Geneverse: A collection of Open-source Multimodal Large Language Models for Genomic and Proteomic Research

0

Sign in to get full access
Overview
- Geneverse is a collection of open-source multimodal large language models (LLMs) designed for genomic and proteomic research.
- These models are trained on a diverse range of biomedical data, including DNA/RNA sequences, protein structures, and scientific literature.
- The goal of Geneverse is to enable researchers to leverage the power of LLMs for tasks such as gene annotation, protein engineering, and drug discovery.
Plain English Explanation
Geneverse is a set of advanced AI models that have been specifically trained to work with biological data, like DNA, RNA, and protein information. These models are based on the latest language AI technology, known as large language models (LLMs), which have shown incredible capabilities in processing and generating human-like text.
The key idea behind Geneverse is to take these powerful LLMs and adapt them to be useful for scientific research in fields like genomics and proteomics. Genomics is the study of genes and how they work, while proteomics focuses on understanding proteins, which are the building blocks of life.
By training the LLMs on a vast collection of biological data, the Geneverse models can now "understand" the language of biology. This allows them to assist researchers in a variety of tasks, such as GenoTex - exploring and annotating genes, DocGenome - summarizing scientific literature, and VaNER - engineering new proteins with desired properties.
The hope is that these Geneverse models will empower researchers to make new discoveries and breakthroughs more efficiently, by leveraging the pattern-recognition and language-understanding abilities of advanced AI.
Technical Explanation
The Geneverse project aims to develop a collection of open-source multimodal large language models (LLMs) that can be applied to a variety of genomic and proteomic research tasks. These models are trained on a diverse corpus of biomedical data, including DNA/RNA sequences, protein structures, and scientific literature from domains such as GenTranslate, biology, and medicine.
The key innovation of Geneverse is its ability to leverage the powerful language understanding and generation capabilities of LLMs, which have shown remarkable performance on a wide range of natural language processing tasks, and adapt them to the specialized domain of bioinformatics. By pre-training the models on large amounts of relevant data, the Geneverse LLMs can capture the intricate relationships and patterns within biological sequences and scientific concepts, enabling them to assist researchers in tasks like gene annotation, protein engineering, and drug discovery.
The Geneverse collection includes models with different architectural configurations and training regimes, allowing researchers to choose the most appropriate model for their specific needs. For example, some models may be optimized for sequence-to-sequence tasks, while others excel at text generation or multimodal reasoning across different data types, as demonstrated in the DocGenome and VaNER projects.
Critical Analysis
The Geneverse project represents a promising step towards leveraging the power of LLMs for biomedical research. By providing open-access, domain-specific models, the researchers aim to democratize access to advanced AI capabilities and enable a wider range of researchers to benefit from these technologies.
However, it's important to note that the Geneverse models, like any AI system, may have inherent biases and limitations. The quality and diversity of the training data, as well as the specific model architectures and optimization techniques used, can all impact the models' performance and generalization abilities. Researchers should exercise caution when applying these models to sensitive or high-stakes applications, and carefully evaluate their outputs for potential errors or biases.
Additionally, the long-term maintenance and sustainability of the Geneverse project may pose challenges, as keeping large-scale AI models up-to-date and well-supported can be resource-intensive. The researchers should consider strategies for ensuring the continued availability and development of these models, potentially through collaborations with industry or academic partners.
Conclusion
The Geneverse project represents an exciting development in the application of large language models to the field of genomic and proteomic research. By providing open-source, multimodal AI models tailored for biomedical tasks, the researchers aim to accelerate scientific discovery and enable researchers to leverage the power of advanced AI in their work.
While the Geneverse models have the potential to significantly impact fields like GenoTex, DocGenome, and VaNER, researchers must remain vigilant in evaluating the models' outputs and understanding their limitations. Ongoing development, maintenance, and collaboration will be crucial to ensuring the long-term success and impact of the Geneverse project.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Geneverse: A collection of Open-source Multimodal Large Language Models for Genomic and Proteomic Research
Tianyu Liu, Yijia Xiao, Xiao Luo, Hua Xu, W. Jim Zheng, Hongyu Zhao
The applications of large language models (LLMs) are promising for biomedical and healthcare research. Despite the availability of open-source LLMs trained using a wide range of biomedical data, current research on the applications of LLMs to genomics and proteomics is still limited. To fill this gap, we propose a collection of finetuned LLMs and multimodal LLMs (MLLMs), known as Geneverse, for three novel tasks in genomic and proteomic research. The models in Geneverse are trained and evaluated based on domain-specific datasets, and we use advanced parameter-efficient finetuning techniques to achieve the model adaptation for tasks including the generation of descriptions for gene functions, protein function inference from its structure, and marker gene selection from spatial transcriptomic data. We demonstrate that adapted LLMs and MLLMs perform well for these tasks and may outperform closed-source large-scale models based on our evaluations focusing on both truthfulness and structural correctness. All of the training strategies and base models we used are freely accessible.
Read more6/26/2024
0
Genomic Language Models: Opportunities and Challenges
Gonzalo Benegas, Chengzhong Ye, Carlos Albors, Jianan Canal Li, Yun S. Song
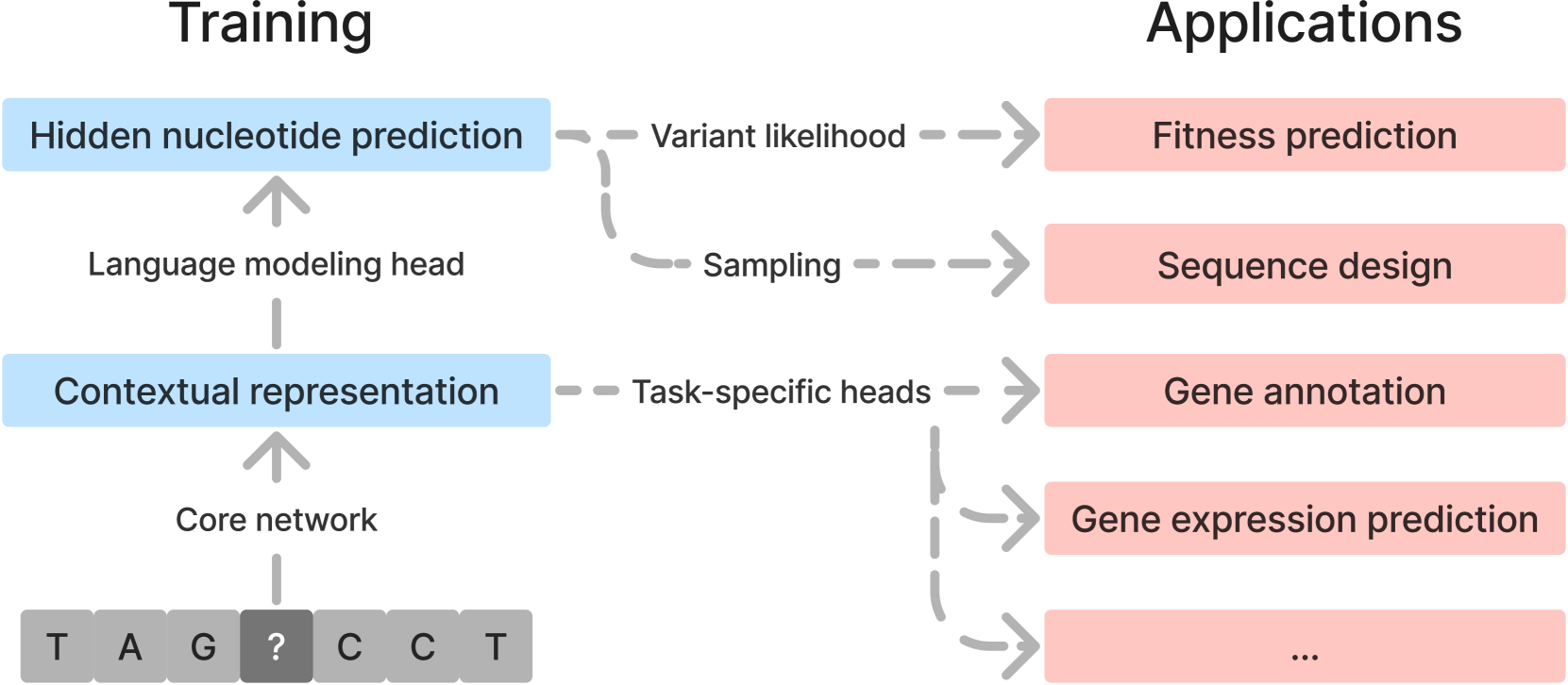
Large language models (LLMs) are having transformative impacts across a wide range of scientific fields, particularly in the biomedical sciences. Just as the goal of Natural Language Processing is to understand sequences of words, a major objective in biology is to understand biological sequences. Genomic Language Models (gLMs), which are LLMs trained on DNA sequences, have the potential to significantly advance our understanding of genomes and how DNA elements at various scales interact to give rise to complex functions. In this review, we showcase this potential by highlighting key applications of gLMs, including fitness prediction, sequence design, and transfer learning. Despite notable recent progress, however, developing effective and efficient gLMs presents numerous challenges, especially for species with large, complex genomes. We discuss major considerations for developing and evaluating gLMs.
Read more7/17/2024
💬
0
New!GP-GPT: Large Language Model for Gene-Phenotype Mapping
Yanjun Lyu, Zihao Wu, Lu Zhang, Jing Zhang, Yiwei Li, Wei Ruan, Zhengliang Liu, Xiaowei Yu, Chao Cao, Tong Chen, Minheng Chen, Yan Zhuang, Xiang Li, Rongjie Liu, Chao Huang, Wentao Li, Tianming Liu, Dajiang Zhu
Pre-trained large language models(LLMs) have attracted increasing attention in biomedical domains due to their success in natural language processing. However, the complex traits and heterogeneity of multi-sources genomics data pose significant challenges when adapting these models to the bioinformatics and biomedical field. To address these challenges, we present GP-GPT, the first specialized large language model for genetic-phenotype knowledge representation and genomics relation analysis. Our model is fine-tuned in two stages on a comprehensive corpus composed of over 3,000,000 terms in genomics, proteomics, and medical genetics, derived from multiple large-scale validated datasets and scientific publications. GP-GPT demonstrates proficiency in accurately retrieving medical genetics information and performing common genomics analysis tasks, such as genomics information retrieval and relationship determination. Comparative experiments across domain-specific tasks reveal that GP-GPT outperforms state-of-the-art LLMs, including Llama2, Llama3 and GPT-4. These results highlight GP-GPT's potential to enhance genetic disease relation research and facilitate accurate and efficient analysis in the fields of genomics and medical genetics. Our investigation demonstrated the subtle changes of bio-factor entities' representations in the GP-GPT, which suggested the opportunities for the application of LLMs to advancing gene-phenotype research.
Read more9/17/2024

0
GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
Read more5/17/2024