3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
2403.03954
0
0
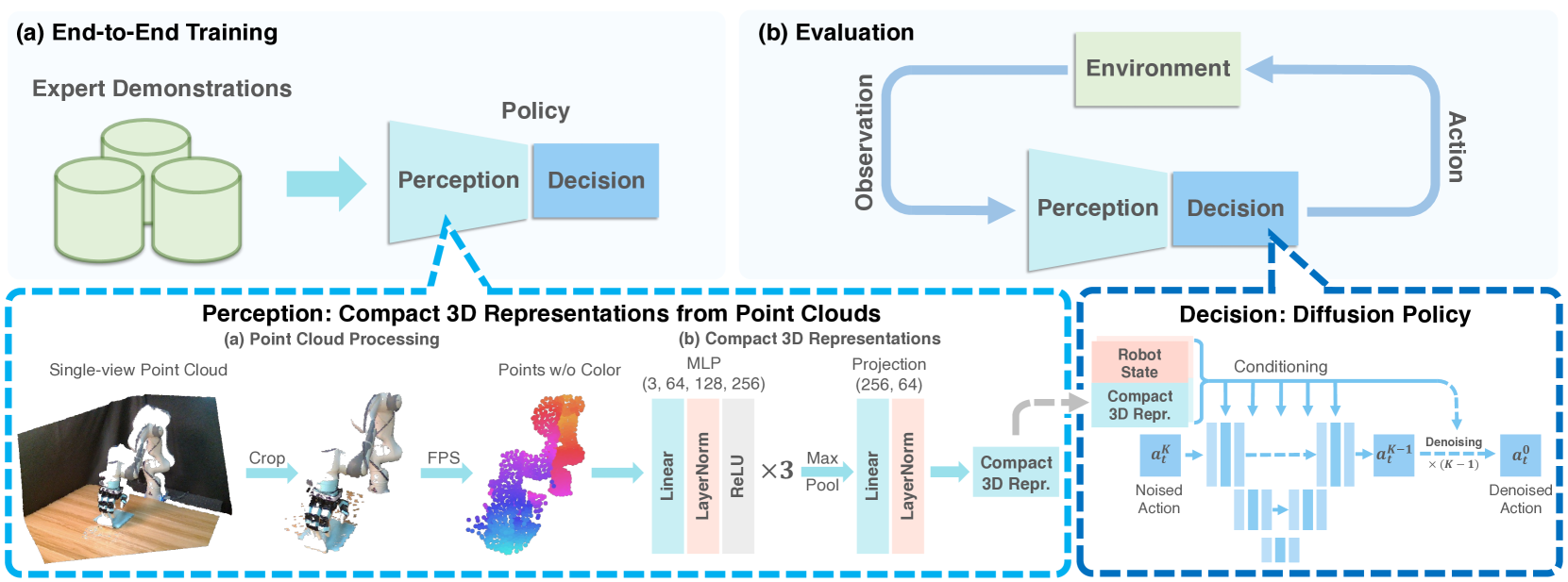
Abstract
Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 24.2% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning. Videos, code, and data are available on https://3d-diffusion-policy.github.io .
Create account to get full access
Overview
- The paper introduces a new 3D diffusion policy algorithm for robotics applications.
- The approach uses diffusion models to generate diverse and realistic 3D object shapes.
- Experiments show the method can effectively learn complex 3D object distributions and generate high-quality samples.
Plain English Explanation
The paper describes a new way for robots to understand and create three-dimensional (3D) objects. The key idea is to use "diffusion models", which are a type of machine learning algorithm that can generate diverse and realistic-looking 3D shapes.
Diffusion models work by starting with simple random noise and then gradually transforming it into more complex and natural-looking 3D objects. This is done through a process of "diffusion", where the model learns to gradually add more detail and structure to the initial noise in a step-by-step fashion.
The researchers show that this diffusion-based approach can effectively learn the complex distributions of real-world 3D objects, like chairs, tables, and other common objects. By learning these distributions, the model can then generate new 3D object samples that are visually similar to the real ones, but unique and novel.
This capability could be very useful for robotics applications, where a robot needs to understand and interact with 3D objects in its environment. The diffusion-based approach provides a flexible and powerful way for the robot to model and generate diverse 3D object shapes, which could improve the robot's perception, manipulation, and planning abilities.
Technical Explanation
The paper introduces a 3D diffusion policy (3DP) algorithm for 3D object generation. 3DP is based on recent advancements in diffusion models, which have shown impressive results in generating realistic 2D images.
The key idea is to extend diffusion models to the 3D domain, allowing the model to learn and generate complex 3D object shapes. The 3DP model takes as input a 3D point cloud representation of an object and learns to gradually refine this input through a diffusion process, adding more details and structure to produce a high-quality 3D object sample.
The paper describes the overall 3DP architecture, which includes a 3D encoder network, a diffusion module, and a 3D decoder network. Extensive experiments are conducted on several 3D object datasets, demonstrating that 3DP can effectively learn the underlying distributions of real-world 3D objects and generate diverse, realistic samples.
The results show that 3DP outperforms several baseline 3D generation methods in terms of sample quality and diversity. Additionally, the paper investigates the model's ability to generate 3D objects conditioned on various input modalities, such as 2D images or partial point clouds, showing the flexibility of the approach.
Critical Analysis
The 3DP algorithm presented in the paper is a promising step forward in 3D object generation for robotics applications. The use of diffusion models to learn and generate complex 3D shapes is a novel and interesting approach, with clear potential benefits for robot perception, manipulation, and planning.
However, the paper does not address some important limitations and areas for further research. For example, the experiments are conducted on relatively simple and clean 3D object datasets, and it's unclear how well the method would scale to more diverse and noisy real-world data. Additionally, the computational efficiency and inference speed of the 3DP model are not thoroughly evaluated, which could be crucial for real-time robotics applications.
Furthermore, the paper does not discuss potential biases or ethical considerations that may arise from deploying such a 3D generation system in the real world. For example, if the model is trained on datasets that lack diversity or representation, it could perpetuate harmful stereotypes or biases in the generated 3D objects.
Overall, the 3DP algorithm represents an interesting and potentially impactful contribution to the field of 3D object generation for robotics. However, further research is needed to address the limitations and ensure the responsible development and deployment of such technologies.
Conclusion
The 3D diffusion policy (3DP) algorithm presented in this paper offers a novel approach to 3D object generation for robotics applications. By leveraging the power of diffusion models, 3DP can effectively learn and generate diverse, realistic 3D object shapes, which could significantly improve a robot's ability to perceive, manipulate, and interact with its 3D environment.
While the results are promising, the paper highlights the need for further research to address the limitations of the current approach and ensure the responsible development of such 3D generation technologies. As robotics continues to advance, it will be crucial to consider the ethical implications and potential biases of these systems, in addition to their technical capabilities.
Overall, the 3DP algorithm represents an exciting step forward in the field of 3D object generation for robotics, with the potential to unlock new capabilities and push the boundaries of what robots can achieve in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generating Images with 3D Annotations Using Diffusion Models
Wufei Ma, Qihao Liu, Jiahao Wang, Angtian Wang, Xiaoding Yuan, Yi Zhang, Zihao Xiao, Guofeng Zhang, Beijia Lu, Ruxiao Duan, Yongrui Qi, Adam Kortylewski, Yaoyao Liu, Alan Yuille
0
0
Diffusion models have emerged as a powerful generative method, capable of producing stunning photo-realistic images from natural language descriptions. However, these models lack explicit control over the 3D structure in the generated images. Consequently, this hinders our ability to obtain detailed 3D annotations for the generated images or to craft instances with specific poses and distances. In this paper, we propose 3D Diffusion Style Transfer (3D-DST), which incorporates 3D geometry control into diffusion models. Our method exploits ControlNet, which extends diffusion models by using visual prompts in addition to text prompts. We generate images of the 3D objects taken from 3D shape repositories (e.g., ShapeNet and Objaverse), render them from a variety of poses and viewing directions, compute the edge maps of the rendered images, and use these edge maps as visual prompts to generate realistic images. With explicit 3D geometry control, we can easily change the 3D structures of the objects in the generated images and obtain ground-truth 3D annotations automatically. This allows us to improve a wide range of vision tasks, e.g., classification and 3D pose estimation, in both in-distribution (ID) and out-of-distribution (OOD) settings. We demonstrate the effectiveness of our method through extensive experiments on ImageNet-100/200, ImageNet-R, PASCAL3D+, ObjectNet3D, and OOD-CV. The results show that our method significantly outperforms existing methods, e.g., 3.8 percentage points on ImageNet-100 using DeiT-B.
4/5/2024
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick
0
0
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
6/26/2024
🤿
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
Xiyi Chen, Marko Mihajlovic, Shaofei Wang, Sergey Prokudin, Siyu Tang
0
0
Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multi-view-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks. The code for our project is publicly available.
4/3/2024
🎲
Farm3D: Learning Articulated 3D Animals by Distilling 2D Diffusion
Tomas Jakab, Ruining Li, Shangzhe Wu, Christian Rupprecht, Andrea Vedaldi
0
0
We present Farm3D, a method for learning category-specific 3D reconstructors for articulated objects, relying solely on free virtual supervision from a pre-trained 2D diffusion-based image generator. Recent approaches can learn a monocular network that predicts the 3D shape, albedo, illumination, and viewpoint of any object occurrence, given a collection of single-view images of an object category. However, these approaches heavily rely on manually curated clean training data, which are expensive to obtain. We propose a framework that uses an image generator, such as Stable Diffusion, to generate synthetic training data that are sufficiently clean and do not require further manual curation, enabling the learning of such a reconstruction network from scratch. Additionally, we incorporate the diffusion model as a score to enhance the learning process. The idea involves randomizing certain aspects of the reconstruction, such as viewpoint and illumination, generating virtual views of the reconstructed 3D object, and allowing the 2D network to assess the quality of the resulting image, thus providing feedback to the reconstructor. Unlike work based on distillation, which produces a single 3D asset for each textual prompt, our approach yields a monocular reconstruction network capable of outputting a controllable 3D asset from any given image, whether real or generated, in a single forward pass in a matter of seconds. Our network can be used for analysis, including monocular reconstruction, or for synthesis, generating articulated assets for real-time applications such as video games.
5/15/2024