Geolocation Representation from Large Language Models are Generic Enhancers for Spatio-Temporal Learning

0

Sign in to get full access
Overview
- This paper examines how geolocation representations from large language models can enhance spatio-temporal learning tasks.
- The researchers investigate the capabilities of language models to capture and leverage spatial and temporal information.
- They show that pre-trained language models can provide generic and effective representations for a variety of spatio-temporal tasks.
Plain English Explanation
Large language models, like GPT-3, are trained on massive amounts of text data from the internet. These models have shown remarkable abilities to understand and generate human-like language. However, their potential to capture and utilize spatial and temporal information is less explored.
This research paper investigates whether the representations learned by language models can provide useful insights and enhancements for tasks that involve geographic locations and time-related information. The key idea is that the language model's broad knowledge, even if not explicitly geographic, may contain implicit cues about locations, distances, and temporal relationships.
The researchers evaluate how well these language model representations perform on a variety of spatio-temporal tasks, such as predicting the geographic location of images or understanding the spatial relationships in text. They find that the language model features can indeed boost the performance of these tasks, acting as a "generic enhancer" for spatio-temporal learning.
Technical Explanation
The paper first reviews related work on using language models for image geolocation and evaluating the spatial understanding capabilities of language models. It then proposes a framework to leverage the representations from pre-trained language models as input features for various spatio-temporal learning tasks.
The key technical contributions are:
-
Evaluating Language Model Representations: The authors assess how well features extracted from different language models, such as BERT and GPT, capture geographic and temporal information. They find that even models not explicitly trained on spatial data can learn relevant representations.
-
Enhancing Spatio-Temporal Tasks: The researchers demonstrate that incorporating the language model representations as additional features can improve the performance of downstream tasks like image geolocation and spatio-temporal text understanding.
-
Generalizability and Flexibility: The proposed approach shows the versatility of language model representations, as they can be used to enhance a wide range of spatio-temporal learning problems without requiring task-specific training.
Critical Analysis
The paper provides a compelling demonstration of how the rich semantic and contextual knowledge encoded in language models can be leveraged to improve spatio-temporal learning tasks. However, the authors acknowledge some limitations:
- The study focuses on a limited set of tasks and datasets, so further evaluation on a broader range of applications would be valuable.
- The underlying reasons why language model representations are effective for these tasks are not fully explored, warranting deeper investigations into the model's spatial and temporal understanding capabilities.
- The performance gains, while significant, may be task-dependent, and the optimal way to integrate language model features is not yet clear.
Future research could examine how to further enhance the spatial and temporal awareness of language models, potentially by incorporating more explicit geographic or temporal information during pre-training. Exploring the interpretability of the learned representations could also yield important insights.
Conclusion
This paper demonstrates that the representations learned by large language models can serve as powerful "generic enhancers" for a variety of spatio-temporal learning tasks. By leveraging the broad semantic knowledge encoded in these models, researchers can boost the performance of applications ranging from image geolocation to understanding spatial relationships in text.
The findings highlight the untapped potential of language models to capture and leverage spatial and temporal information, even if not explicitly trained on such data. As AI systems become increasingly important for understanding and navigating the physical world, this work underscores the value of exploring the spatial and temporal capabilities of large-scale language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Geolocation Representation from Large Language Models are Generic Enhancers for Spatio-Temporal Learning
Junlin He, Tong Nie, Wei Ma
In the geospatial domain, universal representation models are significantly less prevalent than their extensive use in natural language processing and computer vision. This discrepancy arises primarily from the high costs associated with the input of existing representation models, which often require street views and mobility data. To address this, we develop a novel, training-free method that leverages large language models (LLMs) and auxiliary map data from OpenStreetMap to derive geolocation representations (LLMGeovec). LLMGeovec can represent the geographic semantics of city, country, and global scales, which acts as a generic enhancer for spatio-temporal learning. Specifically, by direct feature concatenation, we introduce a simple yet effective paradigm for enhancing multiple spatio-temporal tasks including geographic prediction (GP), long-term time series forecasting (LTSF), and graph-based spatio-temporal forecasting (GSTF). LLMGeovec can seamlessly integrate into a wide spectrum of spatio-temporal learning models, providing immediate enhancements. Experimental results demonstrate that LLMGeovec achieves global coverage and significantly boosts the performance of leading GP, LTSF, and GSTF models.
Read more8/23/2024

0
LLMGeo: Benchmarking Large Language Models on Image Geolocation In-the-wild
Zhiqiang Wang, Dejia Xu, Rana Muhammad Shahroz Khan, Yanbin Lin, Zhiwen Fan, Xingquan Zhu
Image geolocation is a critical task in various image-understanding applications. However, existing methods often fail when analyzing challenging, in-the-wild images. Inspired by the exceptional background knowledge of multimodal language models, we systematically evaluate their geolocation capabilities using a novel image dataset and a comprehensive evaluation framework. We first collect images from various countries via Google Street View. Then, we conduct training-free and training-based evaluations on closed-source and open-source multi-modal language models. we conduct both training-free and training-based evaluations on closed-source and open-source multimodal language models. Our findings indicate that closed-source models demonstrate superior geolocation abilities, while open-source models can achieve comparable performance through fine-tuning.
Read more6/3/2024
🤔
0
Image-Based Geolocation Using Large Vision-Language Models
Yi Liu, Junchen Ding, Gelei Deng, Yuekang Li, Tianwei Zhang, Weisong Sun, Yaowen Zheng, Jingquan Ge, Yang Liu
Geolocation is now a vital aspect of modern life, offering numerous benefits but also presenting serious privacy concerns. The advent of large vision-language models (LVLMs) with advanced image-processing capabilities introduces new risks, as these models can inadvertently reveal sensitive geolocation information. This paper presents the first in-depth study analyzing the challenges posed by traditional deep learning and LVLM-based geolocation methods. Our findings reveal that LVLMs can accurately determine geolocations from images, even without explicit geographic training. To address these challenges, we introduce tool{}, an innovative framework that significantly enhances image-based geolocation accuracy. tool{} employs a systematic chain-of-thought (CoT) approach, mimicking human geoguessing strategies by carefully analyzing visual and contextual cues such as vehicle types, architectural styles, natural landscapes, and cultural elements. Extensive testing on a dataset of 50,000 ground-truth data points shows that tool{} outperforms both traditional models and human benchmarks in accuracy. It achieves an impressive average score of 4550.5 in the GeoGuessr game, with an 85.37% win rate, and delivers highly precise geolocation predictions, with the closest distances as accurate as 0.3 km. Furthermore, our study highlights issues related to dataset integrity, leading to the creation of a more robust dataset and a refined framework that leverages LVLMs' cognitive capabilities to improve geolocation precision. These findings underscore tool{}'s superior ability to interpret complex visual data, the urgent need to address emerging security vulnerabilities posed by LVLMs, and the importance of responsible AI development to ensure user privacy protection.
Read more8/20/2024
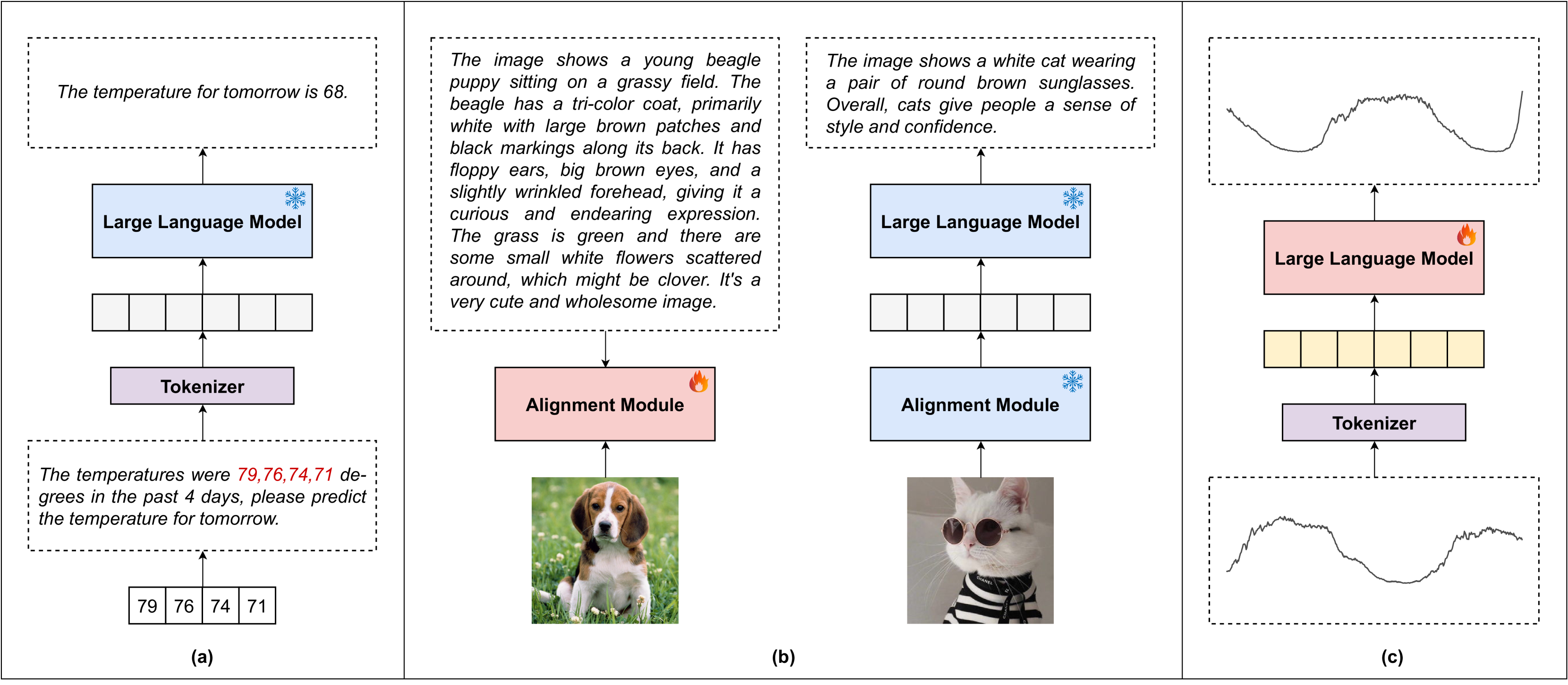
0
How Can Large Language Models Understand Spatial-Temporal Data?
Lei Liu, Shuo Yu, Runze Wang, Zhenxun Ma, Yanming Shen
While Large Language Models (LLMs) dominate tasks like natural language processing and computer vision, harnessing their power for spatial-temporal forecasting remains challenging. The disparity between sequential text and complex spatial-temporal data hinders this application. To address this issue, this paper introduces STG-LLM, an innovative approach empowering LLMs for spatial-temporal forecasting. We tackle the data mismatch by proposing: 1) STG-Tokenizer: This spatial-temporal graph tokenizer transforms intricate graph data into concise tokens capturing both spatial and temporal relationships; 2) STG-Adapter: This minimalistic adapter, consisting of linear encoding and decoding layers, bridges the gap between tokenized data and LLM comprehension. By fine-tuning only a small set of parameters, it can effectively grasp the semantics of tokens generated by STG-Tokenizer, while preserving the original natural language understanding capabilities of LLMs. Extensive experiments on diverse spatial-temporal benchmark datasets show that STG-LLM successfully unlocks LLM potential for spatial-temporal forecasting. Remarkably, our approach achieves competitive performance on par with dedicated SOTA methods.
Read more5/20/2024