Generating Harder Cross-document Event Coreference Resolution Datasets using Metaphoric Paraphrasing

0

Sign in to get full access
Overview
- This paper introduces a novel approach for generating harder datasets for cross-document event coreference resolution (CDECR) using metaphoric paraphrasing.
- CDECR is the task of determining whether event mentions across multiple documents refer to the same real-world event.
- The authors argue that existing CDECR datasets lack diversity and are not sufficiently challenging, hindering the development of more robust CDECR models.
- To address this, they propose a metaphoric paraphrasing technique to augment existing datasets, creating more linguistically diverse and ambiguous event descriptions.
Plain English Explanation
The paper focuses on the problem of cross-document event coreference resolution (CDECR). This is the task of figuring out whether different mentions of events across multiple documents are referring to the same real-world event. For example, if one document says "The president gave a speech" and another says "The leader addressed the nation," the system should recognize that these are describing the same event.
The authors argue that existing CDECR datasets lack diversity and are not challenging enough, which makes it difficult to develop robust CDECR models. To fix this, they propose a new technique called "metaphoric paraphrasing" to generate more diverse and ambiguous event descriptions. This involves taking existing event descriptions and rewriting them using metaphors and other figurative language.
For instance, instead of "The president gave a speech," the system might generate "The leader took the stage and unleashed a torrent of words." This makes the event description more complex and harder for the CDECR system to interpret, better testing its capabilities.
By creating these more challenging datasets, the authors hope to spur the development of CDECR models that are better able to handle the nuances and ambiguities of real-world event descriptions across documents.
Technical Explanation
The key technical contribution of this paper is a novel data augmentation approach for generating harder CDECR datasets. The authors start with existing CDECR datasets, such as CDECR and CDCR, and apply a metaphoric paraphrasing technique to introduce more linguistic diversity and ambiguity.
Specifically, they use a pre-trained language model to generate metaphoric paraphrases of event descriptions. This involves identifying the key semantic components of an event (e.g., the agent, action, patient) and then replacing them with more figurative language. For example, "The president gave a speech" might become "The leader unleashed a torrent of words."
The authors evaluate the efficacy of this approach by measuring the performance of state-of-the-art CDECR models on the original and augmented datasets. They find that the models exhibit a significant drop in performance on the augmented datasets, indicating that the metaphoric paraphrasing has indeed created more challenging examples.
Additionally, the authors conduct a human evaluation to assess the linguistic diversity and ambiguity of the generated paraphrases. The results show that the paraphrases are rated as more diverse and ambiguous than the original event descriptions, supporting the authors' claims about the efficacy of their approach.
Critical Analysis
The authors present a compelling approach for generating harder CDECR datasets, which is an important step in driving progress in this field. By introducing more linguistic diversity and ambiguity, the augmented datasets can help uncover weaknesses in existing CDECR models and spur the development of more robust and generalizable systems.
That said, the authors acknowledge several limitations of their work. First, the metaphoric paraphrasing technique is not fully automated and requires some manual curation to ensure the generated paraphrases are coherent and meaningful. This could limit the scalability of the approach.
Additionally, the authors note that their evaluation focused on the linguistic properties of the generated paraphrases, rather than their semantic correctness. It's possible that some of the paraphrases could introduce unintended changes in meaning, which could undermine the usefulness of the augmented datasets for CDECR model training and evaluation.
Further research is needed to address these limitations and explore other data augmentation techniques for CDECR. For example, enhancing cross-document event coreference resolution by incorporating world knowledge or using a rationale-centric counterfactual data augmentation method could also help create more challenging and diverse CDECR datasets.
Conclusion
This paper presents an innovative approach for generating harder CDECR datasets using metaphoric paraphrasing. The authors demonstrate that this technique can effectively introduce more linguistic diversity and ambiguity, posing greater challenges for state-of-the-art CDECR models.
By making CDECR datasets more challenging, this work has the potential to drive significant progress in the field, leading to the development of more robust and generalizable event coreference resolution systems. These systems could have far-reaching applications in areas like natural language understanding, information extraction, and knowledge base construction.
Overall, this paper makes an important contribution to the CDECR literature and provides a promising direction for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generating Harder Cross-document Event Coreference Resolution Datasets using Metaphoric Paraphrasing
Shafiuddin Rehan Ahmed, Zhiyong Eric Wang, George Arthur Baker, Kevin Stowe, James H. Martin
The most popular Cross-Document Event Coreference Resolution (CDEC) datasets fail to convey the true difficulty of the task, due to the lack of lexical diversity between coreferring event triggers (words or phrases that refer to an event). Furthermore, there is a dearth of event datasets for figurative language, limiting a crucial avenue of research in event comprehension. We address these two issues by introducing ECB+META, a lexically rich variant of Event Coref Bank Plus (ECB+) for CDEC on symbolic and metaphoric language. We use ChatGPT as a tool for the metaphoric transformation of sentences in the documents of ECB+, then tag the original event triggers in the transformed sentences in a semi-automated manner. In this way, we avoid the re-annotation of expensive coreference links. We present results that show existing methods that work well on ECB+ struggle with ECB+META, thereby paving the way for CDEC research on a much more challenging dataset. Code/data: https://github.com/ahmeshaf/llms_coref
Read more7/18/2024
0
Multimodal Cross-Document Event Coreference Resolution Using Linear Semantic Transfer and Mixed-Modality Ensembles
Abhijnan Nath, Huma Jamil, Shafiuddin Rehan Ahmed, George Baker, Rahul Ghosh, James H. Martin, Nathaniel Blanchard, Nikhil Krishnaswamy
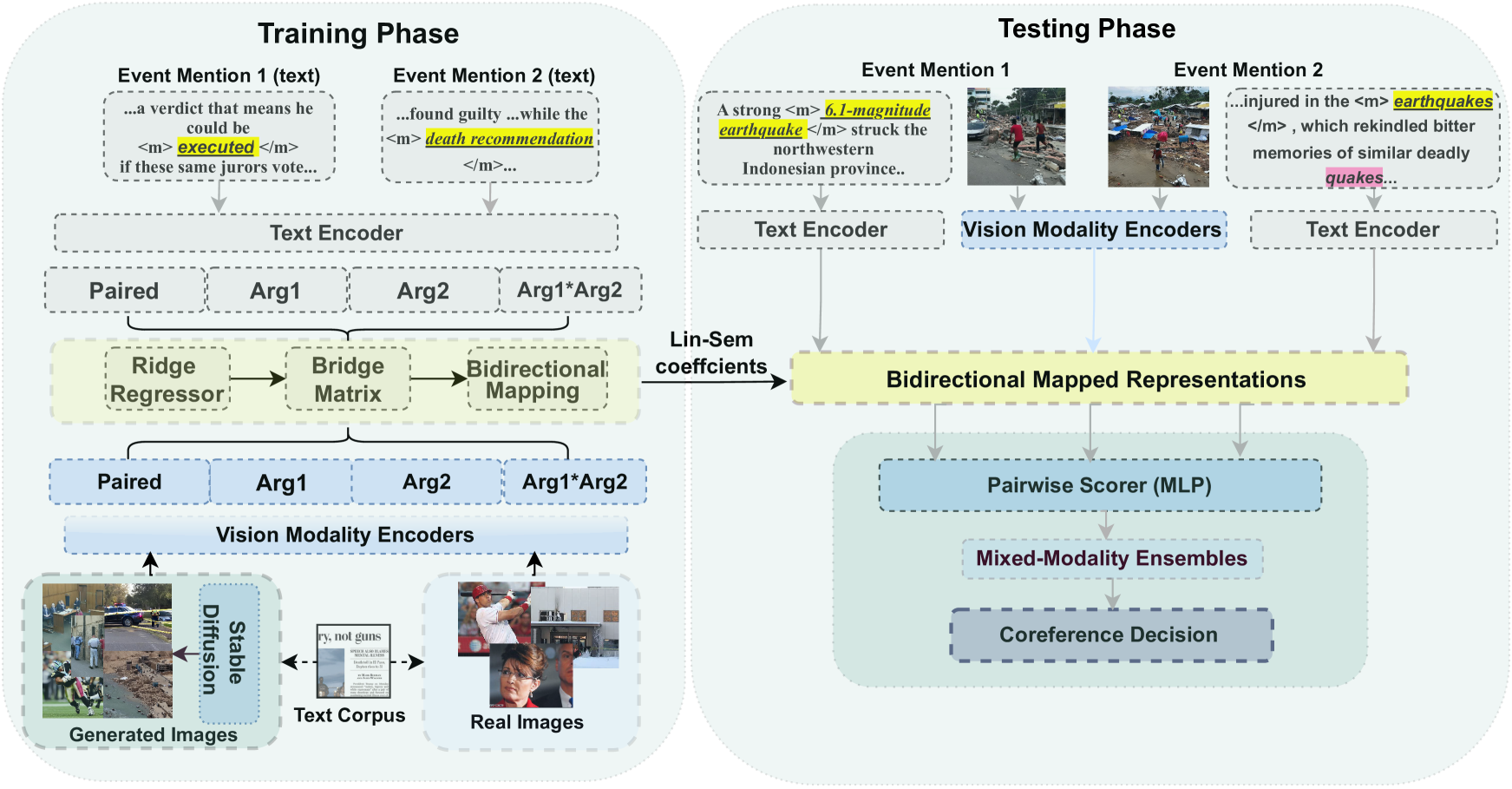
Event coreference resolution (ECR) is the task of determining whether distinct mentions of events within a multi-document corpus are actually linked to the same underlying occurrence. Images of the events can help facilitate resolution when language is ambiguous. Here, we propose a multimodal cross-document event coreference resolution method that integrates visual and textual cues with a simple linear map between vision and language models. As existing ECR benchmark datasets rarely provide images for all event mentions, we augment the popular ECB+ dataset with event-centric images scraped from the internet and generated using image diffusion models. We establish three methods that incorporate images and text for coreference: 1) a standard fused model with finetuning, 2) a novel linear mapping method without finetuning and 3) an ensembling approach based on splitting mention pairs by semantic and discourse-level difficulty. We evaluate on 2 datasets: the augmented ECB+, and AIDA Phase 1. Our ensemble systems using cross-modal linear mapping establish an upper limit (91.9 CoNLL F1) on ECB+ ECR performance given the preprocessing assumptions used, and establish a novel baseline on AIDA Phase 1. Our results demonstrate the utility of multimodal information in ECR for certain challenging coreference problems, and highlight a need for more multimodal resources in the coreference resolution space.
Read more4/16/2024

0
Synergetic Event Understanding: A Collaborative Approach to Cross-Document Event Coreference Resolution with Large Language Models
Qingkai Min, Qipeng Guo, Xiangkun Hu, Songfang Huang, Zheng Zhang, Yue Zhang
Cross-document event coreference resolution (CDECR) involves clustering event mentions across multiple documents that refer to the same real-world events. Existing approaches utilize fine-tuning of small language models (SLMs) like BERT to address the compatibility among the contexts of event mentions. However, due to the complexity and diversity of contexts, these models are prone to learning simple co-occurrences. Recently, large language models (LLMs) like ChatGPT have demonstrated impressive contextual understanding, yet they encounter challenges in adapting to specific information extraction (IE) tasks. In this paper, we propose a collaborative approach for CDECR, leveraging the capabilities of both a universally capable LLM and a task-specific SLM. The collaborative strategy begins with the LLM accurately and comprehensively summarizing events through prompting. Then, the SLM refines its learning of event representations based on these insights during fine-tuning. Experimental results demonstrate that our approach surpasses the performance of both the large and small language models individually, forming a complementary advantage. Across various datasets, our approach achieves state-of-the-art performance, underscoring its effectiveness in diverse scenarios.
Read more6/5/2024
0
Linear Cross-document Event Coreference Resolution with X-AMR
Shafiuddin Rehan Ahmed, George Arthur Baker, Evi Judge, Michael Regan, Kristin Wright-Bettner, Martha Palmer, James H. Martin
Event Coreference Resolution (ECR) as a pairwise mention classification task is expensive both for automated systems and manual annotations. The task's quadratic difficulty is exacerbated when using Large Language Models (LLMs), making prompt engineering for ECR prohibitively costly. In this work, we propose a graphical representation of events, X-AMR, anchored around individual mentions using a textbf{cross}-document version of textbf{A}bstract textbf{M}eaning textbf{R}epresentation. We then linearize the ECR with a novel multi-hop coreference algorithm over the event graphs. The event graphs simplify ECR, making it a) LLM cost-effective, b) compositional and interpretable, and c) easily annotated. For a fair assessment, we first enrich an existing ECR benchmark dataset with these event graphs using an annotator-friendly tool we introduce. Then, we employ GPT-4, the newest LLM by OpenAI, for these annotations. Finally, using the ECR algorithm, we assess GPT-4 against humans and analyze its limitations. Through this research, we aim to advance the state-of-the-art for efficient ECR and shed light on the potential shortcomings of current LLMs at this task. Code and annotations: url{https://github.com/ahmeshaf/gpt_coref}
Read more4/16/2024