Synergetic Event Understanding: A Collaborative Approach to Cross-Document Event Coreference Resolution with Large Language Models

0

Sign in to get full access
Overview
- This paper proposes a novel approach to cross-document event coreference resolution called "Synergetic Event Understanding" that leverages large language models and a collaborative framework.
- The key idea is to combine information from multiple documents to improve the task of identifying when the same event is being described across different text sources.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improvements over previous state-of-the-art methods.
Plain English Explanation
When reading news articles or other documents, it's common to encounter references to the same real-world event described in multiple places. Synergetic Event Understanding is a technique that helps computers understand when these kinds of cross-document event references are occurring.
The core insight is that by looking at the information in multiple documents together, a computer system can more accurately determine when the same underlying event is being described, even if the wording is slightly different across sources. This is done by using large language models - powerful AI systems that can understand the meaning and context of text.
The collaborative framework proposed in the paper allows these language models to work together, sharing information to collectively arrive at a better understanding of the events described across the documents. This is more effective than having each document analyzed in isolation.
Overall, this research advances the state-of-the-art in cross-document event coreference resolution, which has important applications in areas like news summarization, knowledge base construction, and question answering. By better connecting event references across texts, machines can build a more cohesive and comprehensive understanding of real-world occurrences.
Technical Explanation
The key technical contributions of this paper are:
-
A novel "Synergetic Event Understanding" framework that leverages large language models to perform cross-document event coreference resolution in a collaborative manner. This builds on prior work in within-document event coreference resolution using BERT-based models.
-
A rationale-centric counterfactual data augmentation method to enhance the training of the cross-document event coreference model.
-
A schema-aware event extraction component that leverages structured event schemas to improve the identification and representation of event mentions.
The authors evaluate their approach on several benchmark datasets, demonstrating significant improvements over previous state-of-the-art methods. Key insights from the technical evaluation include:
- The collaborative synergetic framework outperforms single-document and pipeline-based approaches, highlighting the benefits of jointly reasoning across multiple documents.
- The rationale-centric data augmentation technique is effective at improving model performance, particularly on rare event types.
- The schema-aware event extraction component brings meaningful gains, suggesting the value of incorporating structured domain knowledge.
Critical Analysis
The paper presents a compelling approach to the challenging problem of cross-document event coreference resolution. The key strengths are the innovative use of large language models in a collaborative framework, as well as the thoughtful integration of structured event schema information.
That said, some potential limitations and areas for further research are worth considering:
- The evaluation is conducted on relatively small, manually-annotated datasets. It would be important to validate the approach on larger, more diverse real-world corpora to assess its scalability and robustness.
- While the rationale-centric data augmentation method is shown to be effective, the reliance on human-annotated rationales may limit the approach's broader applicability. Exploring more automated data augmentation techniques could be fruitful.
- The paper does not deeply explore the model's failure cases or provide a detailed error analysis. Understanding the specific challenges that remain would help guide future research directions.
Overall, this work represents a significant advancement in cross-document event understanding and opens up interesting avenues for further exploration in this important area of natural language processing.
Conclusion
This paper introduces a novel "Synergetic Event Understanding" framework that leverages large language models and a collaborative approach to significantly advance the state-of-the-art in cross-document event coreference resolution. By combining information across multiple documents, the proposed method demonstrates impressive performance gains on benchmark datasets.
The key technical innovations, including the rationale-centric data augmentation and schema-aware event extraction, provide valuable insights into improving event understanding systems. While some limitations and future research directions remain, this work represents an important step forward in building more comprehensive and coherent event-centric knowledge from text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Synergetic Event Understanding: A Collaborative Approach to Cross-Document Event Coreference Resolution with Large Language Models
Qingkai Min, Qipeng Guo, Xiangkun Hu, Songfang Huang, Zheng Zhang, Yue Zhang
Cross-document event coreference resolution (CDECR) involves clustering event mentions across multiple documents that refer to the same real-world events. Existing approaches utilize fine-tuning of small language models (SLMs) like BERT to address the compatibility among the contexts of event mentions. However, due to the complexity and diversity of contexts, these models are prone to learning simple co-occurrences. Recently, large language models (LLMs) like ChatGPT have demonstrated impressive contextual understanding, yet they encounter challenges in adapting to specific information extraction (IE) tasks. In this paper, we propose a collaborative approach for CDECR, leveraging the capabilities of both a universally capable LLM and a task-specific SLM. The collaborative strategy begins with the LLM accurately and comprehensively summarizing events through prompting. Then, the SLM refines its learning of event representations based on these insights during fine-tuning. Experimental results demonstrate that our approach surpasses the performance of both the large and small language models individually, forming a complementary advantage. Across various datasets, our approach achieves state-of-the-art performance, underscoring its effectiveness in diverse scenarios.
Read more6/5/2024
0
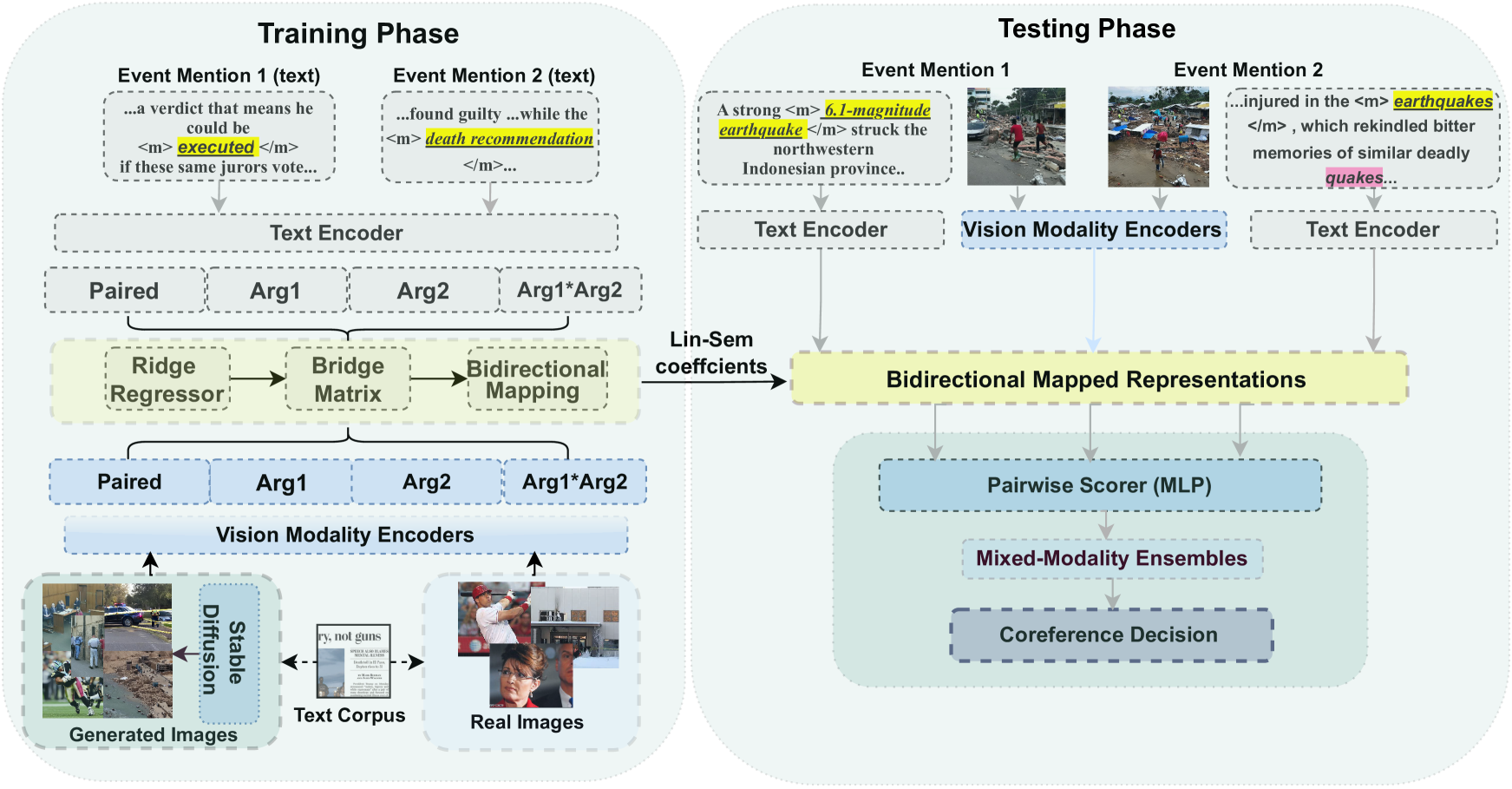
Multimodal Cross-Document Event Coreference Resolution Using Linear Semantic Transfer and Mixed-Modality Ensembles
Abhijnan Nath, Huma Jamil, Shafiuddin Rehan Ahmed, George Baker, Rahul Ghosh, James H. Martin, Nathaniel Blanchard, Nikhil Krishnaswamy
Event coreference resolution (ECR) is the task of determining whether distinct mentions of events within a multi-document corpus are actually linked to the same underlying occurrence. Images of the events can help facilitate resolution when language is ambiguous. Here, we propose a multimodal cross-document event coreference resolution method that integrates visual and textual cues with a simple linear map between vision and language models. As existing ECR benchmark datasets rarely provide images for all event mentions, we augment the popular ECB+ dataset with event-centric images scraped from the internet and generated using image diffusion models. We establish three methods that incorporate images and text for coreference: 1) a standard fused model with finetuning, 2) a novel linear mapping method without finetuning and 3) an ensembling approach based on splitting mention pairs by semantic and discourse-level difficulty. We evaluate on 2 datasets: the augmented ECB+, and AIDA Phase 1. Our ensemble systems using cross-modal linear mapping establish an upper limit (91.9 CoNLL F1) on ECB+ ECR performance given the preprocessing assumptions used, and establish a novel baseline on AIDA Phase 1. Our results demonstrate the utility of multimodal information in ECR for certain challenging coreference problems, and highlight a need for more multimodal resources in the coreference resolution space.
Read more4/16/2024

0
Generating Harder Cross-document Event Coreference Resolution Datasets using Metaphoric Paraphrasing
Shafiuddin Rehan Ahmed, Zhiyong Eric Wang, George Arthur Baker, Kevin Stowe, James H. Martin
The most popular Cross-Document Event Coreference Resolution (CDEC) datasets fail to convey the true difficulty of the task, due to the lack of lexical diversity between coreferring event triggers (words or phrases that refer to an event). Furthermore, there is a dearth of event datasets for figurative language, limiting a crucial avenue of research in event comprehension. We address these two issues by introducing ECB+META, a lexically rich variant of Event Coref Bank Plus (ECB+) for CDEC on symbolic and metaphoric language. We use ChatGPT as a tool for the metaphoric transformation of sentences in the documents of ECB+, then tag the original event triggers in the transformed sentences in a semi-automated manner. In this way, we avoid the re-annotation of expensive coreference links. We present results that show existing methods that work well on ECB+ struggle with ECB+META, thereby paving the way for CDEC research on a much more challenging dataset. Code/data: https://github.com/ahmeshaf/llms_coref
Read more7/18/2024

0
Enhancing Cross-Document Event Coreference Resolution by Discourse Structure and Semantic Information
Qiang Gao, Bobo Li, Zixiang Meng, Yunlong Li, Jun Zhou, Fei Li, Chong Teng, Donghong Ji
Existing cross-document event coreference resolution models, which either compute mention similarity directly or enhance mention representation by extracting event arguments (such as location, time, agent, and patient), lacking the ability to utilize document-level information. As a result, they struggle to capture long-distance dependencies. This shortcoming leads to their underwhelming performance in determining coreference for the events where their argument information relies on long-distance dependencies. In light of these limitations, we propose the construction of document-level Rhetorical Structure Theory (RST) trees and cross-document Lexical Chains to model the structural and semantic information of documents. Subsequently, cross-document heterogeneous graphs are constructed and GAT is utilized to learn the representations of events. Finally, a pair scorer calculates the similarity between each pair of events and co-referred events can be recognized using standard clustering algorithm. Additionally, as the existing cross-document event coreference datasets are limited to English, we have developed a large-scale Chinese cross-document event coreference dataset to fill this gap, which comprises 53,066 event mentions and 4,476 clusters. After applying our model on the English and Chinese datasets respectively, it outperforms all baselines by large margins.
Read more6/26/2024