Generating Synthetic Health Sensor Data for Privacy-Preserving Wearable Stress Detection
2401.13327
0
0
📊
Abstract
Smartwatch health sensor data are increasingly utilized in smart health applications and patient monitoring, including stress detection. However, such medical data often comprise sensitive personal information and are resource-intensive to acquire for research purposes. In response to this challenge, we introduce the privacy-aware synthetization of multi-sensor smartwatch health readings related to moments of stress, employing Generative Adversarial Networks (GANs) and Differential Privacy (DP) safeguards. Our method not only protects patient information but also enhances data availability for research. To ensure its usefulness, we test synthetic data from multiple GANs and employ different data enhancement strategies on an actual stress detection task. Our GAN-based augmentation methods demonstrate significant improvements in model performance, with private DP training scenarios observing an 11.90-15.48% increase in F1-score, while non-private training scenarios still see a 0.45% boost. These results underline the potential of differentially private synthetic data in optimizing utility-privacy trade-offs, especially with the limited availability of real training samples. Through rigorous quality assessments, we confirm the integrity and plausibility of our synthetic data, which, however, are significantly impacted when increasing privacy requirements.
Create account to get full access
Overview
- Smartwatch health data are increasingly used in smart health applications and patient monitoring, including stress detection
- However, this data often contains sensitive personal information and is resource-intensive to acquire for research
- This paper introduces a method to generate synthetic smartwatch health data related to moments of stress, using Generative Adversarial Networks (GANs) and Differential Privacy (DP) safeguards
- This approach protects patient information while enhancing data availability for research
- The synthetic data is tested on a stress detection task, demonstrating significant improvements in model performance
Plain English Explanation
Smartwatches are becoming more common, and the health data they collect is valuable for developing smart health applications and monitoring patients, such as detecting stress. However, this health data is often very personal and sensitive, and it can be challenging for researchers to get access to enough real data to work with.
To address this challenge, the researchers in this paper have created a way to generate synthetic, or fake, smartwatch health data related to stress. They use a type of artificial intelligence called Generative Adversarial Networks (GANs) to create this synthetic data, along with a technique called Differential Privacy (DP) to help protect the privacy of the original data.
The benefit of this approach is that it allows researchers to have access to more data for developing their applications, without compromising the privacy of the real patients. The researchers tested the synthetic data on a stress detection task and found that it significantly improved the performance of the stress detection models, even when using the private, DP-protected data.
Overall, this research shows the potential of using synthetic, privacy-protected data to advance the development of smart health applications, without the barriers of acquiring sensitive real-world data.
Technical Explanation
The researchers in this paper address the challenge of accessing sensitive smartwatch health data for research purposes by introducing a method to generate synthetic data related to stress detection. They employ Generative Adversarial Networks (GANs) and Differential Privacy (DP) safeguards to protect patient privacy while enhancing data availability.
The GAN-based data augmentation approach is tested on an actual stress detection task, evaluating the utility of the synthetic data. The results demonstrate significant improvements in model performance, with private DP training scenarios observing an 11.90-15.48% increase in F1-score, and non-private training scenarios still seeing a 0.45% boost.
These findings highlight the potential of differentially private synthetic data in optimizing the trade-off between utility and privacy, particularly when real training samples are limited. The researchers also conduct rigorous quality assessments to confirm the integrity and plausibility of the synthetic data, though they note that data quality is impacted when increasing privacy requirements.
The paper also discusses the application of differential privacy in federated learning for mental health and methods for privacy-preserving statistical data generation, providing relevant context for the research.
Critical Analysis
The researchers in this paper have made a compelling case for the use of synthetic, privacy-protected data to advance smart health applications, particularly in the context of stress detection. The GAN-based data augmentation approach, combined with Differential Privacy safeguards, represents a promising solution to the challenge of accessing sensitive health data for research.
However, the paper does acknowledge that as privacy requirements are increased, the quality of the synthetic data is impacted. This trade-off between data utility and privacy is a fundamental challenge in this domain, and the researchers do not fully address how to best balance these competing priorities.
Additionally, the paper does not delve into potential limitations or unintended consequences of this approach. For example, there may be concerns about the trustworthiness of synthetic data, or the risk of such data being misused or misinterpreted. The researchers could have provided a more comprehensive discussion of the potential risks and limitations of their approach.
Overall, the research presented in this paper is a valuable contribution to the field, demonstrating the potential of privacy-preserving synthetic data generation. However, further exploration of the nuances and potential drawbacks of this approach would strengthen the analysis and help readers form a more well-rounded understanding of the implications.
Conclusion
This paper introduces a novel method for generating synthetic smartwatch health data related to stress, using Generative Adversarial Networks (GANs) and Differential Privacy (DP) safeguards. The researchers demonstrate that this approach can significantly improve the performance of stress detection models, while also protecting the privacy of the original patient data.
The findings highlight the potential of differentially private synthetic data in optimizing the trade-off between utility and privacy, particularly when real training samples are limited. This research represents an important step forward in addressing the challenge of accessing sensitive health data for smart health applications and patient monitoring.
As the use of smartwatch and other wearable health data continues to grow, this work provides a valuable framework for developing privacy-preserving solutions that can unlock the full potential of these emerging technologies to improve healthcare outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Differentially Private Synthetic Data with Private Density Estimation
Nikolija Bojkovic, Po-Ling Loh
0
0
The need to analyze sensitive data, such as medical records or financial data, has created a critical research challenge in recent years. In this paper, we adopt the framework of differential privacy, and explore mechanisms for generating an entire dataset which accurately captures characteristics of the original data. We build upon the work of Boedihardjo et al, which laid the foundations for a new optimization-based algorithm for generating private synthetic data. Importantly, we adapt their algorithm by replacing a uniform sampling step with a private distribution estimator; this allows us to obtain better computational guarantees for discrete distributions, and develop a novel algorithm suitable for continuous distributions. We also explore applications of our work to several statistical tasks.
5/9/2024

Bt-GAN: Generating Fair Synthetic Healthdata via Bias-transforming Generative Adversarial Networks
Resmi Ramachandranpillai, Md Fahim Sikder, David Bergstrom, Fredrik Heintz
0
0
Synthetic data generation offers a promising solution to enhance the usefulness of Electronic Healthcare Records (EHR) by generating realistic de-identified data. However, the existing literature primarily focuses on the quality of synthetic health data, neglecting the crucial aspect of fairness in downstream predictions. Consequently, models trained on synthetic EHR have faced criticism for producing biased outcomes in target tasks. These biases can arise from either spurious correlations between features or the failure of models to accurately represent sub-groups. To address these concerns, we present Bias-transforming Generative Adversarial Networks (Bt-GAN), a GAN-based synthetic data generator specifically designed for the healthcare domain. In order to tackle spurious correlations (i), we propose an information-constrained Data Generation Process that enables the generator to learn a fair deterministic transformation based on a well-defined notion of algorithmic fairness. To overcome the challenge of capturing exact sub-group representations (ii), we incentivize the generator to preserve sub-group densities through score-based weighted sampling. This approach compels the generator to learn from underrepresented regions of the data manifold. We conduct extensive experiments using the MIMIC-III database. Our results demonstrate that Bt-GAN achieves SOTA accuracy while significantly improving fairness and minimizing bias amplification. We also perform an in-depth explainability analysis to provide additional evidence supporting the validity of our study. In conclusion, our research introduces a novel and professional approach to addressing the limitations of synthetic data generation in the healthcare domain. By incorporating fairness considerations and leveraging advanced techniques such as GANs, we pave the way for more reliable and unbiased predictions in healthcare applications.
4/29/2024
🔄
Differential Private Federated Transfer Learning for Mental Health Monitoring in Everyday Settings: A Case Study on Stress Detection
Ziyu Wang, Zhongqi Yang, Iman Azimi, Amir M. Rahmani
0
0
Mental health conditions, prevalent across various demographics, necessitate efficient monitoring to mitigate their adverse impacts on life quality. The surge in data-driven methodologies for mental health monitoring has underscored the importance of privacy-preserving techniques in handling sensitive health data. Despite strides in federated learning for mental health monitoring, existing approaches struggle with vulnerabilities to certain cyber-attacks and data insufficiency in real-world applications. In this paper, we introduce a differential private federated transfer learning framework for mental health monitoring to enhance data privacy and enrich data sufficiency. To accomplish this, we integrate federated learning with two pivotal elements: (1) differential privacy, achieved by introducing noise into the updates, and (2) transfer learning, employing a pre-trained universal model to adeptly address issues of data imbalance and insufficiency. We evaluate the framework by a case study on stress detection, employing a dataset of physiological and contextual data from a longitudinal study. Our finding show that the proposed approach can attain a 10% boost in accuracy and a 21% enhancement in recall, while ensuring privacy protection.
4/30/2024
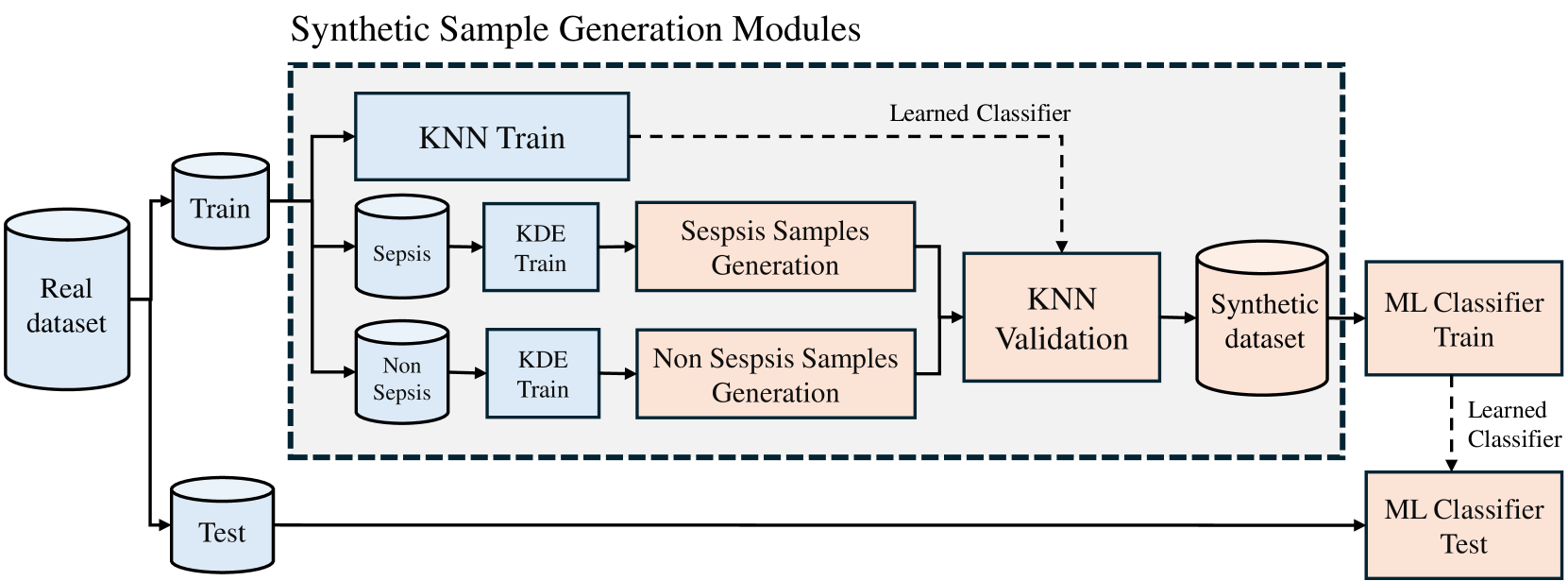
Privacy-Preserving Statistical Data Generation: Application to Sepsis Detection
Eric Macias-Fassio, Aythami Morales, Cristina Pruenza, Julian Fierrez
0
0
The biomedical field is among the sectors most impacted by the increasing regulation of Artificial Intelligence (AI) and data protection legislation, given the sensitivity of patient information. However, the rise of synthetic data generation methods offers a promising opportunity for data-driven technologies. In this study, we propose a statistical approach for synthetic data generation applicable in classification problems. We assess the utility and privacy implications of synthetic data generated by Kernel Density Estimator and K-Nearest Neighbors sampling (KDE-KNN) within a real-world context, specifically focusing on its application in sepsis detection. The detection of sepsis is a critical challenge in clinical practice due to its rapid progression and potentially life-threatening consequences. Moreover, we emphasize the benefits of KDE-KNN compared to current synthetic data generation methodologies. Additionally, our study examines the effects of incorporating synthetic data into model training procedures. This investigation provides valuable insights into the effectiveness of synthetic data generation techniques in mitigating regulatory constraints within the biomedical field.
4/26/2024