On the Geometry of Reinforcement Learning in Continuous State and Action Spaces

0
🏅
Sign in to get full access
Overview
- Reinforcement learning has been successfully applied to complex tasks with continuous state and action spaces.
- However, most theoretical work focuses on finite state and action spaces.
- The paper proposes a geometric approach to understand continuous state and action spaces.
- It shows that the reachable states form a low-dimensional manifold within the high-dimensional state space.
- An algorithm is introduced that learns a policy in this low-dimensional representation.
Plain English Explanation
Reinforcement learning is a powerful technique that allows AI systems to learn how to perform complex tasks by interacting with their environment and receiving rewards or penalties. In recent years, reinforcement learning has been applied to problems with continuous state and action spaces, which means the system can experience a wide range of possible situations and take a variety of actions.
Despite these practical successes, the mathematical theory behind reinforcement learning has mostly focused on simpler problems with a finite number of possible states and actions. This paper takes a new approach, using geometry to understand the structure of continuous state and action spaces.
The key insight is that even though the nominal state space may be high-dimensional, the states that the system can actually reach form a lower-dimensional manifold - a curved surface embedded within the larger space. The dimensionality of this manifold is related to the dimensionality of the action space, and the paper proves an upper bound on this relationship.
Building on this geometric understanding, the researchers developed an algorithm that learns a policy (a way of selecting actions) directly in this low-dimensional representation of the state space. Experiments show that policies learned this way can perform as well as or better than those learned in the original high-dimensional space.
Technical Explanation
The paper proposes a geometric approach to understanding reinforcement learning in continuous state and action spaces. Central to their work is the idea that the transition dynamics of the environment induce a low-dimensional manifold of reachable states, embedded within the high-dimensional nominal state space.
Formally, the authors prove that under certain conditions, the dimensionality of this manifold is at most the dimensionality of the action space plus one. This is an important theoretical result, as it links the geometry of the state space to the dimensionality of the available actions.
To demonstrate the applicability of this insight, the researchers introduce an algorithm that learns a policy in this low-dimensional representation of the state space. The algorithm trains a deep neural network to map the high-dimensional states to a lower-dimensional latent space, while simultaneously learning a policy in that latent space using the DDPG reinforcement learning method.
Experiments on four MuJoCo control suite tasks show that policies learned in this way perform on par or better than those learned directly in the original high-dimensional state space. This demonstrates the practical value of the geometric insights developed in the paper.
Critical Analysis
The paper makes an important theoretical contribution by establishing a link between the dimensionality of the action space and the dimensionality of the reachable state manifold. This provides a new lens through which to understand the structure of continuous state and action spaces in reinforcement learning.
However, the theoretical analysis assumes certain conditions, such as the smoothness of the transition dynamics, which may not always hold in practice. Additionally, the paper does not address how to reliably estimate the dimensionality of the manifold in real-world problems, where the true underlying structure may be difficult to discern.
While the experimental results are promising, the paper only evaluates the approach on a limited set of simulated control tasks. Further research is needed to understand how well the method would generalize to a wider range of reinforcement learning problems, particularly those with more complex dynamics or higher-dimensional state and action spaces.
Conclusion
This paper presents a novel geometric approach to understanding the structure of continuous state and action spaces in reinforcement learning. By proving a bound on the dimensionality of the reachable state manifold, the researchers have laid the groundwork for a deeper theoretical understanding of these types of reinforcement learning problems.
The proposed algorithm that learns policies directly in the low-dimensional latent space shows promising empirical results, suggesting that this geometric perspective can lead to practical benefits in terms of sample efficiency and performance. As the field of reinforcement learning continues to tackle increasingly complex and high-dimensional problems, this work provides a valuable new tool for advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
On the Geometry of Reinforcement Learning in Continuous State and Action Spaces
Saket Tiwari, Omer Gottesman, George Konidaris
Advances in reinforcement learning have led to its successful application in complex tasks with continuous state and action spaces. Despite these advances in practice, most theoretical work pertains to finite state and action spaces. We propose building a theoretical understanding of continuous state and action spaces by employing a geometric lens. Central to our work is the idea that the transition dynamics induce a low dimensional manifold of reachable states embedded in the high-dimensional nominal state space. We prove that, under certain conditions, the dimensionality of this manifold is at most the dimensionality of the action space plus one. This is the first result of its kind, linking the geometry of the state space to the dimensionality of the action space. We empirically corroborate this upper bound for four MuJoCo environments. We further demonstrate the applicability of our result by learning a policy in this low dimensional representation. To do so we introduce an algorithm that learns a mapping to a low dimensional representation, as a narrow hidden layer of a deep neural network, in tandem with the policy using DDPG. Our experiments show that a policy learnt this way perform on par or better for four MuJoCo control suite tasks.
Read more8/13/2024
🤿
0
Deep Reinforcement Learning in Parameterized Action Space
Matthew Hausknecht, Peter Stone
Recent work has shown that deep neural networks are capable of approximating both value functions and policies in reinforcement learning domains featuring continuous state and action spaces. However, to the best of our knowledge no previous work has succeeded at using deep neural networks in structured (parameterized) continuous action spaces. To fill this gap, this paper focuses on learning within the domain of simulated RoboCup soccer, which features a small set of discrete action types, each of which is parameterized with continuous variables. The best learned agent can score goals more reliably than the 2012 RoboCup champion agent. As such, this paper represents a successful extension of deep reinforcement learning to the class of parameterized action space MDPs.
Read more5/6/2024

0
Randomized algorithms and PAC bounds for inverse reinforcement learning in continuous spaces
Angeliki Kamoutsi, Peter Schmitt-Forster, Tobias Sutter, Volkan Cevher, John Lygeros
This work studies discrete-time discounted Markov decision processes with continuous state and action spaces and addresses the inverse problem of inferring a cost function from observed optimal behavior. We first consider the case in which we have access to the entire expert policy and characterize the set of solutions to the inverse problem by using occupation measures, linear duality, and complementary slackness conditions. To avoid trivial solutions and ill-posedness, we introduce a natural linear normalization constraint. This results in an infinite-dimensional linear feasibility problem, prompting a thorough analysis of its properties. Next, we use linear function approximators and adopt a randomized approach, namely the scenario approach and related probabilistic feasibility guarantees, to derive epsilon-optimal solutions for the inverse problem. We further discuss the sample complexity for a desired approximation accuracy. Finally, we deal with the more realistic case where we only have access to a finite set of expert demonstrations and a generative model and provide bounds on the error made when working with samples.
Read more5/27/2024
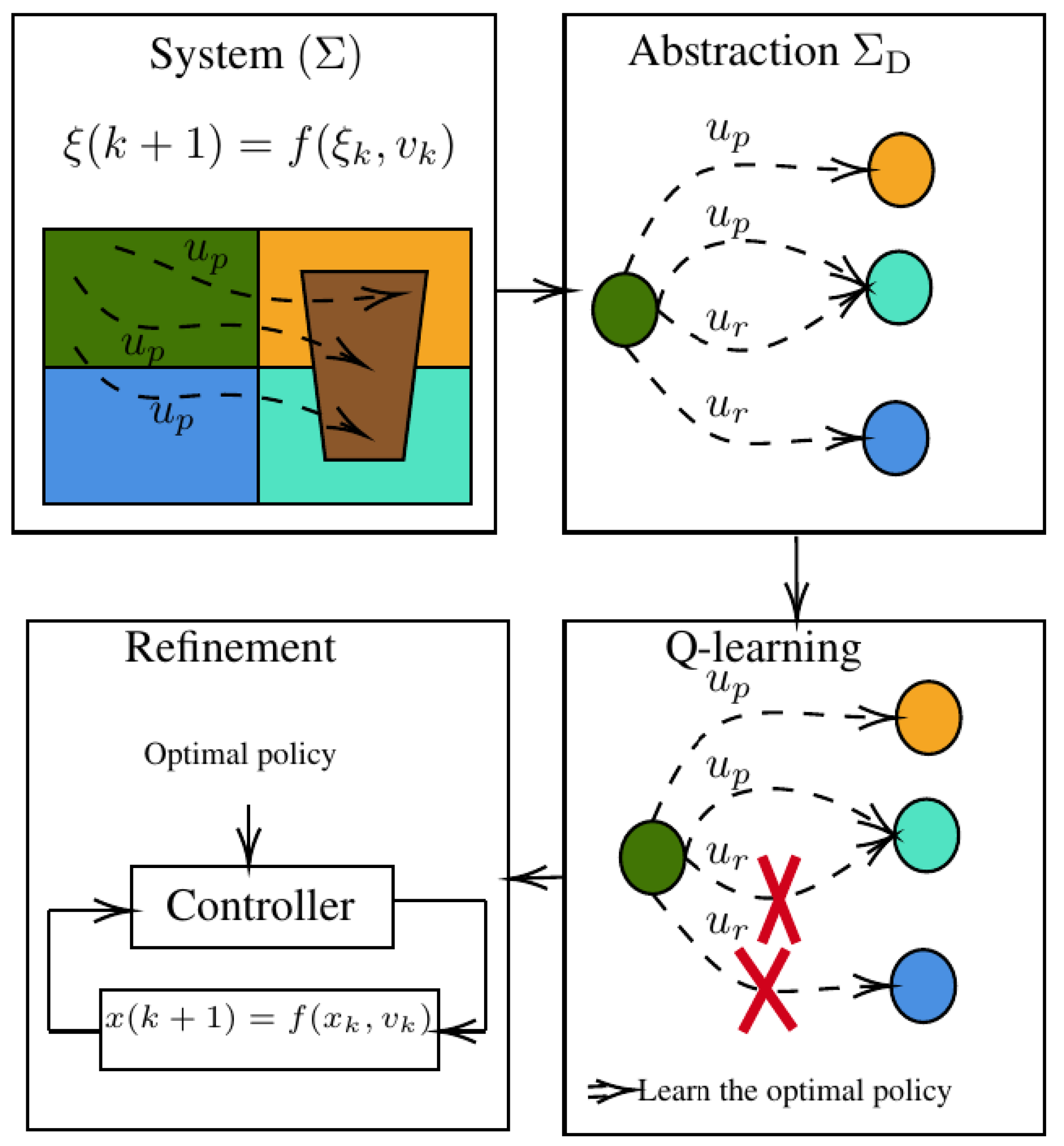
0
How to discretize continuous state-action spaces in Q-learning: A symbolic control approach
Sadek Belamfedel Alaoui, Adnane Saoud
Q-learning is widely recognized as an effective approach for synthesizing controllers to achieve specific goals. However, handling challenges posed by continuous state-action spaces remains an ongoing research focus. This paper presents a systematic analysis that highlights a major drawback in space discretization methods. To address this challenge, the paper proposes a symbolic model that represents behavioral relations, such as alternating simulation from abstraction to the controlled system. This relation allows for seamless application of the synthesized controller based on abstraction to the original system. Introducing a novel Q-learning technique for symbolic models, the algorithm yields two Q-tables encoding optimal policies. Theoretical analysis demonstrates that these Q-tables serve as both upper and lower bounds on the Q-values of the original system with continuous spaces. Additionally, the paper explores the correlation between the parameters of the space abstraction and the loss in Q-values. The resulting algorithm facilitates achieving optimality within an arbitrary accuracy, providing control over the trade-off between accuracy and computational complexity. The obtained results provide valuable insights for selecting appropriate learning parameters and refining the controller. The engineering relevance of the proposed Q-learning based symbolic model is illustrated through two case studies.
Read more6/7/2024