GenN2N: Generative NeRF2NeRF Translation
2404.02788
0
3
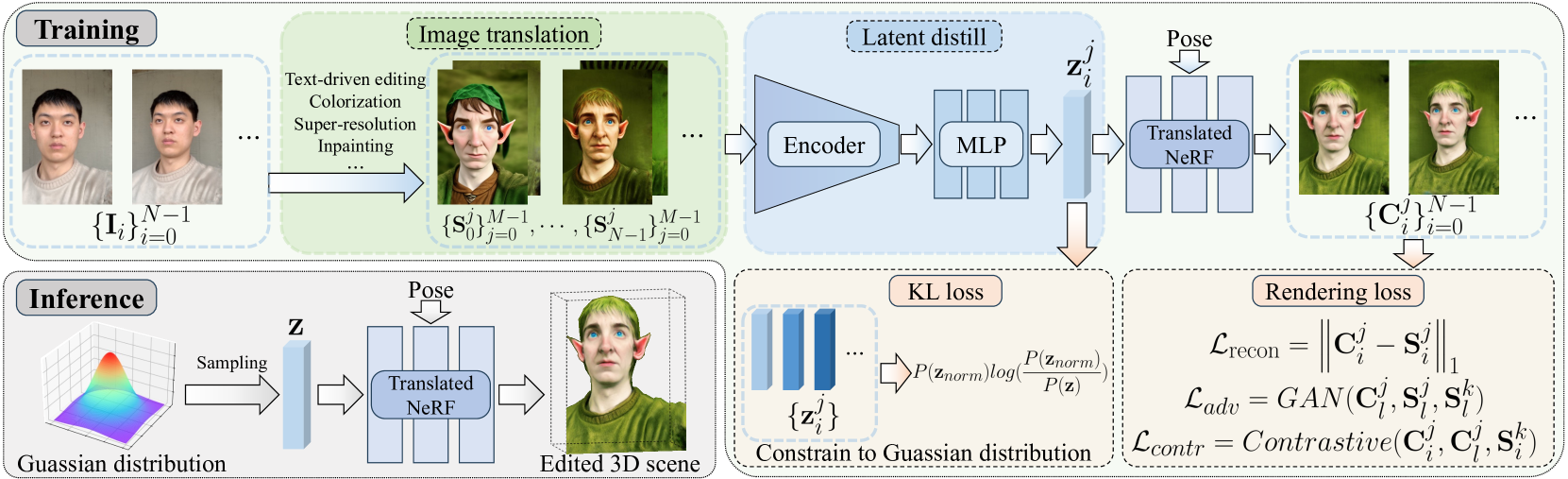
Abstract
We present GenN2N, a unified NeRF-to-NeRF translation framework for various NeRF translation tasks such as text-driven NeRF editing, colorization, super-resolution, inpainting, etc. Unlike previous methods designed for individual translation tasks with task-specific schemes, GenN2N achieves all these NeRF editing tasks by employing a plug-and-play image-to-image translator to perform editing in the 2D domain and lifting 2D edits into the 3D NeRF space. Since the 3D consistency of 2D edits may not be assured, we propose to model the distribution of the underlying 3D edits through a generative model that can cover all possible edited NeRFs. To model the distribution of 3D edited NeRFs from 2D edited images, we carefully design a VAE-GAN that encodes images while decoding NeRFs. The latent space is trained to align with a Gaussian distribution and the NeRFs are supervised through an adversarial loss on its renderings. To ensure the latent code does not depend on 2D viewpoints but truly reflects the 3D edits, we also regularize the latent code through a contrastive learning scheme. Extensive experiments on various editing tasks show GenN2N, as a universal framework, performs as well or better than task-specific specialists while possessing flexible generative power. More results on our project page: https://xiangyueliu.github.io/GenN2N/
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces GenN2N, a new technique for translating between different NeRF (Neural Radiance Field) representations.
- NeRFs are 3D scene representations that can be used for tasks like rendering, reconstruction, and animation.
- GenN2N allows converting one NeRF model into another, potentially with different architectures or training data.
- The approach could enable more flexibility and interoperability in NeRF-based applications.
Plain English Explanation
NeRFs are a powerful way to capture and represent 3D scenes using neural networks. They can generate detailed, realistic images by learning the light transport properties of a scene. However, different NeRF models may have unique architectures or be trained on different data, making it difficult to use them interchangeably.
GenN2N aims to bridge this gap by providing a way to translate between NeRF representations. Imagine you have two NeRF models of the same scene, but one was trained on lower-quality images while the other used high-quality data. GenN2N could convert the lower-quality NeRF into one that matches the higher-quality version, allowing you to take advantage of the better model without having to retrain from scratch.
This kind of flexibility could unlock new applications for NeRFs, like mixing and matching different scene representations or updating older NeRF models with new data. By making NeRFs more interoperable, GenN2N could help 3D rendering and reconstruction workflows become more efficient and accessible.
Technical Explanation
The core of GenN2N is a generative adversarial network (GAN) that learns to translate between NeRF representations. The generator network takes an input NeRF and generates a new NeRF with different characteristics, while the discriminator network tries to distinguish real NeRFs from the generated ones.
To train this GAN, the authors leverage a dataset of NeRFs representing the same scene but with varied properties, such as resolution, camera viewpoints, and scene content. The generator learns to map between these diverse NeRF representations, guided by specialized loss functions that enforce semantic and perceptual similarity.
Experiments show that GenN2N can effectively translate NeRFs, enabling tasks like upscaling low-res NeRFs, adjusting camera viewpoints, and transferring scene details between models. The translated NeRFs maintain high visual fidelity and quality compared to the source, demonstrating the potential of this approach for practical NeRF applications.
Critical Analysis
The paper presents a compelling solution to the challenge of NeRF interoperability, but there are some potential limitations and areas for further research:
- The approach relies on having a diverse dataset of NeRFs for the same scenes, which may not always be available in practice. Developing techniques to work with more limited training data could broaden the applicability.
- The paper focuses on translating between NeRFs with varied properties, but it does not explore translating between fundamentally different NeRF architectures. Extending the method to handle more architectural diversity could increase its flexibility.
- While the authors demonstrate several use cases, the potential real-world impacts and practical benefits of the technology are not fully explored. Further research into specific applications and user studies could help validate the value of this approach.
Overall, GenN2N represents an important step forward in NeRF-based 3D representation, and the core ideas could inspire further developments in the field of neural scene modeling and manipulation.
Conclusion
This paper introduces GenN2N, a novel technique for translating between different NeRF representations. By leveraging generative adversarial networks, GenN2N can convert NeRFs with varied properties, such as resolution, camera viewpoints, and scene content, enabling new applications and workflows.
The ability to flexibly interchange NeRF models could significantly improve the accessibility and interoperability of 3D rendering and reconstruction technologies based on this powerful scene representation. While the current approach has some limitations, the core ideas presented in this work could lead to further advancements in neural 3D modeling and image synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DATENeRF: Depth-Aware Text-based Editing of NeRFs
Sara Rojas, Julien Philip, Kai Zhang, Sai Bi, Fujun Luan, Bernard Ghanem, Kalyan Sunkavall
0
0
Recent advancements in diffusion models have shown remarkable proficiency in editing 2D images based on text prompts. However, extending these techniques to edit scenes in Neural Radiance Fields (NeRF) is complex, as editing individual 2D frames can result in inconsistencies across multiple views. Our crucial insight is that a NeRF scene's geometry can serve as a bridge to integrate these 2D edits. Utilizing this geometry, we employ a depth-conditioned ControlNet to enhance the coherence of each 2D image modification. Moreover, we introduce an inpainting approach that leverages the depth information of NeRF scenes to distribute 2D edits across different images, ensuring robustness against errors and resampling challenges. Our results reveal that this methodology achieves more consistent, lifelike, and detailed edits than existing leading methods for text-driven NeRF scene editing.
4/9/2024
G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images
Zixiong Huang, Qi Chen, Libo Sun, Yifan Yang, Naizhou Wang, Mingkui Tan, Qi Wu
0
0
Novel view synthesis aims to generate new view images of a given view image collection. Recent attempts address this problem relying on 3D geometry priors (e.g., shapes, sizes, and positions) learned from multi-view images. However, such methods encounter the following limitations: 1) they require a set of multi-view images as training data for a specific scene (e.g., face, car or chair), which is often unavailable in many real-world scenarios; 2) they fail to extract the geometry priors from single-view images due to the lack of multi-view supervision. In this paper, we propose a Geometry-enhanced NeRF (G-NeRF), which seeks to enhance the geometry priors by a geometry-guided multi-view synthesis approach, followed by a depth-aware training. In the synthesis process, inspired that existing 3D GAN models can unconditionally synthesize high-fidelity multi-view images, we seek to adopt off-the-shelf 3D GAN models, such as EG3D, as a free source to provide geometry priors through synthesizing multi-view data. Simultaneously, to further improve the geometry quality of the synthetic data, we introduce a truncation method to effectively sample latent codes within 3D GAN models. To tackle the absence of multi-view supervision for single-view images, we design the depth-aware training approach, incorporating a depth-aware discriminator to guide geometry priors through depth maps. Experiments demonstrate the effectiveness of our method in terms of both qualitative and quantitative results.
4/12/2024
CodecNeRF: Toward Fast Encoding and Decoding, Compact, and High-quality Novel-view Synthesis
Gyeongjin Kang, Younggeun Lee, Eunbyung Park
0
0
Neural Radiance Fields (NeRF) have achieved huge success in effectively capturing and representing 3D objects and scenes. However, several factors have impeded its further proliferation as next-generation 3D media. To establish a ubiquitous presence in everyday media formats, such as images and videos, it is imperative to devise a solution that effectively fulfills three key objectives: fast encoding and decoding time, compact model sizes, and high-quality renderings. Despite significant advancements, a comprehensive algorithm that adequately addresses all objectives has yet to be fully realized. In this work, we present CodecNeRF, a neural codec for NeRF representations, consisting of a novel encoder and decoder architecture that can generate a NeRF representation in a single forward pass. Furthermore, inspired by the recent parameter-efficient finetuning approaches, we develop a novel finetuning method to efficiently adapt the generated NeRF representations to a new test instance, leading to high-quality image renderings and compact code sizes. The proposed CodecNeRF, a newly suggested encoding-decoding-finetuning pipeline for NeRF, achieved unprecedented compression performance of more than 150x and 20x reduction in encoding time while maintaining (or improving) the image quality on widely used 3D object datasets, such as ShapeNet and Objaverse.
4/9/2024
🤔
GP-NeRF: Generalized Perception NeRF for Context-Aware 3D Scene Understanding
Hao Li, Dingwen Zhang, Yalun Dai, Nian Liu, Lechao Cheng, Jingfeng Li, Jingdong Wang, Junwei Han
0
0
Applying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular. Most existing methods treat semantic prediction as an additional rendering task, textit{i.e.}, the label rendering task, to build semantic NeRFs. However, by rendering semantic/instance labels per pixel without considering the contextual information of the rendered image, these methods usually suffer from unclear boundary segmentation and abnormal segmentation of pixels within an object. To solve this problem, we propose Generalized Perception NeRF (GP-NeRF), a novel pipeline that makes the widely used segmentation model and NeRF work compatibly under a unified framework, for facilitating context-aware 3D scene perception. To accomplish this goal, we introduce transformers to aggregate radiance as well as semantic embedding fields jointly for novel views and facilitate the joint volumetric rendering of both fields. In addition, we propose two self-distillation mechanisms, i.e., the Semantic Distill Loss and the Depth-Guided Semantic Distill Loss, to enhance the discrimination and quality of the semantic field and the maintenance of geometric consistency. In evaluation, we conduct experimental comparisons under two perception tasks (textit{i.e.} semantic and instance segmentation) using both synthetic and real-world datasets. Notably, our method outperforms SOTA approaches by 6.94%, 11.76%, and 8.47% on generalized semantic segmentation, finetuning semantic segmentation, and instance segmentation, respectively.
4/9/2024