Generative modeling of density regression through tree flows
2406.05260
0
0
Abstract
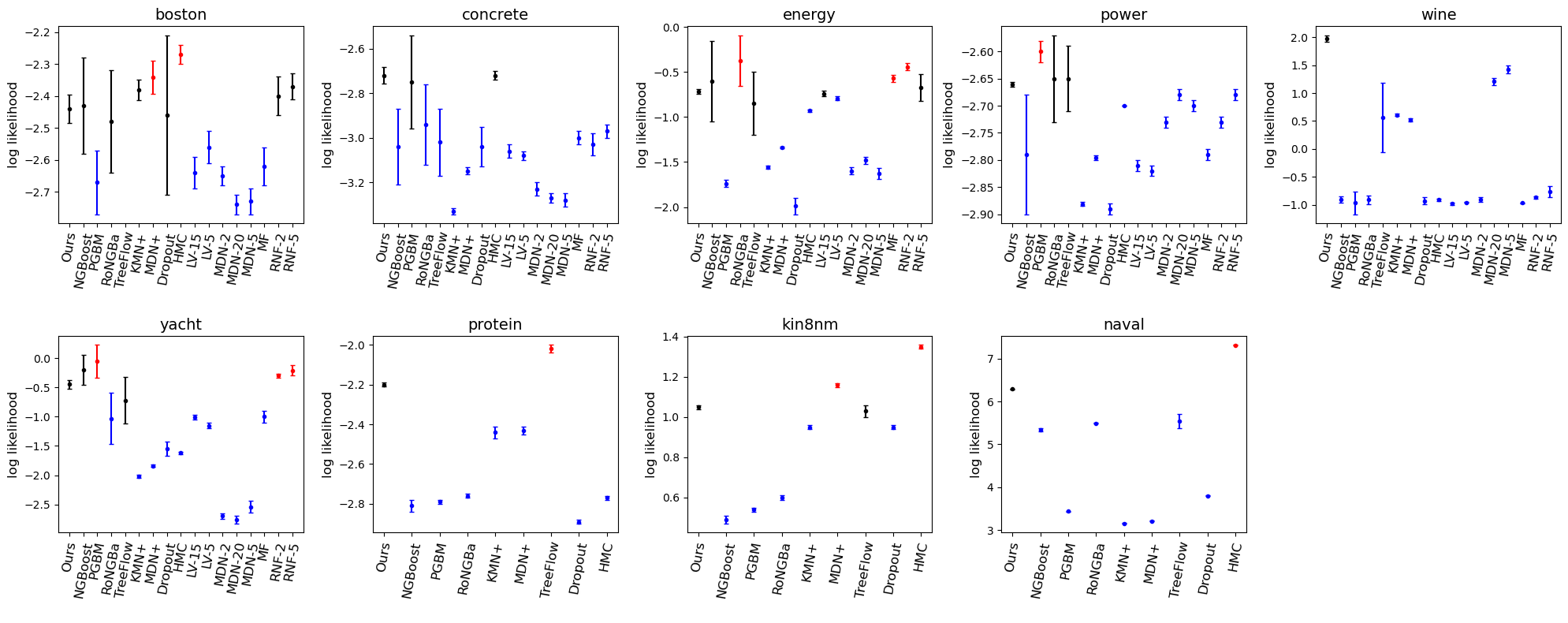
A common objective in the analysis of tabular data is estimating the conditional distribution (in contrast to only producing predictions) of a set of outcome variables given a set of covariates, which is sometimes referred to as the density regression problem. Beyond estimation on the conditional distribution, the generative ability of drawing synthetic samples from the learned conditional distribution is also desired as it further widens the range of applications. We propose a flow-based generative model tailored for the density regression task on tabular data. Our flow applies a sequence of tree-based piecewise-linear transforms on initial uniform noise to eventually generate samples from complex conditional densities of (univariate or multivariate) outcomes given the covariates and allows efficient analytical evaluation of the fitted conditional density on any point in the sample space. We introduce a training algorithm for fitting the tree-based transforms using a divide-and-conquer strategy that transforms maximum likelihood training of the tree-flow into training a collection of binary classifiers--one at each tree split--under cross-entropy loss. We assess the performance of our method under out-of-sample likelihood evaluation and compare it with a variety of state-of-the-art conditional density learners on a range of simulated and real benchmark tabular datasets. Our method consistently achieves comparable or superior performance at a fraction of the training and sampling budget. Finally, we demonstrate the utility of our method's generative ability through an application to generating synthetic longitudinal microbiome compositional data based on training our flow on a publicly available microbiome study.
Create account to get full access
Overview
- This paper introduces a new generative modeling approach called "Generative modeling of density regression through tree flows" that combines the strengths of flow-based models and tree-based models.
- The proposed method, called "Tree Flows", learns a conditional distribution by using a series of tree-based transforms to map the input data to a simple base distribution.
- The authors demonstrate the effectiveness of Tree Flows on several density estimation and conditional density modeling tasks, showing improved performance compared to existing approaches.
Plain English Explanation
Generative models are a type of machine learning that can create new data samples that are similar to the training data. This paper presents a new way to build generative models that combines the advantages of two popular approaches: flow-based models and tree-based models.
Flow-based models work by learning a series of transformations that convert the training data into a simple base distribution, like a normal distribution. Tree-based models use decision trees to partition the input space in a hierarchical way.
The key idea in this paper is to use tree-based transforms instead of the typical flow-based transforms. This results in a model called "Tree Flows" that can efficiently learn complex conditional distributions, such as the relationship between some input data and a corresponding target variable.
The authors show that Tree Flows outperform existing approaches on several benchmarks for density estimation and conditional density modeling. This suggests Tree Flows could be a powerful tool for tasks like generating new data samples or predicting the probability distribution of an outcome variable given some inputs.
Technical Explanation
The core of the Tree Flows model is a series of learnable tree-based transforms that map the input data to a simple base distribution. Each tree transform partitions the input space hierarchically, with each split in the tree representing a nonlinear transformation.
By composing multiple tree transforms, the model can learn highly expressive conditional distributions. The authors derive the required change-of-variables formula and show how to efficiently optimize the model parameters end-to-end using gradient-based methods.
The authors evaluate Tree Flows on several density estimation and conditional density modeling tasks, including fitting multimodal distributions, modeling the relationship between image pixels and segmentation masks, and predicting the distribution of housing prices given home features. Across these benchmarks, Tree Flows demonstrated improved performance compared to baseline methods like Generative Assignment Flows, Fisher Flows, and Hierarchic Flows.
Critical Analysis
The authors provide a thorough theoretical and empirical analysis of the Tree Flows model. They carefully derive the required mathematical formulas, discuss the computational complexity, and validate the approach on a diverse set of benchmarks.
One potential limitation is the reliance on tree-based transforms, which may not be as flexible as the more general transforms used in typical flow-based models. The authors acknowledge this and suggest investigating hybrid approaches that combine tree-based and flow-based components.
Additionally, the authors only evaluate Tree Flows on relatively low-dimensional problems. It would be interesting to see how the model scales to high-dimensional data, such as natural images, where the hierarchical inductive bias of the tree-based transforms may be particularly beneficial.
Overall, this paper presents a compelling new direction for generative modeling that blends the strengths of decision trees and flow-based models. The results suggest Tree Flows could be a valuable tool for researchers and practitioners working on density estimation, conditional modeling, and related tasks.
Conclusion
This paper introduces a novel generative modeling approach called "Tree Flows" that leverages tree-based transforms to learn expressive conditional distributions. The authors demonstrate the effectiveness of Tree Flows on several benchmarks, showing improved performance compared to existing methods.
The key innovation is the use of learnable tree-based transforms, which allows the model to capture complex nonlinearities in a computationally efficient manner. This work represents an interesting step towards more flexible and powerful generative models, with potential applications in areas like data synthesis, prediction, and anomaly detection.
As the field of generative modeling continues to advance, approaches like Tree Flows that combine the strengths of different model families may become increasingly important for tackling diverse real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
BUFF: Boosted Decision Tree based Ultra-Fast Flow matching
Cheng Jiang, Sitian Qian, Huilin Qu
0
0
Tabular data stands out as one of the most frequently encountered types in high energy physics. Unlike commonly homogeneous data such as pixelated images, simulating high-dimensional tabular data and accurately capturing their correlations are often quite challenging, even with the most advanced architectures. Based on the findings that tree-based models surpass the performance of deep learning models for tasks specific to tabular data, we adopt the very recent generative modeling class named conditional flow matching and employ different techniques to integrate the usage of Gradient Boosted Trees. The performances are evaluated for various tasks on different analysis level with several public datasets. We demonstrate the training and inference time of most high-level simulation tasks can achieve speedup by orders of magnitude. The application can be extended to low-level feature simulation and conditioned generations with competitive performance.
4/30/2024
💬
Generative Modeling with Flow-Guided Density Ratio Learning
Alvin Heng, Abdul Fatir Ansari, Harold Soh
0
0
We present Flow-Guided Density Ratio Learning (FDRL), a simple and scalable approach to generative modeling which builds on the stale (time-independent) approximation of the gradient flow of entropy-regularized f-divergences introduced in recent work. Specifically, the intractable time-dependent density ratio is approximated by a stale estimator given by a GAN discriminator. This is sufficient in the case of sample refinement, where the source and target distributions of the flow are close to each other. However, this assumption is invalid for generation and a naive application of the stale estimator fails due to the large chasm between the two distributions. FDRL proposes to train a density ratio estimator such that it learns from progressively improving samples during the training process. We show that this simple method alleviates the density chasm problem, allowing FDRL to generate images of dimensions as high as $128times128$, as well as outperform existing gradient flow baselines on quantitative benchmarks. We also show the flexibility of FDRL with two use cases. First, unconditional FDRL can be easily composed with external classifiers to perform class-conditional generation. Second, FDRL can be directly applied to unpaired image-to-image translation with no modifications needed to the framework. Our code is publicly available at ttps://github.com/clear-nus/fdrl.
6/6/2024
Generative Assignment Flows for Representing and Learning Joint Distributions of Discrete Data
Bastian Boll, Daniel Gonzalez-Alvarado, Stefania Petra, Christoph Schnorr
0
0
We introduce a novel generative model for the representation of joint probability distributions of a possibly large number of discrete random variables. The approach uses measure transport by randomized assignment flows on the statistical submanifold of factorizing distributions, which also enables to sample efficiently from the target distribution and to assess the likelihood of unseen data points. The embedding of the flow via the Segre map in the meta-simplex of all discrete joint distributions ensures that any target distribution can be represented in principle, whose complexity in practice only depends on the parametrization of the affinity function of the dynamical assignment flow system. Our model can be trained in a simulation-free manner without integration by conditional Riemannian flow matching, using the training data encoded as geodesics in closed-form with respect to the e-connection of information geometry. By projecting high-dimensional flow matching in the meta-simplex of joint distributions to the submanifold of factorizing distributions, our approach has strong motivation from first principles of modeling coupled discrete variables. Numerical experiments devoted to distributions of structured image labelings demonstrate the applicability to large-scale problems, which may include discrete distributions in other application areas. Performance measures show that our approach scales better with the increasing number of classes than recent related work.
6/10/2024
📊
Fisher Flow Matching for Generative Modeling over Discrete Data
Oscar Davis, Samuel Kessler, Mircea Petrache, .Ismail .Ilkan Ceylan, Michael Bronstein, Avishek Joey Bose
0
0
Generative modeling over discrete data has recently seen numerous success stories, with applications spanning language modeling, biological sequence design, and graph-structured molecular data. The predominant generative modeling paradigm for discrete data is still autoregressive, with more recent alternatives based on diffusion or flow-matching falling short of their impressive performance in continuous data settings, such as image or video generation. In this work, we introduce Fisher-Flow, a novel flow-matching model for discrete data. Fisher-Flow takes a manifestly geometric perspective by considering categorical distributions over discrete data as points residing on a statistical manifold equipped with its natural Riemannian metric: the $textit{Fisher-Rao metric}$. As a result, we demonstrate discrete data itself can be continuously reparameterised to points on the positive orthant of the $d$-hypersphere $mathbb{S}^d_+$, which allows us to define flows that map any source distribution to target in a principled manner by transporting mass along (closed-form) geodesics of $mathbb{S}^d_+$. Furthermore, the learned flows in Fisher-Flow can be further bootstrapped by leveraging Riemannian optimal transport leading to improved training dynamics. We prove that the gradient flow induced by Fisher-Flow is optimal in reducing the forward KL divergence. We evaluate Fisher-Flow on an array of synthetic and diverse real-world benchmarks, including designing DNA Promoter, and DNA Enhancer sequences. Empirically, we find that Fisher-Flow improves over prior diffusion and flow-matching models on these benchmarks.
5/30/2024