limited set of conversations, so they struggle to generalize to new, diverse scenarios.
To address this, the researchers developed a framework called ConvAug. ConvAug first generates many simulated conversations that capture different ways a conversation could go. This helps the model learn from a broader range of examples.
The generation process is designed to avoid certain problems, like creating conversations that don't make sense or including made-up information. ConvAug also selects the most challenging conversation samples for the model to learn from, giving it a bigger learning space.
Finally, the model is trained using a contrastive learning approach, which helps it better encode the context of a conversation.
The key idea is to give the model exposure to a wider variety of conversations, while carefully controlling the generation process to ensure the examples are useful for learning. This allows the model to perform better on real-world conversational data.
Technical Explanation
The paper proposes a framework called ConvAug to improve conversational dense retrieval models. Existing models, like those used for conversational recommendation, often struggle to generalize to diverse real-world conversations due to data sparsity - users can have conversations in many different ways, but the model is only trained on a limited set of examples.
To address this, ConvAug first generates multi-level augmented conversations to capture the varied nature of conversational contexts. This includes generating different ways a conversation could start, how it could progress, and how it could end. Inspired by human cognition, the researchers devise a cognition-aware process to mitigate the generation of false positives, false negatives, and hallucinations.
Additionally, ConvAug develops a difficulty-adaptive sample filter that selects the most challenging conversation samples for the model to learn from. This gives the model a larger learning space to improve its performance on complex conversations.
Finally, a contrastive learning objective is employed to train a better conversational context encoder. This helps the model learn to effectively represent the context of a conversation, which is crucial for conversation retrieval tasks.
Extensive experiments on four public datasets, under both normal and zero-shot settings, demonstrate the effectiveness, generalizability, and applicability of ConvAug.
Critical Analysis
The paper presents a well-designed framework to address the data sparsity problem in conversational dense retrieval models. The use of multi-level augmented conversations and the cognition-aware generation process are particularly noteworthy, as they help the model learn from a wider range of examples while maintaining the coherence and realism of the generated conversations.
However, the paper does not provide much detail on the specific techniques used for the cognition-aware generation process. It would be helpful to have a more in-depth explanation of how this process works and how it was evaluated.
Additionally, the paper focuses on improving the conversational context encoder, but it would be interesting to see how ConvAug could be applied to other components of a conversational retrieval system, such as the dialogue state tracker or the response ranker.
Finally, while the experiments demonstrate the effectiveness of ConvAug, it would be valuable to see how the model performs on real-world conversational data, beyond the public datasets used in the study. This could provide further insight into the model's generalization capabilities and its applicability to practical scenarios.
Conclusion
The ConvAug framework proposed in this paper represents a significant step forward in addressing the data sparsity challenge faced by conversational dense retrieval models. By generating diverse, cognition-aware conversational contexts and using a difficulty-adaptive sample filter, the model is able to learn a more robust representation of conversational dynamics.
The use of contrastive learning to train the conversational context encoder is also a promising approach that could be further explored and applied to other conversational AI tasks, such as time-sensitive conversation retrieval.
Overall, this research contributes valuable insights and techniques that could help advance the field of conversational AI and enable more natural, effective interactions between humans and intelligent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Generalizing Conversational Dense Retrieval via LLM-Cognition Data Augmentation
Haonan Chen, Zhicheng Dou, Kelong Mao, Jiongnan Liu, Ziliang Zhao
Conversational search utilizes muli-turn natural language contexts to retrieve relevant passages. Existing conversational dense retrieval models mostly view a conversation as a fixed sequence of questions and responses, overlooking the severe data sparsity problem -- that is, users can perform a conversation in various ways, and these alternate conversations are unrecorded. Consequently, they often struggle to generalize to diverse conversations in real-world scenarios. In this work, we propose a framework for generalizing Conversational dense retrieval via LLM-cognition data Augmentation (ConvAug). ConvAug first generates multi-level augmented conversations to capture the diverse nature of conversational contexts. Inspired by human cognition, we devise a cognition-aware process to mitigate the generation of false positives, false negatives, and hallucinations. Moreover, we develop a difficulty-adaptive sample filter that selects challenging samples for complex conversations, thereby giving the model a larger learning space. A contrastive learning objective is then employed to train a better conversational context encoder. Extensive experiments conducted on four public datasets, under both normal and zero-shot settings, demonstrate the effectiveness, generalizability, and applicability of ConvAug. The code is released at https://github.com/haon-chen/ConvAug.
Read more6/5/2024

0
ChatRetriever: Adapting Large Language Models for Generalized and Robust Conversational Dense Retrieval
Kelong Mao, Chenlong Deng, Haonan Chen, Fengran Mo, Zheng Liu, Tetsuya Sakai, Zhicheng Dou
Conversational search requires accurate interpretation of user intent from complex multi-turn contexts. This paper presents ChatRetriever, which inherits the strong generalization capability of large language models to robustly represent complex conversational sessions for dense retrieval. To achieve this, we propose a simple and effective dual-learning approach that adapts LLM for retrieval via contrastive learning while enhancing the complex session understanding through masked instruction tuning on high-quality conversational instruction tuning data. Extensive experiments on five conversational search benchmarks demonstrate that ChatRetriever substantially outperforms existing conversational dense retrievers, achieving state-of-the-art performance on par with LLM-based rewriting approaches. Furthermore, ChatRetriever exhibits superior robustness in handling diverse conversational contexts. Our work highlights the potential of adapting LLMs for retrieval with complex inputs like conversational search sessions and proposes an effective approach to advance this research direction.
Read more4/23/2024

0
History-Aware Conversational Dense Retrieval
Fengran Mo, Chen Qu, Kelong Mao, Tianyu Zhu, Zhan Su, Kaiyu Huang, Jian-Yun Nie
Conversational search facilitates complex information retrieval by enabling multi-turn interactions between users and the system. Supporting such interactions requires a comprehensive understanding of the conversational inputs to formulate a good search query based on historical information. In particular, the search query should include the relevant information from the previous conversation turns. However, current approaches for conversational dense retrieval primarily rely on fine-tuning a pre-trained ad-hoc retriever using the whole conversational search session, which can be lengthy and noisy. Moreover, existing approaches are limited by the amount of manual supervision signals in the existing datasets. To address the aforementioned issues, we propose a History-Aware Conversational Dense Retrieval (HAConvDR) system, which incorporates two ideas: context-denoised query reformulation and automatic mining of supervision signals based on the actual impact of historical turns. Experiments on two public conversational search datasets demonstrate the improved history modeling capability of HAConvDR, in particular for long conversations with topic shifts.
Read more5/29/2024
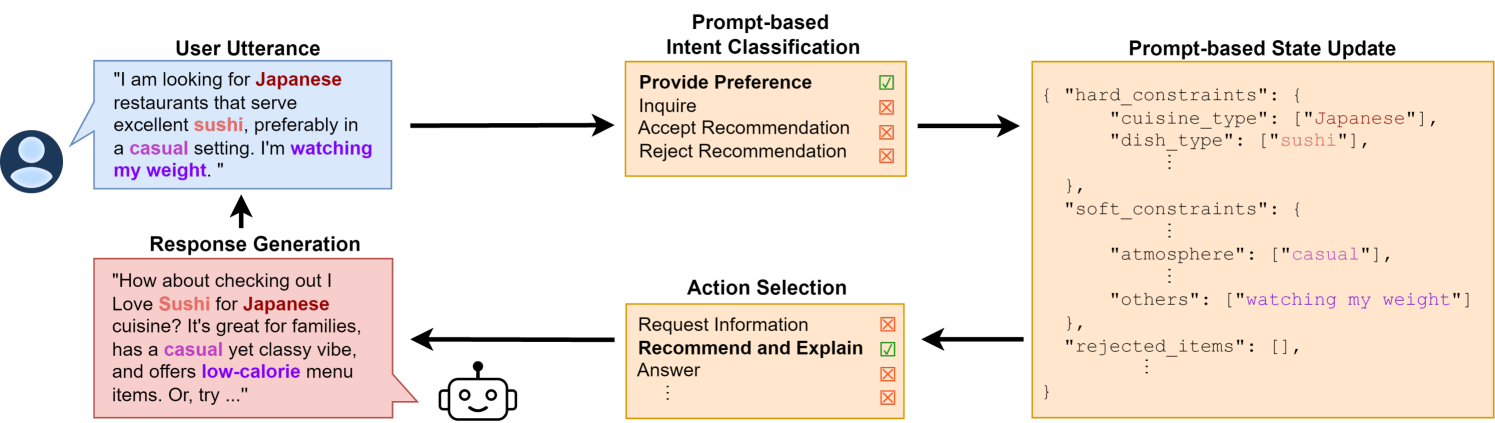
0
Retrieval-Augmented Conversational Recommendation with Prompt-based Semi-Structured Natural Language State Tracking
Sara Kemper, Justin Cui, Kai Dicarlantonio, Kathy Lin, Danjie Tang, Anton Korikov, Scott Sanner
Conversational recommendation (ConvRec) systems must understand rich and diverse natural language (NL) expressions of user preferences and intents, often communicated in an indirect manner (e.g., I'm watching my weight). Such complex utterances make retrieving relevant items challenging, especially if only using often incomplete or out-of-date metadata. Fortunately, many domains feature rich item reviews that cover standard metadata categories and offer complex opinions that might match a user's interests (e.g., classy joint for a date). However, only recently have large language models (LLMs) let us unlock the commonsense connections between user preference utterances and complex language in user-generated reviews. Further, LLMs enable novel paradigms for semi-structured dialogue state tracking, complex intent and preference understanding, and generating recommendations, explanations, and question answers. We thus introduce a novel technology RA-Rec, a Retrieval-Augmented, LLM-driven dialogue state tracking system for ConvRec, showcased with a video, open source GitHub repository, and interactive Google Colab notebook.
Read more6/4/2024