GLIMS: Attention-Guided Lightweight Multi-Scale Hybrid Network for Volumetric Semantic Segmentation
2404.17854
0
0
Abstract
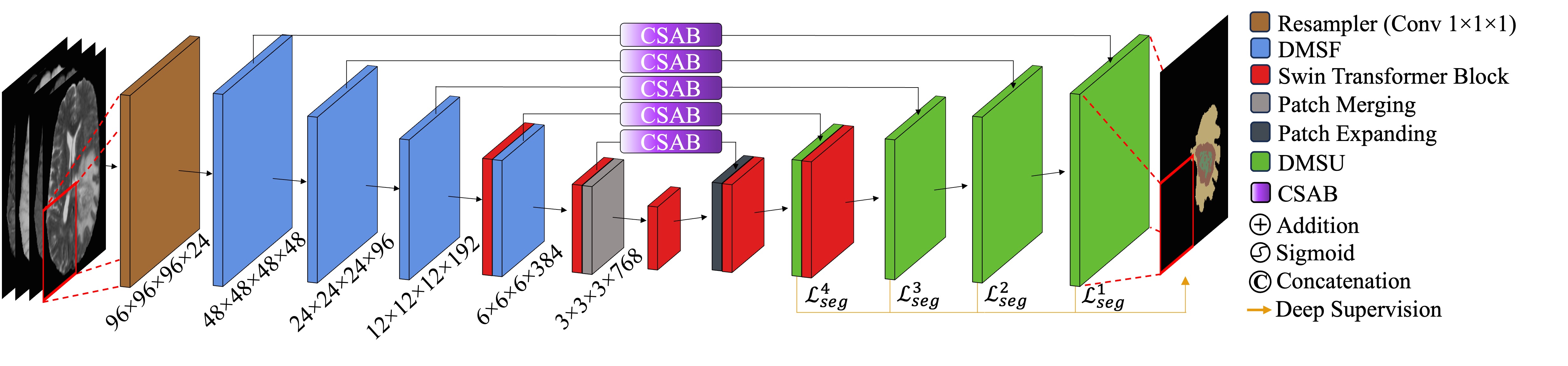
Convolutional Neural Networks (CNNs) have become widely adopted for medical image segmentation tasks, demonstrating promising performance. However, the inherent inductive biases in convolutional architectures limit their ability to model long-range dependencies and spatial correlations. While recent transformer-based architectures address these limitations by leveraging self-attention mechanisms to encode long-range dependencies and learn expressive representations, they often struggle to extract low-level features and are highly dependent on data availability. This motivated us for the development of GLIMS, a data-efficient attention-guided hybrid volumetric segmentation network. GLIMS utilizes Dilated Feature Aggregator Convolutional Blocks (DACB) to capture local-global feature correlations efficiently. Furthermore, the incorporated Swin Transformer-based bottleneck bridges the local and global features to improve the robustness of the model. Additionally, GLIMS employs an attention-guided segmentation approach through Channel and Spatial-Wise Attention Blocks (CSAB) to localize expressive features for fine-grained border segmentation. Quantitative and qualitative results on glioblastoma and multi-organ CT segmentation tasks demonstrate GLIMS' effectiveness in terms of complexity and accuracy. GLIMS demonstrated outstanding performance on BraTS2021 and BTCV datasets, surpassing the performance of Swin UNETR. Notably, GLIMS achieved this high performance with a significantly reduced number of trainable parameters. Specifically, GLIMS has 47.16M trainable parameters and 72.30G FLOPs, while Swin UNETR has 61.98M trainable parameters and 394.84G FLOPs. The code is publicly available on https://github.com/yaziciz/GLIMS.
Create account to get full access
Overview
- This paper presents GLIMS, an attention-guided lightweight multi-scale hybrid network for volumetric semantic segmentation.
- GLIMS combines the strengths of different architectures, including Rethinking Attention-Gated Hybrid Dual Pyramid Transformer, MaxViT-UNet: Multi-Axis Attention for Medical Image, AMUNet: Multi-Scale Attention Map Merging for Remote, LATUP-Net: Lightweight 3D Attention U-Net, and LHU-Net: Light Hybrid U-Net for Cost.
- The authors aim to create a lightweight, efficient, and high-performance model for volumetric semantic segmentation tasks.
Plain English Explanation
The paper presents a new deep learning model called GLIMS, which stands for Attention-Guided Lightweight Multi-Scale Hybrid Network. This model is designed for the task of volumetric semantic segmentation, which involves dividing 3D images or data (such as medical scans) into different meaningful regions or objects.
The key idea behind GLIMS is to combine the strengths of various existing models, including those that use attention mechanisms, multi-scale processing, and hybrid architectures. By leveraging these different approaches, the researchers aim to create a model that is lightweight (meaning it has fewer parameters and is computationally efficient), yet still highly accurate and versatile for volumetric segmentation tasks.
The paper explores how the different components of GLIMS, such as the attention guidance, multi-scale feature extraction, and hybrid design, work together to achieve high performance. The authors also compare GLIMS to other state-of-the-art models on various datasets and tasks, demonstrating its effectiveness and efficiency.
Technical Explanation
The GLIMS model proposed in this paper is a lightweight, attention-guided, multi-scale hybrid network for volumetric semantic segmentation. It draws inspiration from several recent advancements in deep learning architectures, including Rethinking Attention-Gated Hybrid Dual Pyramid Transformer, MaxViT-UNet: Multi-Axis Attention for Medical Image, AMUNet: Multi-Scale Attention Map Merging for Remote, LATUP-Net: Lightweight 3D Attention U-Net, and LHU-Net: Light Hybrid U-Net for Cost.
The key components of the GLIMS architecture include:
-
Attention-Guided Feature Extraction: GLIMS employs attention mechanisms to selectively focus on the most informative features at different scales, guiding the segmentation process.
-
Multi-Scale Feature Fusion: The model extracts features at multiple scales and effectively combines them to capture both local and global context.
-
Hybrid Decoder: GLIMS uses a hybrid decoder that combines the strengths of both convolutional and transformer-based approaches to achieve efficient and accurate segmentation.
The authors thoroughly evaluate GLIMS on various volumetric segmentation datasets, demonstrating its superior performance compared to other state-of-the-art models in terms of accuracy, inference speed, and model complexity. The results showcase the effectiveness of the proposed attention-guided, multi-scale hybrid architecture in addressing the challenges of volumetric semantic segmentation.
Critical Analysis
The authors of the GLIMS paper have made a commendable effort in designing a lightweight, yet high-performing model for volumetric semantic segmentation. By integrating attention mechanisms, multi-scale feature fusion, and a hybrid decoder, they have created a versatile architecture that appears to outperform existing models on several benchmarks.
One potential limitation of the paper is the lack of a more in-depth analysis of the individual components and their contributions to the overall performance. While the authors provide a high-level description of the architecture, a deeper dive into the design choices and the rationale behind them could have strengthened the technical explanation.
Additionally, the paper does not discuss the potential limitations or trade-offs of the GLIMS model. For example, it would have been valuable to understand the scenarios where the model may struggle, such as dealing with complex or highly diverse volumetric data, or the computational and memory requirements for real-world deployment.
Nonetheless, the GLIMS model presents a promising direction in the field of volumetric semantic segmentation, and the authors' attention to efficiency and lightweight design is a commendable approach. As with any research, it would be beneficial for the community to further explore the model's performance, robustness, and potential applications in various real-world scenarios.
Conclusion
The GLIMS paper introduces a novel attention-guided, lightweight, and multi-scale hybrid network for volumetric semantic segmentation. By combining the strengths of various deep learning architectures, the authors have developed a highly efficient and accurate model that outperforms existing state-of-the-art approaches on multiple benchmarks.
The key innovations of GLIMS, such as the attention-guided feature extraction, multi-scale feature fusion, and hybrid decoder, demonstrate the potential of leveraging diverse techniques to create advanced segmentation models. The lightweight and efficient nature of GLIMS also make it a promising candidate for practical real-world applications, where computational resources and inference speed are crucial factors.
While the paper provides a solid technical foundation, further research and analysis could still be valuable to fully understand the model's capabilities, limitations, and potential areas for improvement. Nonetheless, the GLIMS model represents a significant step forward in the field of volumetric semantic segmentation and showcases the continued advancements in deep learning-based computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ViG: Linear-complexity Visual Sequence Learning with Gated Linear Attention
Bencheng Liao, Xinggang Wang, Lianghui Zhu, Qian Zhang, Chang Huang
0
0
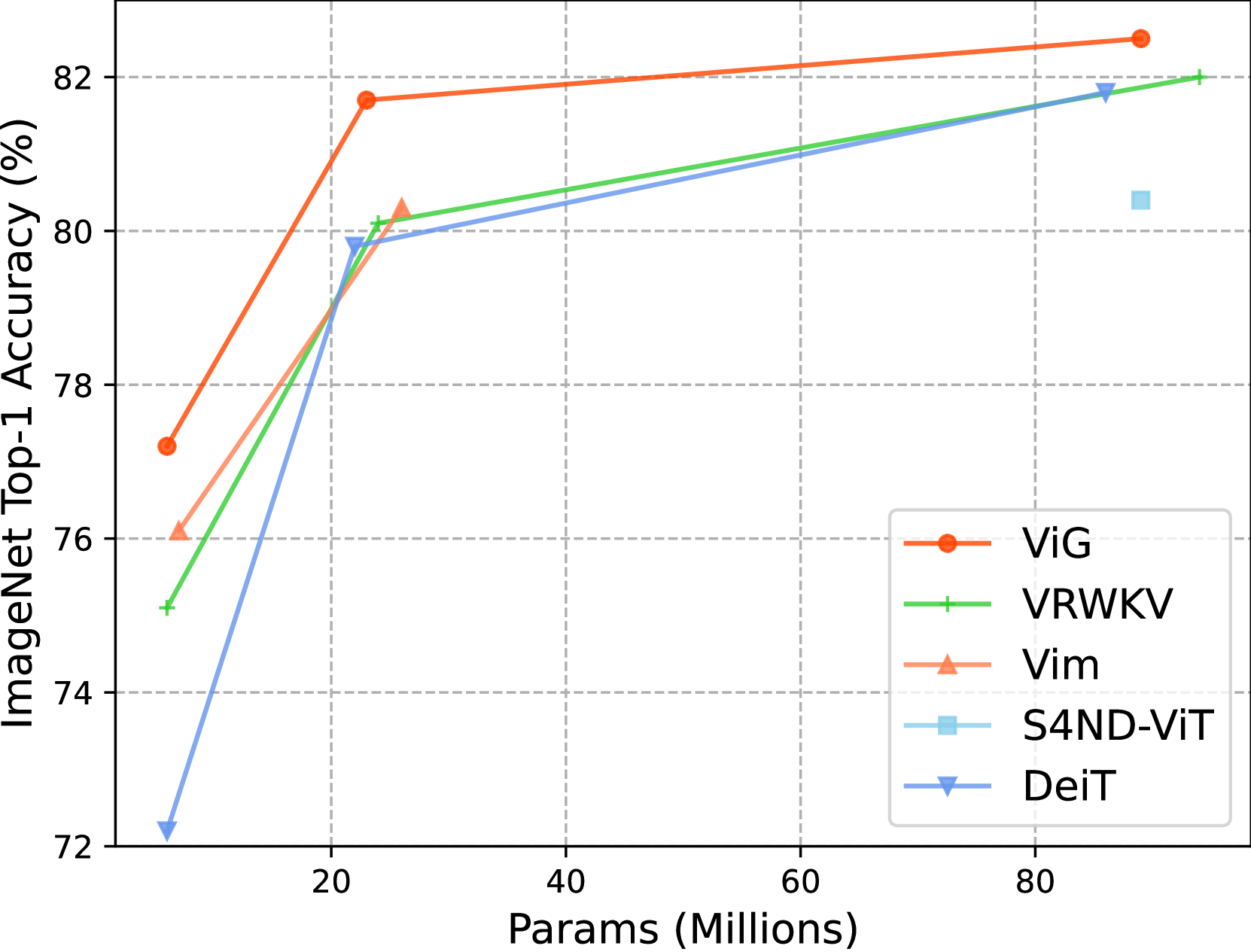
Recently, linear complexity sequence modeling networks have achieved modeling capabilities similar to Vision Transformers on a variety of computer vision tasks, while using fewer FLOPs and less memory. However, their advantage in terms of actual runtime speed is not significant. To address this issue, we introduce Gated Linear Attention (GLA) for vision, leveraging its superior hardware-awareness and efficiency. We propose direction-wise gating to capture 1D global context through bidirectional modeling and a 2D gating locality injection to adaptively inject 2D local details into 1D global context. Our hardware-aware implementation further merges forward and backward scanning into a single kernel, enhancing parallelism and reducing memory cost and latency. The proposed model, ViG, offers a favorable trade-off in accuracy, parameters, and FLOPs on ImageNet and downstream tasks, outperforming popular Transformer and CNN-based models. Notably, ViG-S matches DeiT-B's accuracy while using only 27% of the parameters and 20% of the FLOPs, running 2$times$ faster on $224times224$ images. At $1024times1024$ resolution, ViG-T uses 5.2$times$ fewer FLOPs, saves 90% GPU memory, runs 4.8$times$ faster, and achieves 20.7% higher top-1 accuracy than DeiT-T. These results position ViG as an efficient and scalable solution for visual representation learning. Code is available at url{https://github.com/hustvl/ViG}.
5/30/2024
👨🏫
Novel Approach to Intrusion Detection: Introducing GAN-MSCNN-BILSTM with LIME Predictions
Asmaa Benchama, Khalid Zebbara
0
0
This paper introduces an innovative intrusion detection system that harnesses Generative Adversarial Networks (GANs), Multi-Scale Convolutional Neural Networks (MSCNNs), and Bidirectional Long Short-Term Memory (BiLSTM) networks, supplemented by Local Interpretable Model-Agnostic Explanations (LIME) for interpretability. Employing a GAN, the system generates realistic network traffic data, encompassing both normal and attack patterns. This synthesized data is then fed into an MSCNN-BiLSTM architecture for intrusion detection. The MSCNN layer extracts features from the network traffic data at different scales, while the BiLSTM layer captures temporal dependencies within the traffic sequences. Integration of LIME allows for explaining the model's decisions. Evaluation on the Hogzilla dataset, a standard benchmark, showcases an impressive accuracy of 99.16% for multi-class classification and 99.10% for binary classification, while ensuring interpretability through LIME. This fusion of deep learning and interpretability presents a promising avenue for enhancing intrusion detection systems by improving transparency and decision support in network security.
6/11/2024
GLIMPSE: Generalized Local Imaging with MLPs
AmirEhsan Khorashadizadeh, Valentin Debarnot, Tianlin Liu, Ivan Dokmani'c
0
0
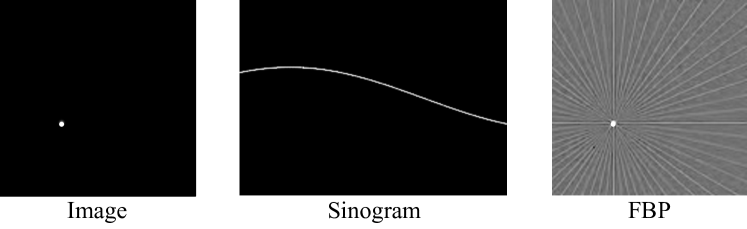
Deep learning is the current de facto state of the art in tomographic imaging. A common approach is to feed the result of a simple inversion, for example the backprojection, to a convolutional neural network (CNN) which then computes the reconstruction. Despite strong results on 'in-distribution' test data similar to the training data, backprojection from sparse-view data delocalizes singularities, so these approaches require a large receptive field to perform well. As a consequence, they overfit to certain global structures which leads to poor generalization on out-of-distribution (OOD) samples. Moreover, their memory complexity and training time scale unfavorably with image resolution, making them impractical for application at realistic clinical resolutions, especially in 3D: a standard U-Net requires a substantial 140GB of memory and 2600 seconds per epoch on a research-grade GPU when training on 1024x1024 images. In this paper, we introduce GLIMPSE, a local processing neural network for computed tomography which reconstructs a pixel value by feeding only the measurements associated with the neighborhood of the pixel to a simple MLP. While achieving comparable or better performance with successful CNNs like the U-Net on in-distribution test data, GLIMPSE significantly outperforms them on OOD samples while maintaining a memory footprint almost independent of image resolution; 5GB memory suffices to train on 1024x1024 images. Further, we built GLIMPSE to be fully differentiable, which enables feats such as recovery of accurate projection angles if they are out of calibration.
6/21/2024
👀
Are Vision xLSTM Embedded UNet More Reliable in Medical 3D Image Segmentation?
Pallabi Dutta, Soham Bose, Swalpa Kumar Roy, Sushmita Mitra
0
0
The advancement of developing efficient medical image segmentation has evolved from initial dependence on Convolutional Neural Networks (CNNs) to the present investigation of hybrid models that combine CNNs with Vision Transformers. Furthermore, there is an increasing focus on creating architectures that are both high-performing in medical image segmentation tasks and computationally efficient to be deployed on systems with limited resources. Although transformers have several advantages like capturing global dependencies in the input data, they face challenges such as high computational and memory complexity. This paper investigates the integration of CNNs and Vision Extended Long Short-Term Memory (Vision-xLSTM) models by introducing a novel approach called UVixLSTM. The Vision-xLSTM blocks captures temporal and global relationships within the patches extracted from the CNN feature maps. The convolutional feature reconstruction path upsamples the output volume from the Vision-xLSTM blocks to produce the segmentation output. Our primary objective is to propose that Vision-xLSTM forms a reliable backbone for medical image segmentation tasks, offering excellent segmentation performance and reduced computational complexity. UVixLSTM exhibits superior performance compared to state-of-the-art networks on the publicly-available Synapse dataset. Code is available at: https://github.com/duttapallabi2907/UVixLSTM
6/26/2024