LightStereo: Channel Boost Is All Your Need for Efficient 2D Cost Aggregation

0
Sign in to get full access
Related Work
LightStereo: Channel Boost Is All Your Need for Efficient 2D Cost Aggregation
Overview
- Explores a new approach to 2D cost aggregation for stereo matching that is more efficient than traditional methods
- Introduces a novel "channel boost" technique that enhances the feature channels without increasing computation
- Demonstrates improved performance on standard stereo benchmarks with significantly reduced runtime
Plain English Explanation
The paper investigates a new way to perform 2D cost aggregation, which is an important step in stereo matching algorithms used to reconstruct 3D scenes from pairs of 2D images. Traditional cost aggregation methods can be computationally intensive, which limits their use in real-time applications.
The key idea behind the "channel boost" technique is to enhance the feature channels in the cost volume - the 3D array of matching costs - without needing to do additional expensive computations. By selectively boosting certain feature channels, the algorithm is able to better distinguish between correct and incorrect matches, leading to more accurate depth estimates.
The researchers show that this channel boost approach outperforms previous state-of-the-art stereo matching methods on standard benchmarks, while also being significantly faster to run. This makes the LightStereo algorithm well-suited for applications like robotics, autonomous vehicles, and virtual/augmented reality, where efficient 3D reconstruction is critical.
Technical Explanation
The paper proposes a new 2D cost aggregation module called "LightStereo" that uses a novel "channel boost" technique to enhance the feature channels in the cost volume. This is done by applying a learnable scaling factor to each channel, effectively amplifying the most discriminative features without increasing the overall computational cost.
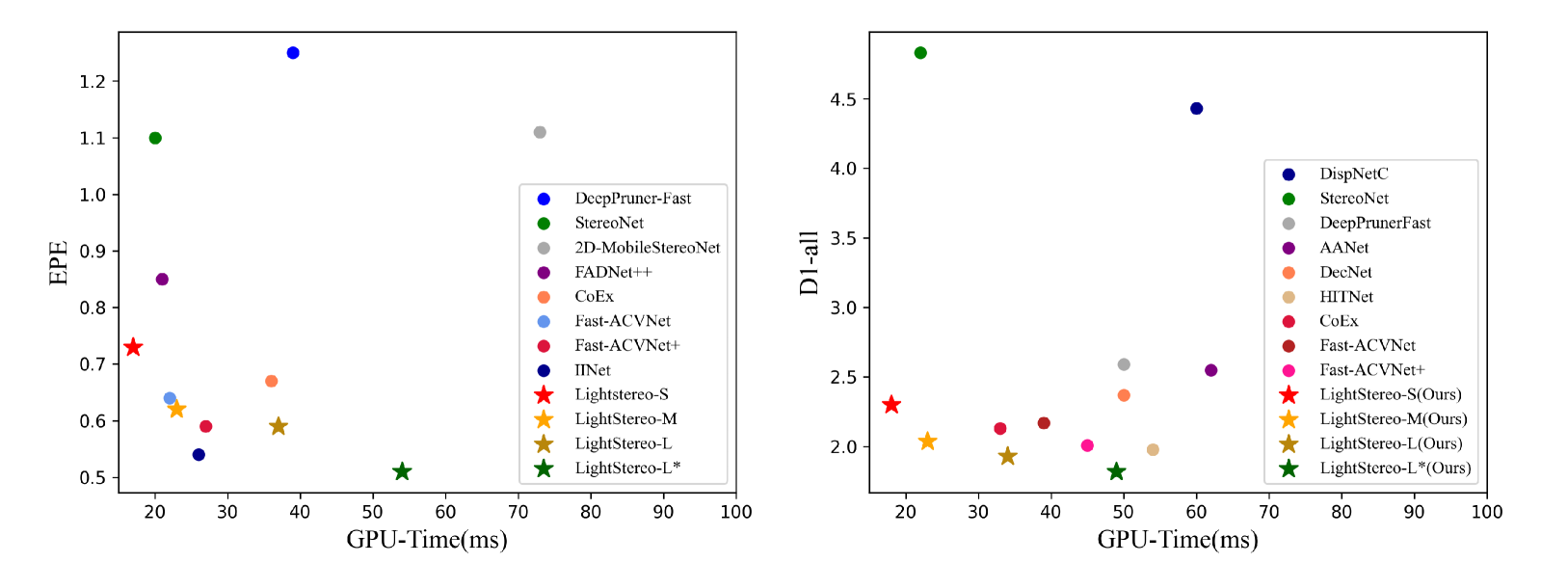
The LightStereo module is integrated into a typical stereo matching architecture, replacing the traditional 2D cost aggregation step. Experiments on the Scene Flow, KITTI, and Middlebury stereo benchmarks demonstrate that LightStereo achieves state-of-the-art accuracy while running significantly faster than previous methods.
The key insights from the technical analysis are:
- The channel boost operation is efficient and can be easily integrated into existing stereo pipelines.
- The learnable scaling factors allow the network to adaptively emphasize the most relevant features for accurate depth estimation.
- LightStereo outperforms prior cost aggregation techniques in terms of both accuracy and runtime, making it a compelling choice for real-time 3D reconstruction.
Critical Analysis
The paper provides a compelling solution to the challenge of efficient 2D cost aggregation for stereo matching. The channel boost approach is a simple yet effective technique that enhances the discriminative power of the feature channels without adding significant computational overhead.
One potential limitation is that the method may not generalize as well to more complex scenes or challenging stereo matching scenarios, as the channel boost factors are learned in a data-driven manner. Further research could explore ways to make the channel boost more robust or adaptable to different types of input data.
Additionally, the paper only evaluates LightStereo on standard stereo benchmarks and does not provide real-world deployment results. Assessing the algorithm's performance in practical applications, such as robotics or autonomous driving, would further strengthen the case for its adoption.
Overall, the LightStereo approach represents an important step forward in improving the efficiency of stereo matching, which could have significant implications for a wide range of computer vision and 3D reconstruction applications.
Conclusion
The LightStereo paper presents a novel and efficient 2D cost aggregation technique for stereo matching that outperforms previous state-of-the-art methods in both accuracy and runtime. By introducing a "channel boost" operation to selectively enhance the most discriminative features, the algorithm is able to achieve high-quality depth estimates without the computational burden of traditional cost aggregation approaches.
The key innovation and potential impact of this research are in enabling more efficient 3D reconstruction for real-time applications, such as robotic navigation, autonomous driving, and immersive virtual/augmented reality experiences. As the demand for accurate and responsive 3D sensing continues to grow, solutions like LightStereo could play a crucial role in unlocking new capabilities and driving further advancements in computer vision and spatial computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LightStereo: Channel Boost Is All Your Need for Efficient 2D Cost Aggregation
Xianda Guo, Chenming Zhang, Dujun Nie, Wenzhao Zheng, Youmin Zhang, Long Chen
We present LightStereo, a cutting-edge stereo-matching network crafted to accelerate the matching process. Departing from conventional methodologies that rely on aggregating computationally intensive 4D costs, LightStereo adopts the 3D cost volume as a lightweight alternative. While similar approaches have been explored previously, our breakthrough lies in enhancing performance through a dedicated focus on the channel dimension of the 3D cost volume, where the distribution of matching costs is encapsulated. Our exhaustive exploration has yielded plenty of strategies to amplify the capacity of the pivotal dimension, ensuring both precision and efficiency. We compare the proposed LightStereo with existing state-of-the-art methods across various benchmarks, which demonstrate its superior performance in speed, accuracy, and resource utilization. LightStereo achieves a competitive EPE metric in the SceneFlow datasets while demanding a minimum of only 22 GFLOPs, with an inference time of just 17 ms. Our comprehensive analysis reveals the effect of 2D cost aggregation for stereo matching, paving the way for real-world applications of efficient stereo systems. Code will be available at url{https://github.com/XiandaGuo/OpenStereo}.
Read more7/1/2024
🤿
0
Ghost-Stereo: GhostNet-based Cost Volume Enhancement and Aggregation for Stereo Matching Networks
Xingguang Jiang, Xiaofeng Bian, Chenggang Guo
Depth estimation based on stereo matching is a classic but popular computer vision problem, which has a wide range of real-world applications. Current stereo matching methods generally adopt the deep Siamese neural network architecture, and have achieved impressing performance by constructing feature matching cost volumes and using 3D convolutions for cost aggregation. However, most existing methods suffer from large number of parameters and slow running time due to the sequential use of 3D convolutions. In this paper, we propose Ghost-Stereo, a novel end-to-end stereo matching network. The feature extraction part of the network uses the GhostNet to form a U-shaped structure. The core of Ghost-Stereo is a GhostNet feature-based cost volume enhancement (Ghost-CVE) module and a GhostNet-inspired lightweight cost volume aggregation (Ghost-CVA) module. For the Ghost-CVE part, cost volumes are constructed and fused by the GhostNet-based features to enhance the spatial context awareness. For the Ghost-CVA part, a lightweight 3D convolution bottleneck block based on the GhostNet is proposed to reduce the computational complexity in this module. By combining with the context and geometry fusion module, a classical hourglass-shaped cost volume aggregate structure is constructed. Ghost-Stereo achieves a comparable performance than state-of-the-art real-time methods on several publicly benchmarks, and shows a better generalization ability.
Read more5/24/2024

0
GoMVS: Geometrically Consistent Cost Aggregation for Multi-View Stereo
Jiang Wu, Rui Li, Haofei Xu, Wenxun Zhao, Yu Zhu, Jinqiu Sun, Yanning Zhang
Matching cost aggregation plays a fundamental role in learning-based multi-view stereo networks. However, directly aggregating adjacent costs can lead to suboptimal results due to local geometric inconsistency. Related methods either seek selective aggregation or improve aggregated depth in the 2D space, both are unable to handle geometric inconsistency in the cost volume effectively. In this paper, we propose GoMVS to aggregate geometrically consistent costs, yielding better utilization of adjacent geometries. More specifically, we correspond and propagate adjacent costs to the reference pixel by leveraging the local geometric smoothness in conjunction with surface normals. We achieve this by the geometric consistent propagation (GCP) module. It computes the correspondence from the adjacent depth hypothesis space to the reference depth space using surface normals, then uses the correspondence to propagate adjacent costs to the reference geometry, followed by a convolution for aggregation. Our method achieves new state-of-the-art performance on DTU, Tanks & Temple, and ETH3D datasets. Notably, our method ranks 1st on the Tanks & Temple Advanced benchmark.
Read more4/12/2024

0
One-Click Upgrade from 2D to 3D: Sandwiched RGB-D Video Compression for Stereoscopic Teleconferencing
Yueyu Hu, Onur G. Guleryuz, Philip A. Chou, Danhang Tang, Jonathan Taylor, Rus Maxham, Yao Wang
Stereoscopic video conferencing is still challenging due to the need to compress stereo RGB-D video in real-time. Though hardware implementations of standard video codecs such as H.264 / AVC and HEVC are widely available, they are not designed for stereoscopic videos and suffer from reduced quality and performance. Specific multiview or 3D extensions of these codecs are complex and lack efficient implementations. In this paper, we propose a new approach to upgrade a 2D video codec to support stereo RGB-D video compression, by wrapping it with a neural pre- and post-processor pair. The neural networks are end-to-end trained with an image codec proxy, and shown to work with a more sophisticated video codec. We also propose a geometry-aware loss function to improve rendering quality. We train the neural pre- and post-processors on a synthetic 4D people dataset, and evaluate it on both synthetic and real-captured stereo RGB-D videos. Experimental results show that the neural networks generalize well to unseen data and work out-of-box with various video codecs. Our approach saves about 30% bit-rate compared to a conventional video coding scheme and MV-HEVC at the same level of rendering quality from a novel view, without the need of a task-specific hardware upgrade.
Read more4/16/2024