Evaluating Spatial Understanding of Large Language Models
2310.14540
0
0
🤔
Abstract
Large language models (LLMs) show remarkable capabilities across a variety of tasks. Despite the models only seeing text in training, several recent studies suggest that LLM representations implicitly capture aspects of the underlying grounded concepts. Here, we explore LLM representations of a particularly salient kind of grounded knowledge -- spatial relationships. We design natural-language navigation tasks and evaluate the ability of LLMs, in particular GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about spatial structures. These tasks reveal substantial variability in LLM performance across different spatial structures, including square, hexagonal, and triangular grids, rings, and trees. In extensive error analysis, we find that LLMs' mistakes reflect both spatial and non-spatial factors. These findings suggest that LLMs appear to capture certain aspects of spatial structure implicitly, but room for improvement remains.
Create account to get full access
Overview
- Recent studies suggest that large language models (LLMs) can implicitly capture aspects of underlying grounded concepts, even though they are trained only on text.
- This paper explores LLM representations of spatial relationships, a particularly salient form of grounded knowledge.
- The authors design natural-language navigation tasks to evaluate the ability of various LLMs, including GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about different spatial structures.
Plain English Explanation
Large language models (LLMs) have shown remarkable capabilities across a wide range of tasks. Even though these models are trained only on text, recent research suggests they can implicitly capture certain underlying grounded concepts.
In this study, the researchers investigate how well LLMs can represent and reason about spatial relationships, which are a particularly important form of grounded knowledge. They designed a series of natural-language navigation tasks to evaluate the performance of several LLMs, including GPT-3.5-turbo, GPT-4, and the Llama2 model series.
The tasks involved navigating through different spatial structures, such as square, hexagonal, and triangular grids, as well as rings and tree-like structures. The researchers found that LLM performance varied substantially across these different spatial layouts, suggesting the models can capture some aspects of spatial structure implicitly. However, room for improvement remains, as the models still make mistakes that reflect both spatial and non-spatial factors.
Technical Explanation
The authors designed a set of natural-language navigation tasks to assess how well LLMs can represent and reason about different spatial structures. These tasks required the models to understand and navigate through various layouts, including square, hexagonal, and triangular grids, as well as rings and tree-like structures.
The researchers evaluated the performance of several prominent LLMs on these tasks, including GPT-3.5-turbo, GPT-4, and models from the Llama2 series. Their analysis revealed substantial variability in the models' abilities to handle the different spatial configurations, suggesting the LLMs can implicitly capture certain aspects of spatial relationships.
Through extensive error analysis, the authors found that the models' mistakes reflect both spatial and non-spatial factors. This indicates that while LLMs appear to have learned some spatial reasoning capabilities, there is still room for improvement in this area. Visualization techniques and alternative training approaches may help further enhance LLMs' spatial reasoning abilities.
Critical Analysis
The paper presents a thorough investigation of LLMs' ability to represent and reason about spatial relationships, a critical component of grounded cognition. The researchers' use of natural-language navigation tasks provides a practical and intuitive way to assess these capabilities.
One limitation of the study is that it focuses only on a few specific spatial structures, and it remains to be seen how well the findings generalize to a broader range of spatial configurations. Additional research exploring a wider variety of spatial layouts and tasks would help further our understanding of LLMs' spatial reasoning abilities.
The paper also acknowledges that the models' mistakes reflect both spatial and non-spatial factors, suggesting that there is still room for improvement in this area. Exploring the precise nature of these non-spatial factors and how they influence spatial reasoning could provide valuable insights for future model development.
Overall, this study offers valuable insights into the spatial reasoning capabilities of LLMs and highlights the need for continued research in this important area of grounded cognition.
Conclusion
This paper presents a detailed investigation of how well large language models (LLMs) can represent and reason about spatial relationships, a crucial aspect of grounded cognition. The authors designed a series of natural-language navigation tasks that revealed substantial variability in LLM performance across different spatial structures, suggesting the models can implicitly capture certain spatial concepts.
The findings from this study contribute to our understanding of the capabilities and limitations of LLMs, and they underscore the importance of continued research in the area of spatial reasoning. Improvements in this domain could have far-reaching implications for a wide range of applications, from navigation and robotics to language understanding and commonsense reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Can Large Language Models Create New Knowledge for Spatial Reasoning Tasks?
Thomas Greatrix, Roger Whitaker, Liam Turner, Walter Colombo
0
0
The potential for Large Language Models (LLMs) to generate new information offers a potential step change for research and innovation. This is challenging to assert as it can be difficult to determine what an LLM has previously seen during training, making newness difficult to substantiate. In this paper we observe that LLMs are able to perform sophisticated reasoning on problems with a spatial dimension, that they are unlikely to have previously directly encountered. While not perfect, this points to a significant level of understanding that state-of-the-art LLMs can now achieve, supporting the proposition that LLMs are able to yield significant emergent properties. In particular, Claude 3 is found to perform well in this regard.
5/24/2024
💬
Distortions in Judged Spatial Relations in Large Language Models
Nir Fulman, Abdulkadir Memduhou{g}lu, Alexander Zipf
0
0
We present a benchmark for assessing the capability of Large Language Models (LLMs) to discern intercardinal directions between geographic locations and apply it to three prominent LLMs: GPT-3.5, GPT-4, and Llama-2. This benchmark specifically evaluates whether LLMs exhibit a hierarchical spatial bias similar to humans, where judgments about individual locations' spatial relationships are influenced by the perceived relationships of the larger groups that contain them. To investigate this, we formulated 14 questions focusing on well-known American cities. Seven questions were designed to challenge the LLMs with scenarios potentially influenced by the orientation of larger geographical units, such as states or countries, while the remaining seven targeted locations were less susceptible to such hierarchical categorization. Among the tested models, GPT-4 exhibited superior performance with 55 percent accuracy, followed by GPT-3.5 at 47 percent, and Llama-2 at 45 percent. The models showed significantly reduced accuracy on tasks with suspected hierarchical bias. For example, GPT-4's accuracy dropped to 33 percent on these tasks, compared to 86 percent on others. However, the models identified the nearest cardinal direction in most cases, reflecting their associative learning mechanism, thereby embodying human-like misconceptions. We discuss avenues for improving the spatial reasoning capabilities of LLMs.
6/5/2024
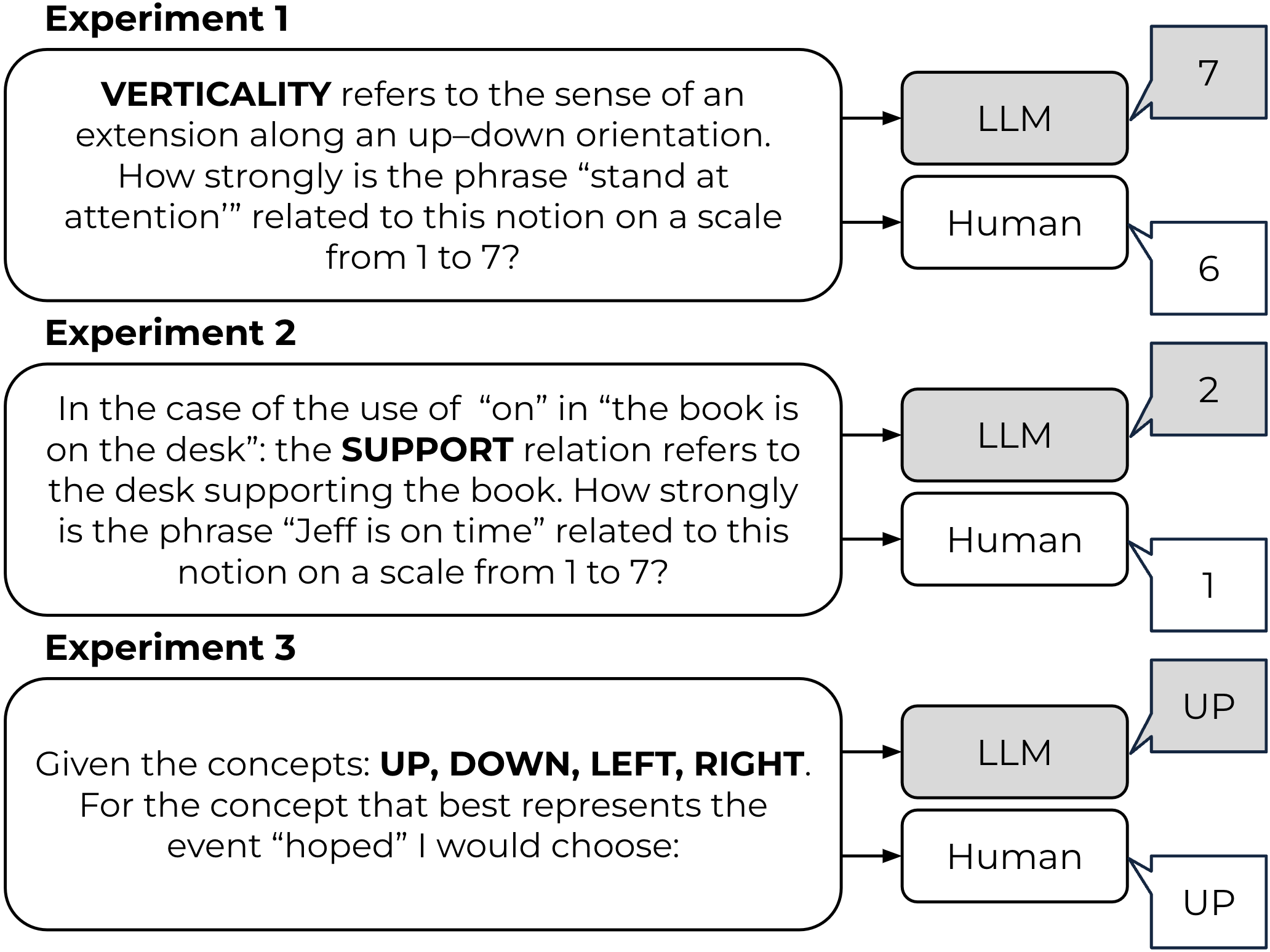
Exploring Spatial Schema Intuitions in Large Language and Vision Models
Philipp Wicke, Lennart Wachowiak
0
0
Despite the ubiquity of large language models (LLMs) in AI research, the question of embodiment in LLMs remains underexplored, distinguishing them from embodied systems in robotics where sensory perception directly informs physical action. Our investigation navigates the intriguing terrain of whether LLMs, despite their non-embodied nature, effectively capture implicit human intuitions about fundamental, spatial building blocks of language. We employ insights from spatial cognitive foundations developed through early sensorimotor experiences, guiding our exploration through the reproduction of three psycholinguistic experiments. Surprisingly, correlations between model outputs and human responses emerge, revealing adaptability without a tangible connection to embodied experiences. Notable distinctions include polarized language model responses and reduced correlations in vision language models. This research contributes to a nuanced understanding of the interplay between language, spatial experiences, and the computations made by large language models. More at https://cisnlp.github.io/Spatial_Schemas/
5/28/2024
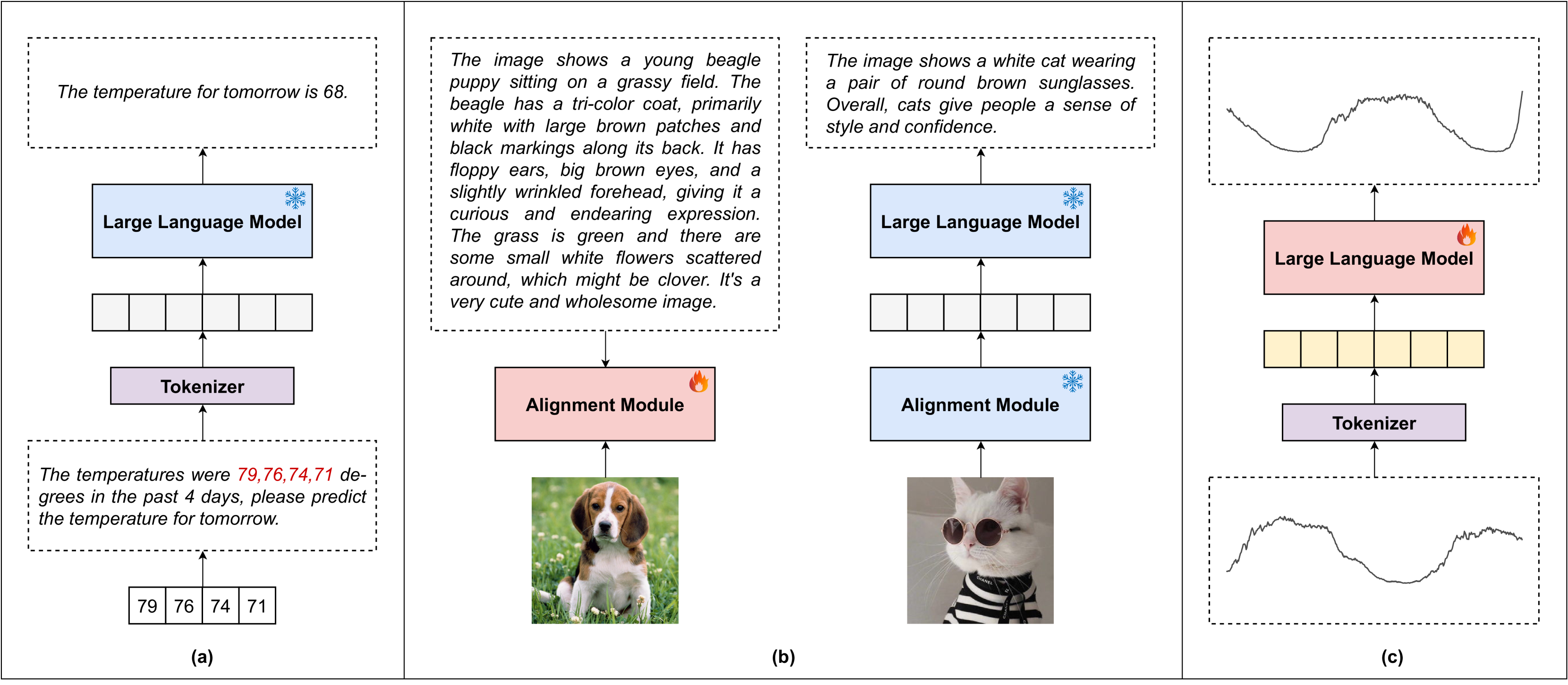
How Can Large Language Models Understand Spatial-Temporal Data?
Lei Liu, Shuo Yu, Runze Wang, Zhenxun Ma, Yanming Shen
0
0
While Large Language Models (LLMs) dominate tasks like natural language processing and computer vision, harnessing their power for spatial-temporal forecasting remains challenging. The disparity between sequential text and complex spatial-temporal data hinders this application. To address this issue, this paper introduces STG-LLM, an innovative approach empowering LLMs for spatial-temporal forecasting. We tackle the data mismatch by proposing: 1) STG-Tokenizer: This spatial-temporal graph tokenizer transforms intricate graph data into concise tokens capturing both spatial and temporal relationships; 2) STG-Adapter: This minimalistic adapter, consisting of linear encoding and decoding layers, bridges the gap between tokenized data and LLM comprehension. By fine-tuning only a small set of parameters, it can effectively grasp the semantics of tokens generated by STG-Tokenizer, while preserving the original natural language understanding capabilities of LLMs. Extensive experiments on diverse spatial-temporal benchmark datasets show that STG-LLM successfully unlocks LLM potential for spatial-temporal forecasting. Remarkably, our approach achieves competitive performance on par with dedicated SOTA methods.
5/20/2024