Privacy-Preserving Statistical Data Generation: Application to Sepsis Detection
2404.16638
0
0
Abstract
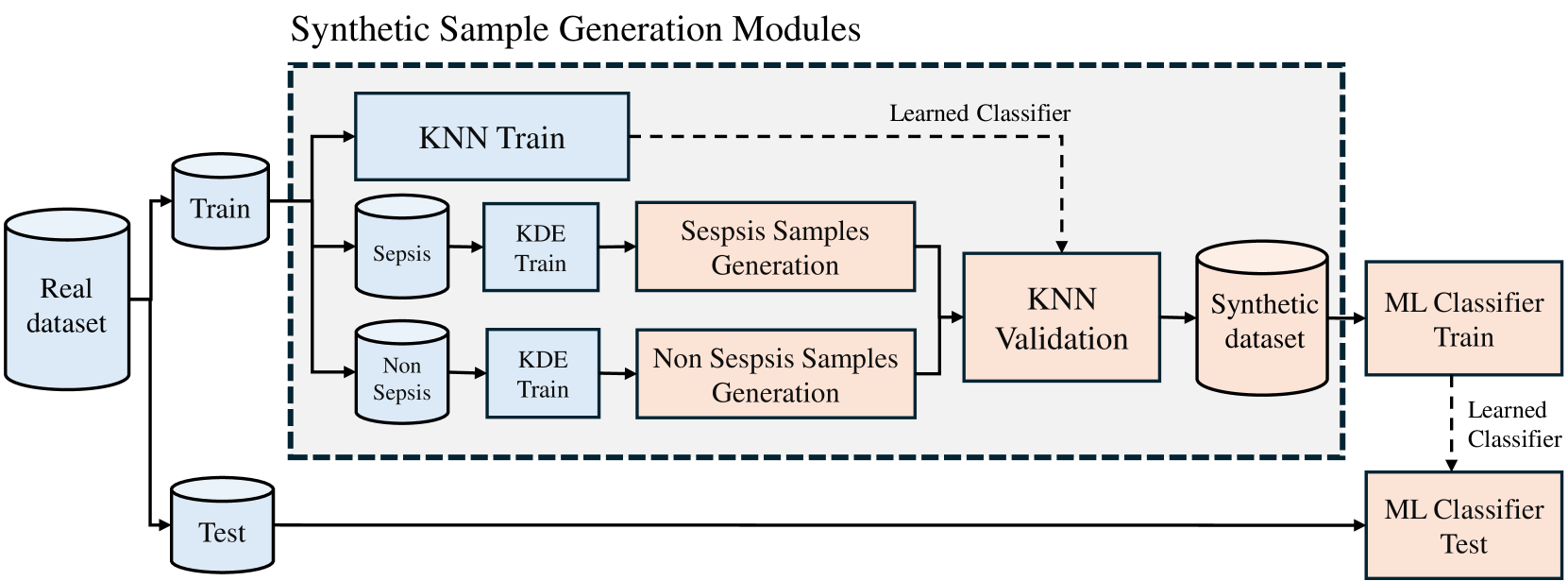
The biomedical field is among the sectors most impacted by the increasing regulation of Artificial Intelligence (AI) and data protection legislation, given the sensitivity of patient information. However, the rise of synthetic data generation methods offers a promising opportunity for data-driven technologies. In this study, we propose a statistical approach for synthetic data generation applicable in classification problems. We assess the utility and privacy implications of synthetic data generated by Kernel Density Estimator and K-Nearest Neighbors sampling (KDE-KNN) within a real-world context, specifically focusing on its application in sepsis detection. The detection of sepsis is a critical challenge in clinical practice due to its rapid progression and potentially life-threatening consequences. Moreover, we emphasize the benefits of KDE-KNN compared to current synthetic data generation methodologies. Additionally, our study examines the effects of incorporating synthetic data into model training procedures. This investigation provides valuable insights into the effectiveness of synthetic data generation techniques in mitigating regulatory constraints within the biomedical field.
Create account to get full access
Overview
- This paper presents a method for generating synthetic healthcare data that preserves the statistical properties of the original data while protecting patient privacy.
- The authors apply this approach to the task of sepsis detection, training machine learning models on the synthetic data and evaluating their performance.
- The research is supported by the Instituto de Ingeniería del Conocimiento, Hospital Universitario Son Llátzer, the Fundación Instituto de Investigación Sanitaria Illes Balears (Spain), and BBforTAI (PID2021-127641OB-I00 MICINN/FEDER).
Plain English Explanation
The paper discusses a way to create artificial healthcare data that has the same overall statistical properties as real patient data, but without revealing any private or sensitive information about the actual patients. This is important because researchers often need access to healthcare data to develop better medical treatments and technologies, like predictive models for sepsis. However, using real patient data raises privacy concerns.
The authors' approach generates synthetic data that maintains the same patterns and trends as the original data, but with completely fictional patient identities. This allows researchers to work with realistic-looking data without compromising anyone's privacy. The researchers then test this synthetic data by using it to train machine learning models for sepsis detection, and evaluate how well the models perform compared to those trained on the original data.
The goal is to provide a way for healthcare researchers to access the data they need for developing new medical AI systems and predictive analytics, while still protecting the privacy of the patients whose information was originally collected.
Technical Explanation
The paper proposes a differentially private data generation approach that can create synthetic healthcare data with preserved statistical properties. The authors use a generative adversarial network (GAN) architecture, where one neural network (the generator) learns to produce realistic-looking synthetic data, while another network (the discriminator) tries to distinguish the synthetic data from the real data.
By training the GAN under differential privacy constraints, the authors ensure that the synthetic data does not reveal information about any individual patient, while still maintaining the overall statistical distribution and patterns present in the original dataset. The authors evaluate their approach by training sepsis detection models on the synthetic data and comparing their performance to models trained on the real data.
The results show that the synthetic data can be used to train machine learning models that achieve comparable performance to those trained on the original data, while providing strong privacy guarantees. This suggests that the proposed approach can be a valuable tool for healthcare researchers who need access to realistic data without compromising patient privacy.
Critical Analysis
The paper provides a promising approach for generating privacy-preserving synthetic healthcare data, but there are a few caveats to consider. First, the authors acknowledge that their method may not fully capture all the complex relationships and dependencies present in the original data, which could impact the effectiveness of the sepsis detection models trained on the synthetic data.
Additionally, the authors only evaluate their approach on a single healthcare dataset related to sepsis, so it's unclear how well the method would generalize to other types of healthcare data and tasks. Further research is needed to assess the consistency of clinicians' evaluations of sepsis predictability when using synthetic data.
The authors also do not provide a comprehensive evaluation framework for assessing the quality of synthetic data generation models, which could be a valuable contribution to the field. Developing more robust evaluation metrics and benchmarks for privacy-preserving synthetic data generation would help ensure the reliability and trustworthiness of these approaches.
Conclusion
Overall, this paper presents a promising approach for generating synthetic healthcare data that preserves the statistical properties of the original data while protecting patient privacy. The authors demonstrate the effectiveness of their method by training sepsis detection models on the synthetic data and achieving comparable performance to models trained on the real data.
This work has important implications for the development of medical AI systems and predictive analytics in healthcare, as it provides a way for researchers to access the data they need while still protecting patient privacy. Further research is needed to address the identified limitations and ensure the reliability and generalizability of this approach, but this paper represents an important step forward in the field of privacy-preserving data generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Differentially Private Synthetic Data with Private Density Estimation
Nikolija Bojkovic, Po-Ling Loh
0
0
The need to analyze sensitive data, such as medical records or financial data, has created a critical research challenge in recent years. In this paper, we adopt the framework of differential privacy, and explore mechanisms for generating an entire dataset which accurately captures characteristics of the original data. We build upon the work of Boedihardjo et al, which laid the foundations for a new optimization-based algorithm for generating private synthetic data. Importantly, we adapt their algorithm by replacing a uniform sampling step with a private distribution estimator; this allows us to obtain better computational guarantees for discrete distributions, and develop a novel algorithm suitable for continuous distributions. We also explore applications of our work to several statistical tasks.
5/9/2024
📊
Generating Synthetic Health Sensor Data for Privacy-Preserving Wearable Stress Detection
Lucas Lange, Nils Wenzlitschke, Erhard Rahm
0
0
Smartwatch health sensor data are increasingly utilized in smart health applications and patient monitoring, including stress detection. However, such medical data often comprise sensitive personal information and are resource-intensive to acquire for research purposes. In response to this challenge, we introduce the privacy-aware synthetization of multi-sensor smartwatch health readings related to moments of stress, employing Generative Adversarial Networks (GANs) and Differential Privacy (DP) safeguards. Our method not only protects patient information but also enhances data availability for research. To ensure its usefulness, we test synthetic data from multiple GANs and employ different data enhancement strategies on an actual stress detection task. Our GAN-based augmentation methods demonstrate significant improvements in model performance, with private DP training scenarios observing an 11.90-15.48% increase in F1-score, while non-private training scenarios still see a 0.45% boost. These results underline the potential of differentially private synthetic data in optimizing utility-privacy trade-offs, especially with the limited availability of real training samples. Through rigorous quality assessments, we confirm the integrity and plausibility of our synthetic data, which, however, are significantly impacted when increasing privacy requirements.
5/15/2024

KiNETGAN: Enabling Distributed Network Intrusion Detection through Knowledge-Infused Synthetic Data Generation
Anantaa Kotal, Brandon Luton, Anupam Joshi
0
0
In the realm of IoT/CPS systems connected over mobile networks, traditional intrusion detection methods analyze network traffic across multiple devices using anomaly detection techniques to flag potential security threats. However, these methods face significant privacy challenges, particularly with deep packet inspection and network communication analysis. This type of monitoring is highly intrusive, as it involves examining the content of data packets, which can include personal and sensitive information. Such data scrutiny is often governed by stringent laws and regulations, especially in environments like smart homes where data privacy is paramount. Synthetic data offers a promising solution by mimicking real network behavior without revealing sensitive details. Generative models such as Generative Adversarial Networks (GANs) can produce synthetic data, but they often struggle to generate realistic data in specialized domains like network activity. This limitation stems from insufficient training data, which impedes the model's ability to grasp the domain's rules and constraints adequately. Moreover, the scarcity of training data exacerbates the problem of class imbalance in intrusion detection methods. To address these challenges, we propose a Privacy-Driven framework that utilizes a knowledge-infused Generative Adversarial Network for generating synthetic network activity data (KiNETGAN). This approach enhances the resilience of distributed intrusion detection while addressing privacy concerns. Our Knowledge Guided GAN produces realistic representations of network activity, validated through rigorous experimentation. We demonstrate that KiNETGAN maintains minimal accuracy loss in downstream tasks, effectively balancing data privacy and utility.
5/28/2024
Investigating potential causes of Sepsis with Bayesian network structure learning
Bruno Petrungaro, Neville K. Kitson, Anthony C. Constantinou
0
0
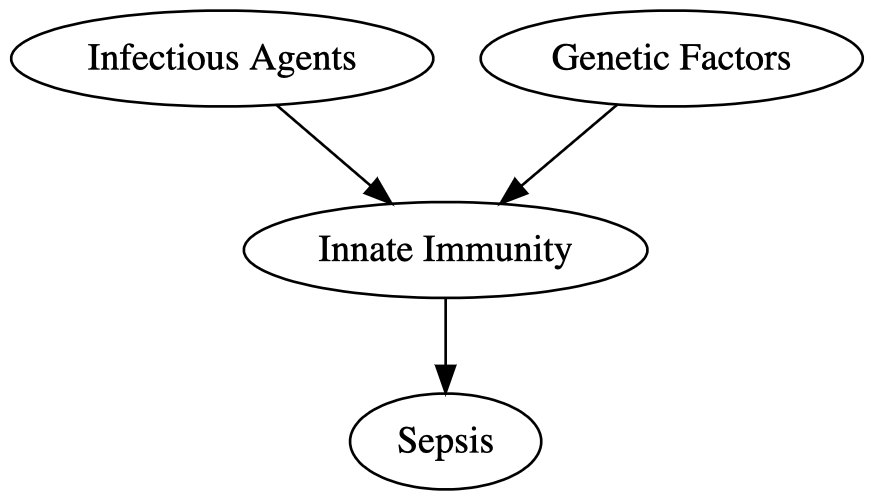
Sepsis is a life-threatening and serious global health issue. This study combines knowledge with available hospital data to investigate the potential causes of Sepsis that can be affected by policy decisions. We investigate the underlying causal structure of this problem by combining clinical expertise with score-based, constraint-based, and hybrid structure learning algorithms. A novel approach to model averaging and knowledge-based constraints was implemented to arrive at a consensus structure for causal inference. The structure learning process highlighted the importance of exploring data-driven approaches alongside clinical expertise. This includes discovering unexpected, although reasonable, relationships from a clinical perspective. Hypothetical interventions on Chronic Obstructive Pulmonary Disease, Alcohol dependence, and Diabetes suggest that the presence of any of these risk factors in patients increases the likelihood of Sepsis. This finding, alongside measuring the effect of these risk factors on Sepsis, has potential policy implications. Recognising the importance of prediction in improving Sepsis related health outcomes, the model built is also assessed in its ability to predict Sepsis. The predictions generated by the consensus model were assessed for their accuracy, sensitivity, and specificity. These three indicators all had results around 70%, and the AUC was 80%, which means the causal structure of the model is reasonably accurate given that the models were trained on data available for commissioning purposes only.
6/14/2024