Genuine-Focused Learning using Mask AutoEncoder for Generalized Fake Audio Detection

0
Sign in to get full access
Overview
- This paper presents a novel approach called "Genuine-Focused Learning" using a Mask AutoEncoder for generalized fake audio detection.
- The method aims to address the challenge of detecting fake audio, including speech synthesis and voice conversion, in a more generalized way.
- The proposed model focuses on learning the characteristics of genuine audio samples rather than trying to differentiate between real and fake audio directly.
Plain English Explanation
The paper introduces a new way to detect fake audio, such as synthetic speech or voice modifications, that works better across different types of fake audio. Instead of trying to directly identify if an audio clip is real or fake, the researchers' approach focuses on learning what genuine audio sounds like.
The key idea is to use a Mask AutoEncoder - a type of neural network that can reconstruct an input after randomly "masking" or hiding parts of it. By training this model to accurately reconstruct genuine audio samples, it learns the underlying characteristics of real audio.
This "genuine-focused" learning is hypothesized to be more effective than trying to differentiate real from fake audio directly, which can be challenging as fake audio techniques become more advanced. The masked autoencoder approach allows the model to develop a robust understanding of genuine audio that can then be used to detect a wide variety of fake audio samples, including those it wasn't explicitly trained on.
Technical Explanation
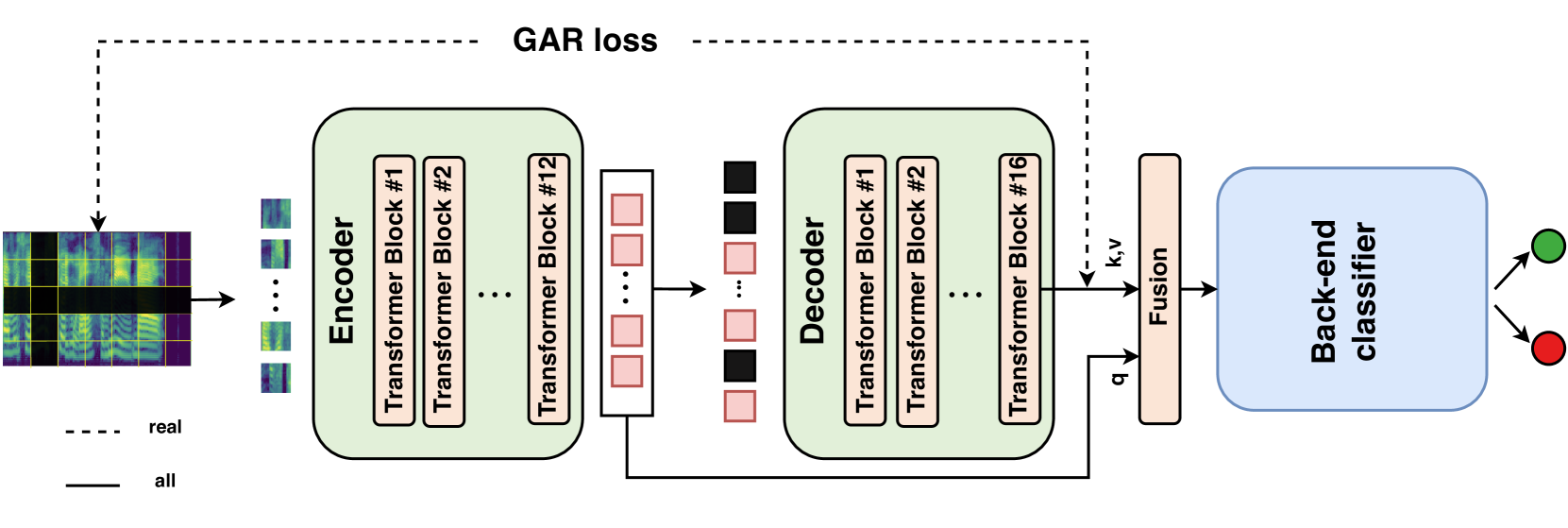
The paper proposes a "Genuine-Focused Learning" approach using a Mask AutoEncoder (MAE) architecture for generalized fake audio detection. The key elements are:
-
Mask AutoEncoder: The model consists of an encoder that converts the input audio into a latent representation, and a decoder that reconstructs the original audio from this latent code. During training, random portions of the input audio are "masked" or hidden, forcing the model to learn a robust latent representation that can be used to accurately reconstruct the complete audio.
-
Genuine-Focused Learning: Instead of training the model to directly classify audio as real or fake, the training objective is to minimize the reconstruction error on genuine audio samples. This encourages the model to focus on learning the characteristics of real audio, which can then be used to detect a variety of fake audio types.
-
Generalized Fake Audio Detection: The trained MAE model is used as a feature extractor. Audio samples, both real and fake, are passed through the encoder to obtain their latent representations. These features are then used to train a simple classifier to distinguish between real and fake audio, achieving better generalization compared to directly training a classifier on raw audio.
The paper evaluates the proposed approach on several benchmark datasets for fake audio detection, including Towards More General Video-based DeepFake Detection, Generalized Fake Audio Detection via Deep Stable, and Towards Generalizing Deep Audio Fake Detection Networks. The results show that the proposed genuine-focused learning approach outperforms existing methods in terms of generalization to unseen fake audio types.
Critical Analysis
The paper presents a promising approach for addressing the challenge of generalized fake audio detection. By focusing on learning the characteristics of genuine audio rather than trying to directly classify real vs. fake, the model is able to develop a more robust understanding of audio that can be applied to a wider range of fake audio types.
One potential limitation is that the paper does not extensively explore the model's performance on highly advanced fake audio techniques that may exhibit increasingly realistic characteristics. Further research may be needed to understand the limits of this approach as fake audio synthesis methods continue to improve.
Additionally, the paper does not delve into the potential societal implications of this technology, such as its use for content moderation or misinformation detection. It would be valuable to consider how this research could be responsibly applied and any ethical considerations that should be taken into account.
Conclusion
This paper introduces a novel "Genuine-Focused Learning" approach using a Mask AutoEncoder for generalized fake audio detection. By training the model to accurately reconstruct genuine audio samples, it learns a robust representation of real audio that can be effectively used to detect a wide variety of fake audio types, including those not seen during training.
The results demonstrate the potential of this method to address the challenge of generalized fake audio detection, which is becoming increasingly important as synthetic speech and voice conversion technologies continue to advance. While further research is needed to understand the limits of this approach, this work represents an important step towards more reliable and effective fake audio detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Genuine-Focused Learning using Mask AutoEncoder for Generalized Fake Audio Detection
Xiaopeng Wang, Ruibo Fu, Zhengqi Wen, Zhiyong Wang, Yuankun Xie, Yukun Liu, Jianhua Tao, Xuefei Liu, Yongwei Li, Xin Qi, Yi Lu, Shuchen Shi
The generalization of Fake Audio Detection (FAD) is critical due to the emergence of new spoofing techniques. Traditional FAD methods often focus solely on distinguishing between genuine and known spoofed audio. We propose a Genuine-Focused Learning (GFL) framework guided, aiming for highly generalized FAD, called GFL-FAD. This method incorporates a Counterfactual Reasoning Enhanced Representation (CRER) based on audio reconstruction using the Mask AutoEncoder (MAE) architecture to accurately model genuine audio features. To reduce the influence of spoofed audio during training, we introduce a genuine audio reconstruction loss, maintaining the focus on learning genuine data features. In addition, content-related bottleneck (BN) features are extracted from the MAE to supplement the knowledge of the original audio. These BN features are adaptively fused with CRER to further improve robustness. Our method achieves state-of-the-art performance with an EER of 0.25% on ASVspoof2019 LA.
Read more6/11/2024

0
Advancing Continual Learning for Robust Deepfake Audio Classification
Feiyi Dong, Qingchen Tang, Yichen Bai, Zihan Wang
The emergence of new spoofing attacks poses an increasing challenge to audio security. Current detection methods often falter when faced with unseen spoofing attacks. Traditional strategies, such as retraining with new data, are not always feasible due to extensive storage. This paper introduces a novel continual learning method Continual Audio Defense Enhancer (CADE). First, by utilizing a fixed memory size to store randomly selected samples from previous datasets, our approach conserves resources and adheres to privacy constraints. Additionally, we also apply two distillation losses in CADE. By distillation in classifiers, CADE ensures that the student model closely resembles that of the teacher model. This resemblance helps the model retain old information while facing unseen data. We further refine our model's performance with a novel embedding similarity loss that extends across multiple depth layers, facilitating superior positive sample alignment. Experiments conducted on the ASVspoof2019 dataset show that our proposed method outperforms the baseline methods.
Read more7/16/2024

0
FakeSound: Deepfake General Audio Detection
Zeyu Xie, Baihan Li, Xuenan Xu, Zheng Liang, Kai Yu, Mengyue Wu
With the advancement of audio generation, generative models can produce highly realistic audios. However, the proliferation of deepfake general audio can pose negative consequences. Therefore, we propose a new task, deepfake general audio detection, which aims to identify whether audio content is manipulated and to locate deepfake regions. Leveraging an automated manipulation pipeline, a dataset named FakeSound for deepfake general audio detection is proposed, and samples can be viewed on website https://FakeSoundData.github.io. The average binary accuracy of humans on all test sets is consistently below 0.6, which indicates the difficulty humans face in discerning deepfake audio and affirms the efficacy of the FakeSound dataset. A deepfake detection model utilizing a general audio pre-trained model is proposed as a benchmark system. Experimental results demonstrate that the performance of the proposed model surpasses the state-of-the-art in deepfake speech detection and human testers.
Read more6/13/2024
🔎
0
Does Audio Deepfake Detection Generalize?
Nicolas M. Muller, Pavel Czempin, Franziska Dieckmann, Adam Froghyar, Konstantin Bottinger
Current text-to-speech algorithms produce realistic fakes of human voices, making deepfake detection a much-needed area of research. While researchers have presented various techniques for detecting audio spoofs, it is often unclear exactly why these architectures are successful: Preprocessing steps, hyperparameter settings, and the degree of fine-tuning are not consistent across related work. Which factors contribute to success, and which are accidental? In this work, we address this problem: We systematize audio spoofing detection by re-implementing and uniformly evaluating architectures from related work. We identify overarching features for successful audio deepfake detection, such as using cqtspec or logspec features instead of melspec features, which improves performance by 37% EER on average, all other factors constant. Additionally, we evaluate generalization capabilities: We collect and publish a new dataset consisting of 37.9 hours of found audio recordings of celebrities and politicians, of which 17.2 hours are deepfakes. We find that related work performs poorly on such real-world data (performance degradation of up to one thousand percent). This may suggest that the community has tailored its solutions too closely to the prevailing ASVSpoof benchmark and that deepfakes are much harder to detect outside the lab than previously thought.
Read more8/28/2024