Ghost-Stereo: GhostNet-based Cost Volume Enhancement and Aggregation for Stereo Matching Networks

0
🤿
Sign in to get full access
Overview
- This paper proposes a novel stereo matching network called Ghost-Stereo that achieves comparable performance to state-of-the-art real-time methods while being more computationally efficient.
- The key innovations are the use of GhostNet-based feature extraction, a GhostNet feature-based cost volume enhancement module, and a lightweight 3D convolution-based cost volume aggregation module.
- Ghost-Stereo demonstrates strong performance on several public benchmarks and shows better generalization ability compared to existing methods.
Plain English Explanation
Stereo matching is a computer vision technique that uses two cameras to estimate the depth or distance of objects in an image. This can have many real-world applications. Current state-of-the-art stereo matching methods often use deep neural networks and complex 3D convolutions, which can be computationally expensive and slow.
The researchers behind Ghost-Stereo have developed a new approach that is more efficient while still achieving strong performance. The key ideas are:
- GhostNet-based feature extraction: They use a lightweight neural network called GhostNet to extract visual features from the input images. This is more efficient than traditional feature extraction methods.
- GhostNet feature-based cost volume enhancement: They construct and fuse cost volumes (representations of the similarity between image patches) using the GhostNet features. This helps the network better understand the spatial context of the scene.
- Lightweight 3D convolution aggregation: Instead of using the typical heavy 3D convolutions for cost volume aggregation, they propose a more efficient, GhostNet-inspired 3D convolution block.
By combining these innovations, Ghost-Stereo can match the performance of other state-of-the-art real-time stereo matching methods, but with lower computational requirements. This could make it useful for applications like autonomous driving or robotics where efficient depth estimation is important.
Technical Explanation
The paper begins by noting that current deep learning-based stereo matching methods often use a Siamese network architecture with 3D convolutions for cost volume aggregation. While effective, these models can be computationally expensive and slow.
To address this, the authors propose Ghost-Stereo, a novel end-to-end stereo matching network. The feature extraction component uses a GhostNet-based U-shaped structure, which is more efficient than traditional feature extraction methods.
The core of Ghost-Stereo is two key modules:
- GhostNet feature-based cost volume enhancement (Ghost-CVE): This module constructs and fuses cost volumes using the GhostNet-based features. This helps the network better capture the spatial context of the scene.
- GhostNet-inspired lightweight 3D convolution-based cost volume aggregation (Ghost-CVA): Instead of using standard 3D convolutions, this module employs a more efficient, GhostNet-inspired 3D convolution bottleneck block for cost volume aggregation.
These modules are combined with a context and geometry fusion module to create a classical hourglass-shaped cost volume aggregation structure.
Experiments on several public benchmarks show that Ghost-Stereo achieves comparable performance to state-of-the-art real-time stereo matching methods, while being more computationally efficient. The authors also demonstrate that Ghost-Stereo has better generalization ability compared to existing approaches.
Critical Analysis
The paper presents a novel and promising approach to stereo matching that addresses the computational complexity issues of existing methods. The use of GhostNet-based feature extraction and the innovative cost volume enhancement and aggregation modules are compelling ideas that seem to work well in practice.
However, the paper does not delve deeply into the potential limitations or failure cases of the Ghost-Stereo approach. For example, it would be interesting to understand how the method performs in challenging scenarios, such as scenes with complex textures or occlusions, which can be difficult for stereo matching algorithms.
Additionally, the paper could have provided more insight into the specific architectural choices and hyperparameter tuning that were necessary to achieve the reported results. This information could be valuable for researchers looking to build upon or replicate the work.
Overall, the Ghost-Stereo approach is an impressive contribution to the field of stereo matching, and the authors have demonstrated its effectiveness through thorough experimentation. Further research into the limitations and potential areas for improvement could help strengthen the work and drive the field forward.
Conclusion
The Ghost-Stereo paper presents a novel and efficient stereo matching network that achieves comparable performance to state-of-the-art real-time methods while being more computationally efficient. The key innovations, including the use of GhostNet-based feature extraction, cost volume enhancement, and lightweight cost volume aggregation, make Ghost-Stereo a promising approach for applications where efficient depth estimation is crucial, such as autonomous driving or robotics.
The strong experimental results and the network's demonstrated generalization ability suggest that Ghost-Stereo could have a significant impact on the field of stereo matching. As the authors continue to refine and expand upon this work, it will be interesting to see how it evolves and what new insights or applications it may uncover.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Ghost-Stereo: GhostNet-based Cost Volume Enhancement and Aggregation for Stereo Matching Networks
Xingguang Jiang, Xiaofeng Bian, Chenggang Guo
Depth estimation based on stereo matching is a classic but popular computer vision problem, which has a wide range of real-world applications. Current stereo matching methods generally adopt the deep Siamese neural network architecture, and have achieved impressing performance by constructing feature matching cost volumes and using 3D convolutions for cost aggregation. However, most existing methods suffer from large number of parameters and slow running time due to the sequential use of 3D convolutions. In this paper, we propose Ghost-Stereo, a novel end-to-end stereo matching network. The feature extraction part of the network uses the GhostNet to form a U-shaped structure. The core of Ghost-Stereo is a GhostNet feature-based cost volume enhancement (Ghost-CVE) module and a GhostNet-inspired lightweight cost volume aggregation (Ghost-CVA) module. For the Ghost-CVE part, cost volumes are constructed and fused by the GhostNet-based features to enhance the spatial context awareness. For the Ghost-CVA part, a lightweight 3D convolution bottleneck block based on the GhostNet is proposed to reduce the computational complexity in this module. By combining with the context and geometry fusion module, a classical hourglass-shaped cost volume aggregate structure is constructed. Ghost-Stereo achieves a comparable performance than state-of-the-art real-time methods on several publicly benchmarks, and shows a better generalization ability.
Read more5/24/2024
0
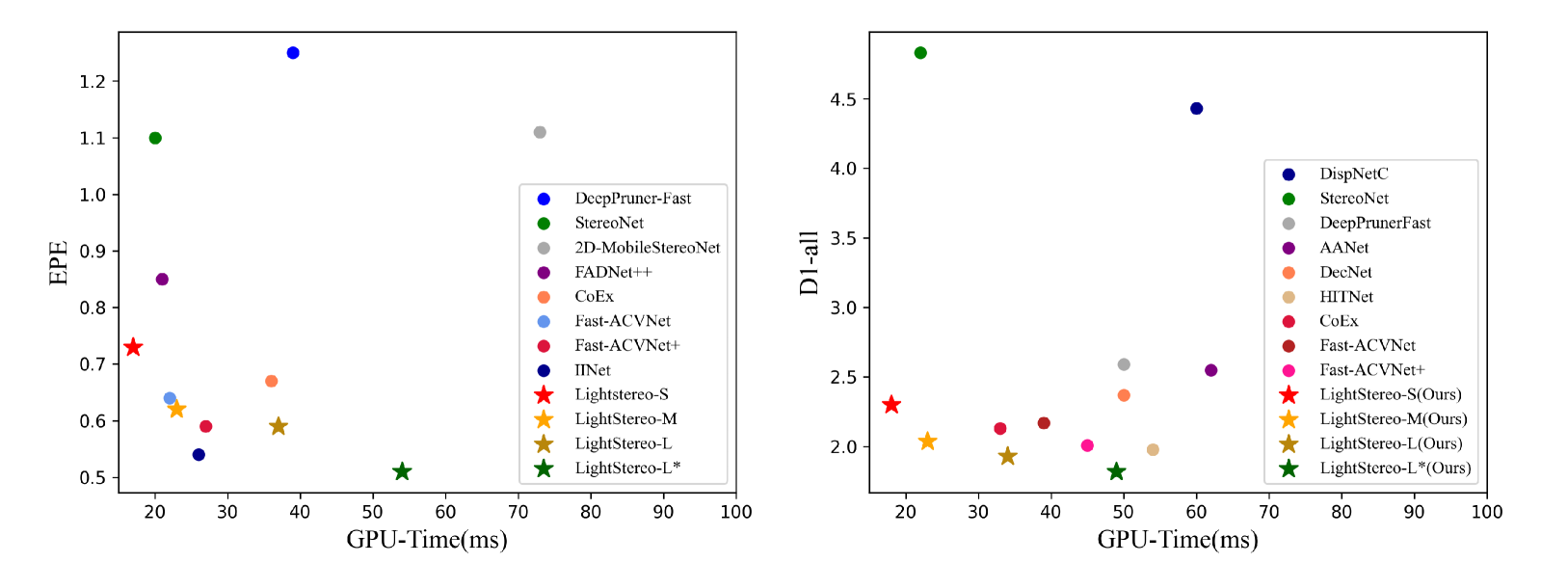
LightStereo: Channel Boost Is All Your Need for Efficient 2D Cost Aggregation
Xianda Guo, Chenming Zhang, Dujun Nie, Wenzhao Zheng, Youmin Zhang, Long Chen
We present LightStereo, a cutting-edge stereo-matching network crafted to accelerate the matching process. Departing from conventional methodologies that rely on aggregating computationally intensive 4D costs, LightStereo adopts the 3D cost volume as a lightweight alternative. While similar approaches have been explored previously, our breakthrough lies in enhancing performance through a dedicated focus on the channel dimension of the 3D cost volume, where the distribution of matching costs is encapsulated. Our exhaustive exploration has yielded plenty of strategies to amplify the capacity of the pivotal dimension, ensuring both precision and efficiency. We compare the proposed LightStereo with existing state-of-the-art methods across various benchmarks, which demonstrate its superior performance in speed, accuracy, and resource utilization. LightStereo achieves a competitive EPE metric in the SceneFlow datasets while demanding a minimum of only 22 GFLOPs, with an inference time of just 17 ms. Our comprehensive analysis reveals the effect of 2D cost aggregation for stereo matching, paving the way for real-world applications of efficient stereo systems. Code will be available at url{https://github.com/XiandaGuo/OpenStereo}.
Read more7/1/2024

0
GoMVS: Geometrically Consistent Cost Aggregation for Multi-View Stereo
Jiang Wu, Rui Li, Haofei Xu, Wenxun Zhao, Yu Zhu, Jinqiu Sun, Yanning Zhang
Matching cost aggregation plays a fundamental role in learning-based multi-view stereo networks. However, directly aggregating adjacent costs can lead to suboptimal results due to local geometric inconsistency. Related methods either seek selective aggregation or improve aggregated depth in the 2D space, both are unable to handle geometric inconsistency in the cost volume effectively. In this paper, we propose GoMVS to aggregate geometrically consistent costs, yielding better utilization of adjacent geometries. More specifically, we correspond and propagate adjacent costs to the reference pixel by leveraging the local geometric smoothness in conjunction with surface normals. We achieve this by the geometric consistent propagation (GCP) module. It computes the correspondence from the adjacent depth hypothesis space to the reference depth space using surface normals, then uses the correspondence to propagate adjacent costs to the reference geometry, followed by a convolution for aggregation. Our method achieves new state-of-the-art performance on DTU, Tanks & Temple, and ETH3D datasets. Notably, our method ranks 1st on the Tanks & Temple Advanced benchmark.
Read more4/12/2024
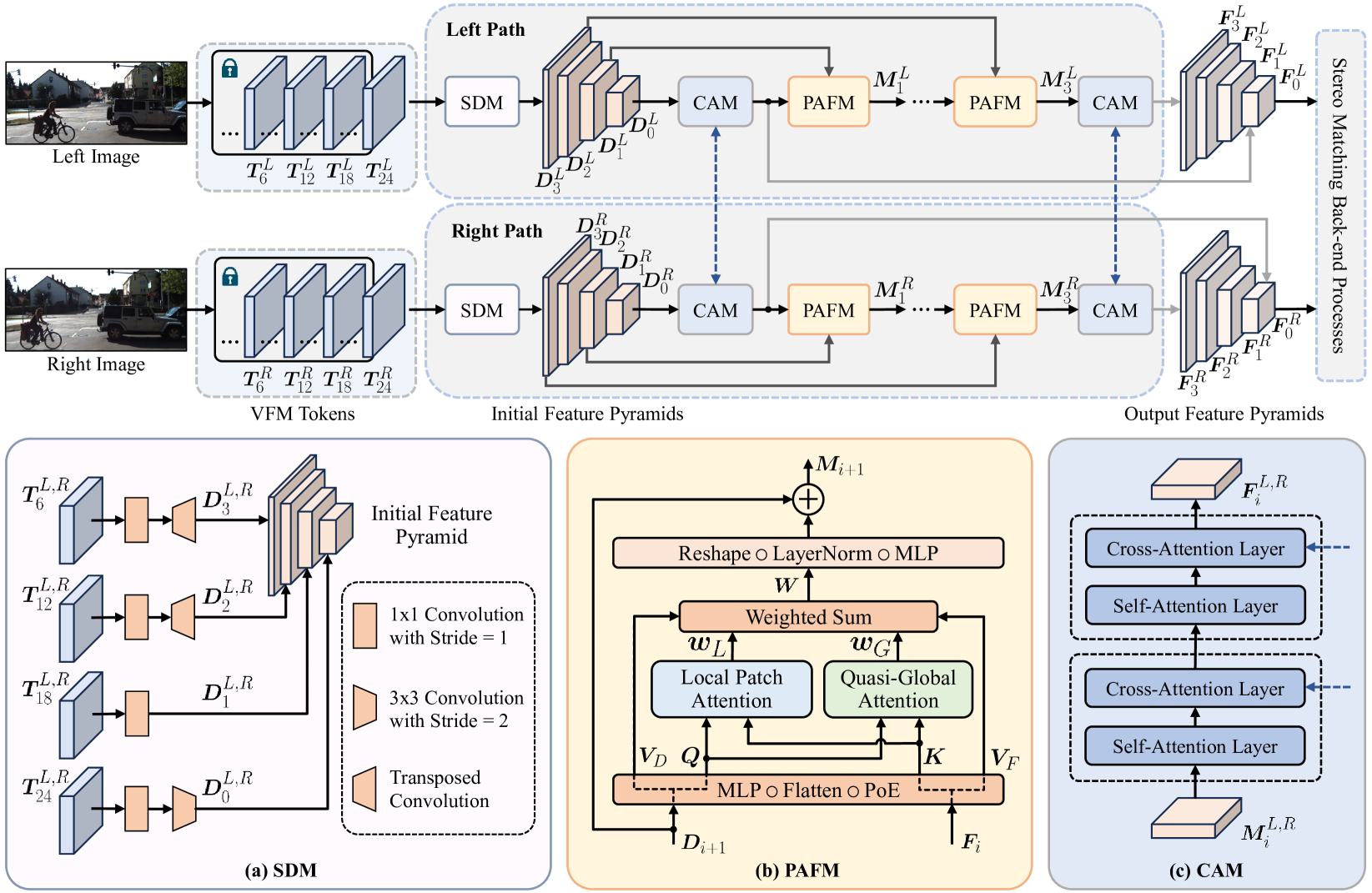
0
Playing to Vision Foundation Model's Strengths in Stereo Matching
Chuang-Wei Liu, Qijun Chen, Rui Fan
Stereo matching has become a key technique for 3D environment perception in intelligent vehicles. For a considerable time, convolutional neural networks (CNNs) have remained the mainstream choice for feature extraction in this domain. Nonetheless, there is a growing consensus that the existing paradigm should evolve towards vision foundation models (VFM), particularly those developed based on vision Transformers (ViTs) and pre-trained through self-supervision on extensive, unlabeled datasets. While VFMs are adept at extracting informative, general-purpose visual features, specifically for dense prediction tasks, their performance often lacks in geometric vision tasks. This study serves as the first exploration of a viable approach for adapting VFMs to stereo matching. Our ViT adapter, referred to as ViTAS, is constructed upon three types of modules: spatial differentiation, patch attention fusion, and cross-attention. The first module initializes feature pyramids, while the latter two aggregate stereo and multi-scale contextual information into fine-grained features, respectively. ViTAStereo, which combines ViTAS with cost volume-based stereo matching back-end processes, achieves the top rank on the KITTI Stereo 2012 dataset and outperforms the second-best network StereoBase by approximately 7.9% in terms of the percentage of error pixels, with a tolerance of 3 pixels. Additional experiments across diverse scenarios further demonstrate its superior generalizability compared to all other state-of-the-art approaches. We believe this new paradigm will pave the way for the next generation of stereo matching networks.
Read more4/10/2024