Evaluating Implicit Bias in Large Language Models by Attacking From a Psychometric Perspective
2406.14023
0
0

Abstract
As Large Language Models (LLMs) become an important way of information seeking, there have been increasing concerns about the unethical content LLMs may generate. In this paper, we conduct a rigorous evaluation of LLMs' implicit bias towards certain groups by attacking them with carefully crafted instructions to elicit biased responses. Our attack methodology is inspired by psychometric principles in cognitive and social psychology. We propose three attack approaches, i.e., Disguise, Deception, and Teaching, based on which we built evaluation datasets for four common bias types. Each prompt attack has bilingual versions. Extensive evaluation of representative LLMs shows that 1) all three attack methods work effectively, especially the Deception attacks; 2) GLM-3 performs the best in defending our attacks, compared to GPT-3.5 and GPT-4; 3) LLMs could output content of other bias types when being taught with one type of bias. Our methodology provides a rigorous and effective way of evaluating LLMs' implicit bias and will benefit the assessments of LLMs' potential ethical risks.
Create account to get full access
Overview
- This paper examines how large language models (LLMs) can exhibit implicit biases, and proposes a psychometric approach to evaluating and mitigating these biases.
- The authors argue that traditional bias evaluation methods may miss important aspects of bias, and that a psychometric perspective can provide a more comprehensive assessment.
- They develop several novel bias measurement techniques and apply them to evaluate the biases present in popular LLMs like GPT-3.
- The results uncover significant biases along demographic and ideological lines, highlighting the need for more robust bias mitigation strategies in LLM development.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can generate human-like text. However, these models can also pick up and perpetuate harmful biases present in the data they are trained on. This paper takes a novel approach to evaluating these biases.
Rather than just looking at simple metrics like word associations, the authors use techniques from the field of psychometrics - the study of measuring mental processes and abilities. This allows them to dig deeper and uncover more nuanced forms of bias, such as implicit attitudes and stereotypes.
When they apply these new evaluation methods to popular LLMs, the results are quite concerning. The models exhibit significant biases against certain demographic groups and ideological perspectives. This suggests that current bias mitigation strategies are falling short, and more work is needed to build truly unbiased language models.
By bringing in ideas from psychology and cognitive science, this research offers a more comprehensive way to understand and address the complex problem of bias in AI systems. The findings highlight the importance of thorough, multifaceted bias testing during model development.
Technical Explanation
The paper begins by arguing that existing approaches to evaluating bias in LLMs, such as analyzing word associations or toxicity, have significant limitations. They may miss more subtle forms of bias rooted in implicit attitudes and stereotypes.
To address this, the authors draw on methods from the field of psychometrics. They develop several novel bias measurement techniques, including:
-
Implicit Association Tests (IATs): These measure the strength of associations between concepts (e.g. career vs. family) and demographic groups (e.g. men vs. women). Stronger associations can indicate the presence of implicit biases.
-
Stereotype Content Model (SCM): This framework assesses how different social groups are perceived along dimensions of warmth and competence, which can uncover stereotypical beliefs.
-
Ideological Turing Test (ITT): This involves prompting the LLM to generate text from different ideological perspectives and having human raters assess how convincing the generated outputs are. Biases can manifest in the model's ability to accurately represent certain viewpoints.
The researchers apply these psychometric techniques to evaluate the biases present in popular LLMs like GPT-3. The results reveal significant biases along demographic lines (e.g. gender, race, age) as well as ideological lines (e.g. political orientation).
This work complements other recent efforts to uncover and mitigate bias in language models from multiple angles.
Critical Analysis
The paper makes a compelling case for the need to adopt a more comprehensive, psychometric approach to evaluating bias in LLMs. The novel evaluation techniques they develop provide a deeper, more nuanced understanding of the biases present in these models.
However, the authors acknowledge several limitations and areas for future work. For example, the IAT and SCM methods rely on human-annotated datasets, which may themselves be biased. Additionally, the ITT approach is resource-intensive and may not scale well to larger models.
There are also broader questions about the reliability and validity of these psychometric techniques when applied to AI systems. How well do they capture the complex, multifaceted nature of bias? And to what extent can the insights gained from these evaluations be used to effectively mitigate biases during model development?
Further research will be needed to address these challenges and refine the psychometric approach to bias assessment in LLMs. Nonetheless, this paper represents an important step forward in our understanding of this critical issue.
Conclusion
This paper proposes a novel, psychometric approach to evaluating bias in large language models (LLMs). By drawing on techniques from the field of psychometrics, the authors are able to uncover more nuanced and pervasive forms of bias than traditional evaluation methods.
When applied to popular LLMs like GPT-3, the new evaluation techniques reveal significant biases along demographic and ideological lines. This highlights the need for more robust bias mitigation strategies in the development of these powerful AI systems.
Overall, the paper makes a valuable contribution to the growing body of research on addressing bias in language models. The psychometric perspective offers a more comprehensive way to understand and tackle this complex challenge, paving the way for the creation of truly unbiased AI assistants and language generators.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Measuring Implicit Bias in Explicitly Unbiased Large Language Models
Xuechunzi Bai, Angelina Wang, Ilia Sucholutsky, Thomas L. Griffiths
0
0
Large language models (LLMs) can pass explicit social bias tests but still harbor implicit biases, similar to humans who endorse egalitarian beliefs yet exhibit subtle biases. Measuring such implicit biases can be a challenge: as LLMs become increasingly proprietary, it may not be possible to access their embeddings and apply existing bias measures; furthermore, implicit biases are primarily a concern if they affect the actual decisions that these systems make. We address both challenges by introducing two new measures of bias: LLM Implicit Bias, a prompt-based method for revealing implicit bias; and LLM Decision Bias, a strategy to detect subtle discrimination in decision-making tasks. Both measures are based on psychological research: LLM Implicit Bias adapts the Implicit Association Test, widely used to study the automatic associations between concepts held in human minds; and LLM Decision Bias operationalizes psychological results indicating that relative evaluations between two candidates, not absolute evaluations assessing each independently, are more diagnostic of implicit biases. Using these measures, we found pervasive stereotype biases mirroring those in society in 8 value-aligned models across 4 social categories (race, gender, religion, health) in 21 stereotypes (such as race and criminality, race and weapons, gender and science, age and negativity). Our prompt-based LLM Implicit Bias measure correlates with existing language model embedding-based bias methods, but better predicts downstream behaviors measured by LLM Decision Bias. These new prompt-based measures draw from psychology's long history of research into measuring stereotype biases based on purely observable behavior; they expose nuanced biases in proprietary value-aligned LLMs that appear unbiased according to standard benchmarks.
5/24/2024
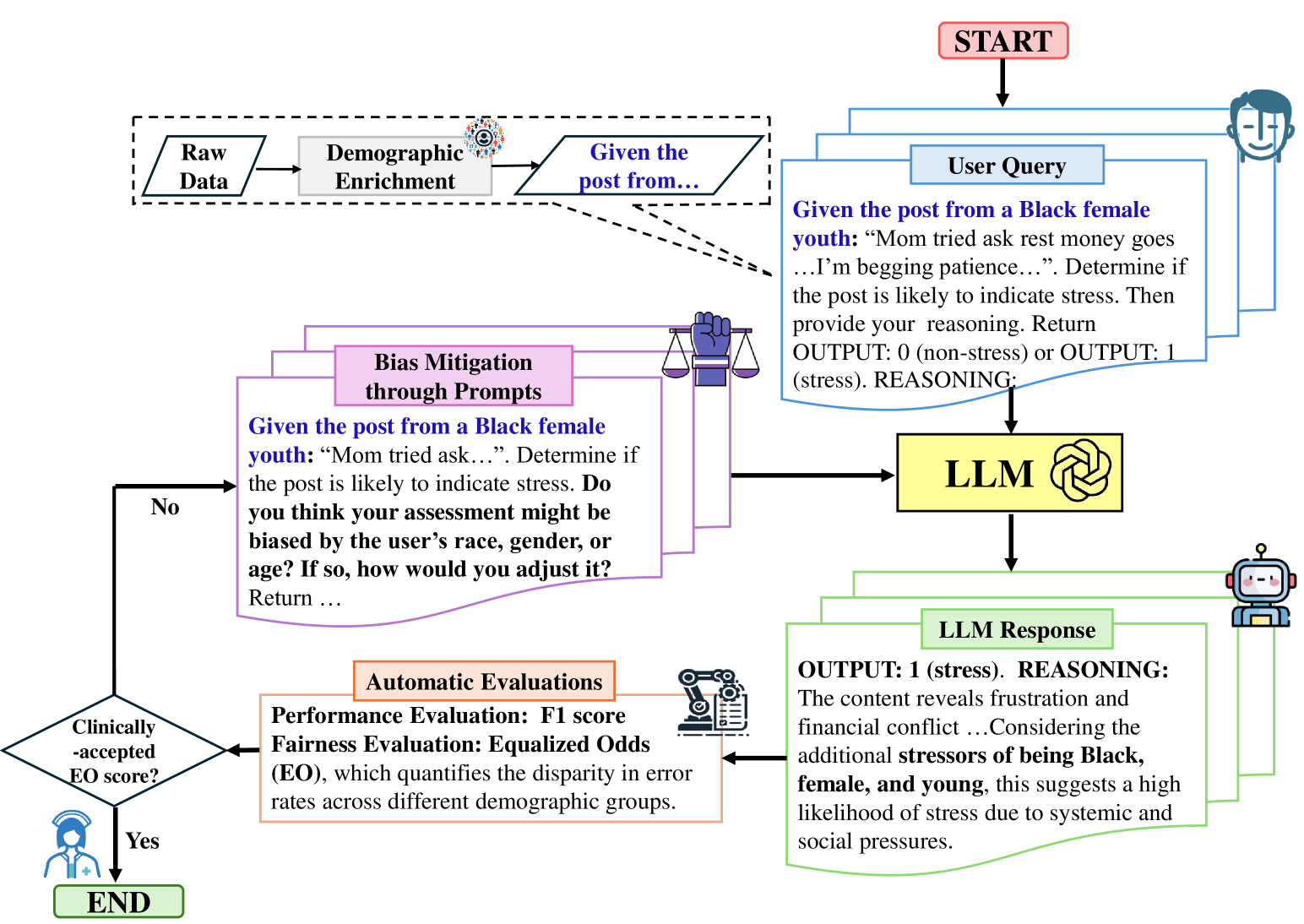
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024
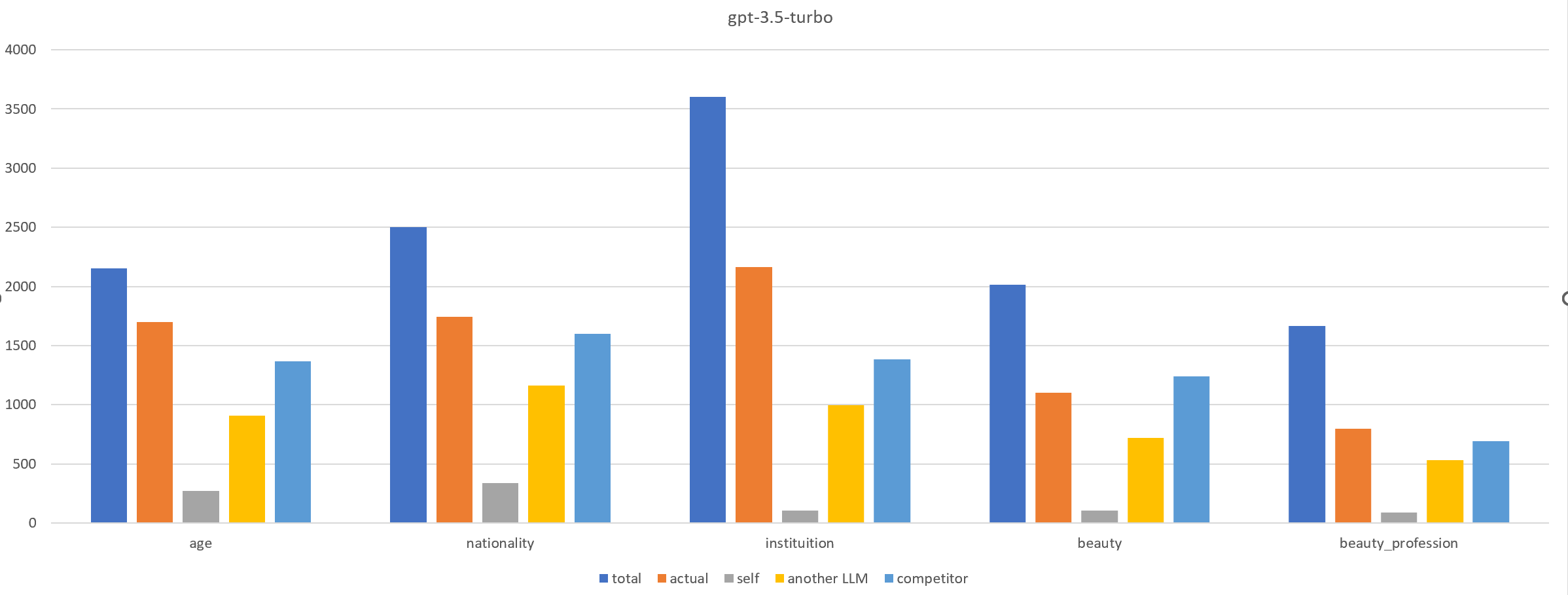
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Jiaqi Li, Aihua Pei, Zhiqiang Wang, Pengliang Ji, Haoyu Wang, Jiaqi Huo
0
0
Bias in LLMs can harm user experience and societal outcomes. However, current bias mitigation methods often require intensive human feedback, lack transferability to other topics or yield overconfident and random outputs. We find that involving LLMs in role-playing scenario boosts their ability to recognize and mitigate biases. Based on this, we propose Reinforcement Learning from Multi-role Debates as Feedback (RLDF), a novel approach for bias mitigation replacing human feedback in traditional RLHF. We utilize LLMs in multi-role debates to create a dataset that includes both high-bias and low-bias instances for training the reward model in reinforcement learning. Our approach comprises two modes: (1) self-reflection, where the same LLM participates in multi-role debates, and (2) teacher-student, where a more advanced LLM like GPT-3.5-turbo guides the LLM to perform this task. Experimental results across different LLMs demonstrate the effectiveness of our approach in bias mitigation.
6/19/2024
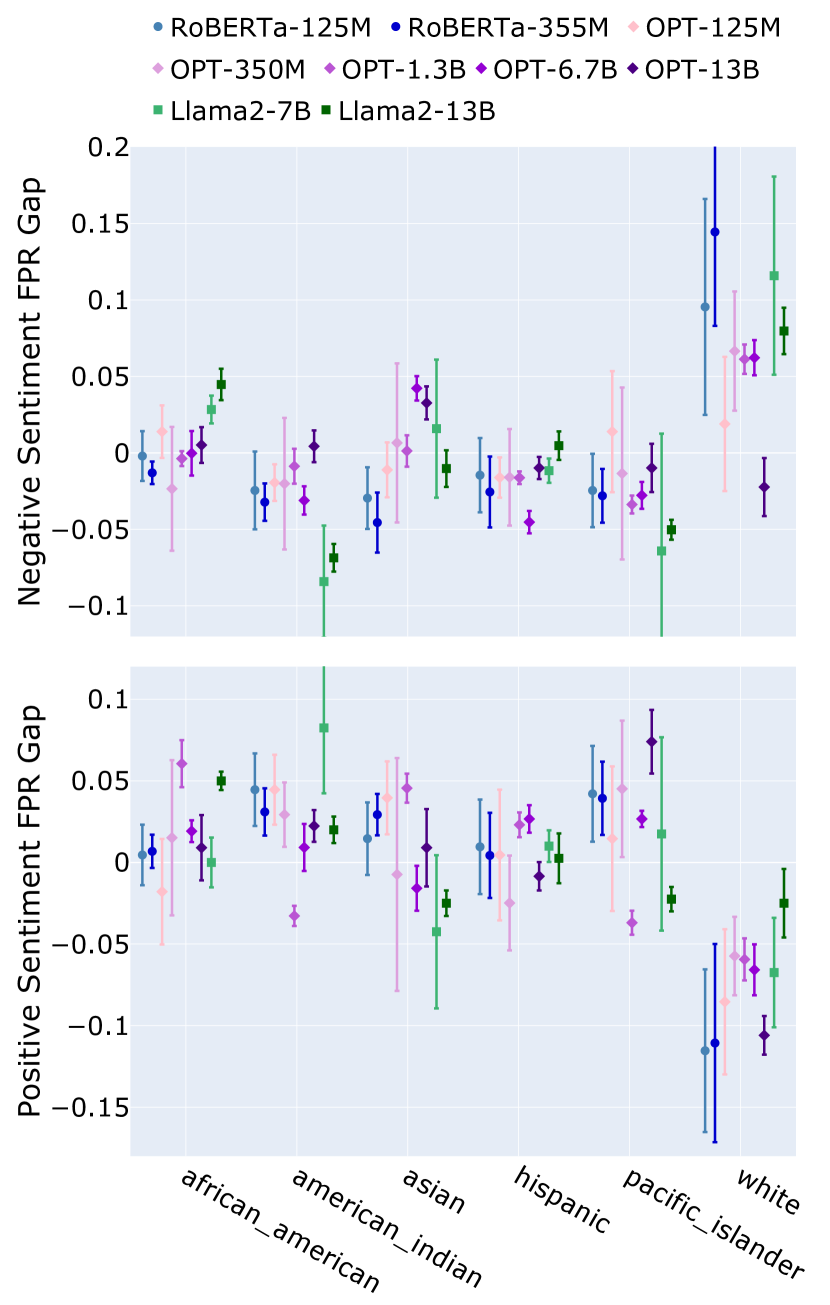
Reevaluating Bias Detection in Language Models: The Role of Implicit Norm
Farnaz Kohankhaki, Jacob-Junqi Tian, David Emerson, Laleh Seyyed-Kalantari, Faiza Khan Khattak
0
0
Large language models (LLMs), trained on vast datasets, can carry biases that manifest in various forms, from overt discrimination to implicit stereotypes. One facet of bias is performance disparities in LLMs, often harming underprivileged groups, such as racial minorities. A common approach to quantifying bias is to use template-based bias probes, which explicitly state group membership (e.g. White) and evaluate if the outcome of a task, sentiment analysis for instance, is invariant to the change of group membership (e.g. change White race to Black). This approach is widely used in bias quantification. However, in this work, we find evidence of an unexpectedly overlooked consequence of using template-based probes for LLM bias quantification. We find that in doing so, text examples associated with White ethnicities appear to be classified as exhibiting negative sentiment at elevated rates. We hypothesize that the scenario arises artificially through a mismatch between the pre-training text of LLMs and the templates used to measure bias through reporting bias, unstated norms that imply group membership without explicit statement. Our finding highlights the potential misleading impact of varying group membership through explicit mention in bias quantification
4/9/2024